云智慧可观测性监控平台
 首页
首页 新一代IT架构下系统运行状态数据化-可观测性(Observability)
新一代IT架构下系统运行状态数据化-可观测性(Observability)新一代IT架构下的可观测性必须具备以下特性:
面向全栈-上下四方:不同于传统的观测工具提供了一个/组具有较长生存期的固定目标的信息视图。云原生技术架构下的可观测性工具相对而言是需要同时查看各个地方的所有内容,包括横向的联通与纵向的贯穿,即便观测对象的生命周期只有一次业务调用过程这么短。
面向不同时间切片-古往今来:支持对IT架构“过去”状态的回溯、“当前”状态的查看/分析,以及使用AI预测未来可能发生的事件。
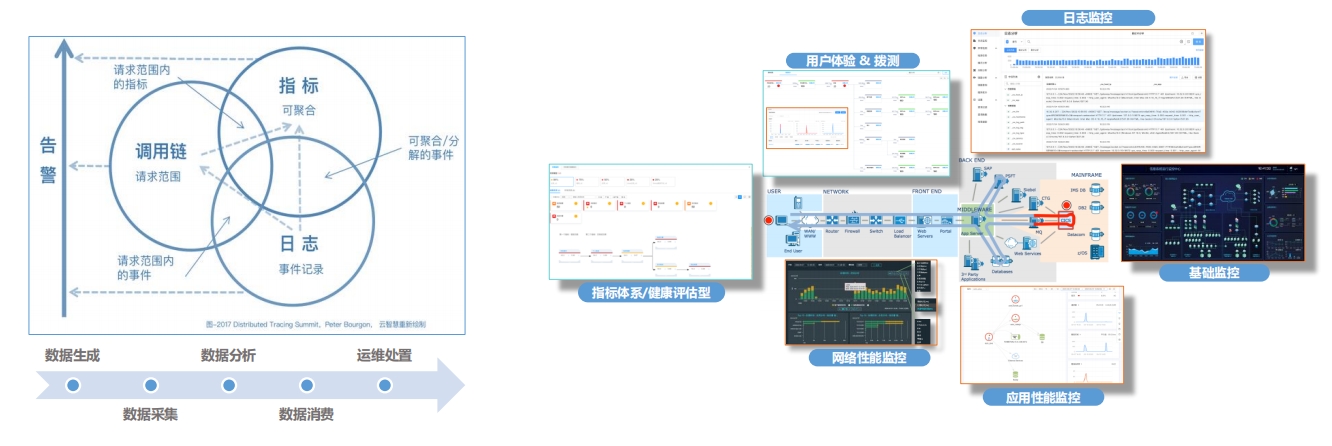
监控 VS.可观测性“可观测性”并非是“监控”的“马甲”,也非
其名词升级,二者之间是互补关系,但又存在明
确的差异。

可观测性能力模型列式存储
流批一体、双流勾兑、数据丰富
低代码数据管道
大数据/AI/ML
关联指标,进行数据聚合
构建业务导向的健康度评价模型
指标体系应用和健康度视图
全链路追踪
数据安全、合规管理
模式识别、转化指标
基于模式的异常检测算法,预警及告警
对接Kubernetes实现对云原生环境的监控
混合云、多云的统一监控
测数据
对接OpenTelemetry
对接第三方工具
全量、秒级数据采集
模式识别/异常检测、根因分析与推荐、告警降噪等算法
快速支撑数据接入、新算法工程化、
算法能力发布
种方式,构建复杂IT环境下的调用链
实时数据关联&查看能力
基于AI的告警智能降噪
标准化事件处理流程
丰富、开箱即用、可编排的自动化处置能力
平台架构
全生态监控历经十多年的积累和沉淀,内置数百种采集器以及众多主流厂家的常见设备,支持包括国产信创设备在内的上万个指
标监测,对IT资源、动环、物联网等设施进行分布式采集,实现100%全覆盖监控。

指标和日志分析