







开发与运维 日志服务(SLS)
 首页
首页








日志服务(Log Service,简称 SLS)是针对日志类数据的一站式服务,在阿里巴巴集团经历大量大数据场景锤炼而成。您无需开发就能快捷完成日志数据采集、消费、投递以及查询分析等功能,提升运维、运营效率,建立 DT 时代海量日志处理能力。
日志服务学习路径
日志服务学习路径图为您推荐热门功能的操作指引文档,帮助您快速了解日志服务产品。视频与文档结合,全方位提升您的产品使用及文档阅读体验。
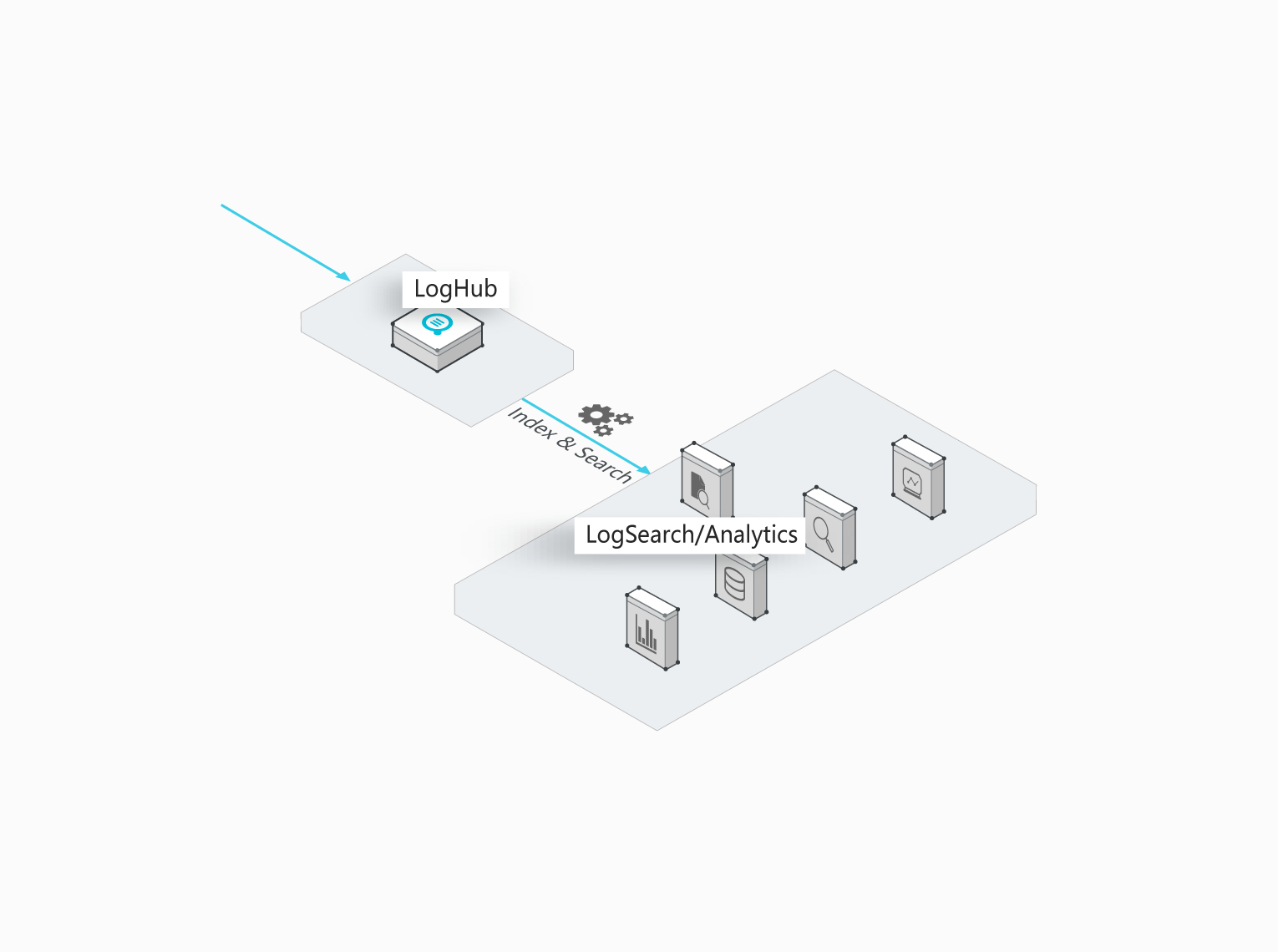
实时采集与消费(LogHub)
功能:
- 通过ECS、容器、移动端、开源软件、JS等接入实时日志数据(例如Metric、Event、BinLog、TextLog、Click等)。
- 提供实时消费接口,与实时计算及服务对接。
用途:数据清洗(ETL)、流计算(Stream Compute)、监控与报警、 机器学习与迭代计算。

查询与实时分析(Search/Analytics)
实时索引、查询分析数据。
- 查询:关键词、模糊、上下文、范围。
- 统计:SQL聚合等丰富查询手段。
- 可视化:Dashboard + 报表功能。
- 对接:Grafana、JDBC/SQL92。
用途:DevOps/线上运维,日志实时数据分析,安全诊断与分析,运营与客服系统。

投递数仓(LogShipper)
稳定可靠的日志投递。将日志中枢数据投递至存储类服务进行存储。支持压缩、自定义Partition、以及行列等各种存储方式。
用途:数据仓库 + 数据分析、审计、推荐系统与用户画像。

产品架构
日志服务的架构如下图所示:

Logtail
帮助您快速收集日志的Agent。其特点如下所示:
- 基于日志文件、无侵入式的收集日志
- 只读取文件。
- 日志文件无侵入。
- 安全、可靠
- 支持文件轮转不丢失数据。
- 支持本地缓存。
- 网络异常重试。
- 方便管理
- Web端操作。
- 可视化配置。
- 完善的自我保护
- 实时监控进程CPU、内存消耗。
- 限制使用上限。
前端服务器
采用LVS + Nginx构建的前端机器。其特点如下所示:
- HTTP、REST协议
- 水平扩展
- 流量上涨时可快速提高处理能力。
- 支持增加前端机。
- 高吞吐、低延时
- 纯异步处理,单个请求异常不会影响其他请求。
- 内部采用专门针对日志的Lz4压缩,提高单机处理能力,降低网络带宽。
后端服务器
后端是分布式的进程,部署在多个机器上,完成实时对Logstore数据的持久化、索引、查询以及投递至MaxCompute。整体后端服务的特点如下所示:
- 数据高安全性 :
- 您写入的每条日志,都会被保存3份。
- 任意磁盘损坏、机器宕机情况下,数据自动复制修复。
- 稳定服务:
- 进程崩溃和机器宕机时,Logstore会自动迁移。
- 自动负载均衡,确保无单机热点。
- 严格的Quota限制,防止单个用户行为异常对其他用户产生影响。
- 水平扩展:
- 以分区(Shard)为单位进行水平扩展。
- 用户可以按需动态增加分区来增加吞吐量。
功能优势
全托管服务
- 应用性强,5分钟即可接入服务进行使用,Agent支持任意网络下数据采集。
- LogHub覆盖Kafka 100%功能,提供完整监控、报警等功能数据,并支持弹性伸缩(可支持PB/Day规模),使用成本为自建50%以下。
- LogSearch/Analytics 提供快速查询、仪表盘和报警功能,使用成本为自建 20%以下。
- 提供超过30种接入方式,与云产品 (OSS/E-MapReduce/MaxCompute/Table Store/MNS/CDN/ARMS等)、开源软件(Storm、Spark)无缝对接。
生态丰富
- LogHub 支持30多个采集端,包括Logstash、Fluent等,无论是嵌入式设备、网页、服务器、程序等都能轻松接入。在消费端,支持与Storm、Spark Streaming、云监控等对接。
- LogShipper 支持丰富数据格式(TextFile、SequenceFile、Parquet等),支持自定义Partition,数据可以直接被Presto、Hive、Spark、Hadoop、E-MapReduce、MaxCompute、HybridDB、DLA等处理。
- LogSearch/Analytics 查询分析语法完整、兼容SQL92、支持JDBC协议与Grafana对接。
实时性强
- LogHub:写入即可消费;Logtail(采集Agent)实时采集传输,1秒内到服务端(99.9%情况)。
- LogSearch/Analytics:写入即可查询分析,在多个查询条件下1秒可查询10亿级数据,多个聚合条件下1秒可分析1亿级数据。
完整API/SDK
- 轻松支持自定义管理及二次开发。
- 所有功能均可通过API/SDK实现,提供多种语言SDK,可轻松管理服务和百万级设备。
成本优势
成本优势
日志服务产品在日志处理的三种场景下具有以下成本优势:
- LogHub:
- 与购买云主机 + 云磁盘搭建 Kafka 相比,对于 98% 场景下用户价格有优势。对小型网站而言,成本为 kafka 的30% 以下。
- 提供 RESTful API,可以直接针对移动设备提供数据收集功能,节省了日志收集网关服务器的费用。
- 免运维,随时随地弹性扩容使用。
- LogShipper:
- 无需任何代码/机器资源,灵活配置与丰富监控数据。
- 规模线性扩展 (PB级/Day),功能当前免费。
- LogSearch/Analytics:
- 与购买云主机 + 自建 ELK 相比,成本为自建的 15% 以下,并且查询能力与数据规模有极大提升。与日志管理软件相比,能无缝支持各种流行流计算 + 离线计算框架,日志流动畅通无阻。
成本对比
以下是在计费模型下,日志服务功能与自建方案的对比,仅供参考。
日志中枢(LogHub vs Kafka)

日志存储与查询引擎

应用场景
日志服务的典型应用场景包括:数据采集与消费、数据清洗与流计算 (ETL/Stream Processing)、数据仓库对接(Data Warehouse)、日志实时查询与分析。
数据采集与消费
通过日志服务LogHub功能,可以大规模低成本接入各种实时日志数据(包括Metric、Event、BinLog、TextLog、Click等)。
方案优势:
- 使用便捷:提供30+实时数据采集方式,让您快速搭建平台;强大配置管理能力,减轻运维负担。
- 弹性伸缩:无论是流量高峰还是业务增长都能轻松应对。

数据清洗与流计算 (ETL/Stream Processing)
日志中枢(LogHub)支持与各种实时计算及服务对接,并提供完整的进度监控,报警等功能,并可以根据SDK/API实现自定义消费。
- 操作便捷:提供丰富SDK以及编程框架,与各流计算引擎无缝对接。
- 监控报警:提供丰富监控数据,以及延迟报警机制。
- 弹性伸缩:PB级弹性能力,0延迟。

数据仓库对接(Data Warehouse)
日志投递(LogShipper)功能可以将日志中枢(LogHub)中数据投递至存储类服务,过程支持压缩、自定义Partition、以及行列等各种存储格式。
- 海量数据:对数据量不设上限。
- 种类丰富:支持行、列、TextFile等各种存储格式。
- 配置灵活:支持用户自定义Partition等配置。

日志实时查询与分析
实时查询分析(LogAnalytics)可以实时索引LogHub中数据,提供关键词、模糊、上下文、范围、SQL聚合等丰富查询手段。
- 实时性强:写入后即可查询。
- 海量低成本:支持PB/Day索引能力,成本为自建方案15%。
- 分析能力强:支持多种查询手段,及SQL进行聚合分析,并提供可视化及报警功能。

产品推荐







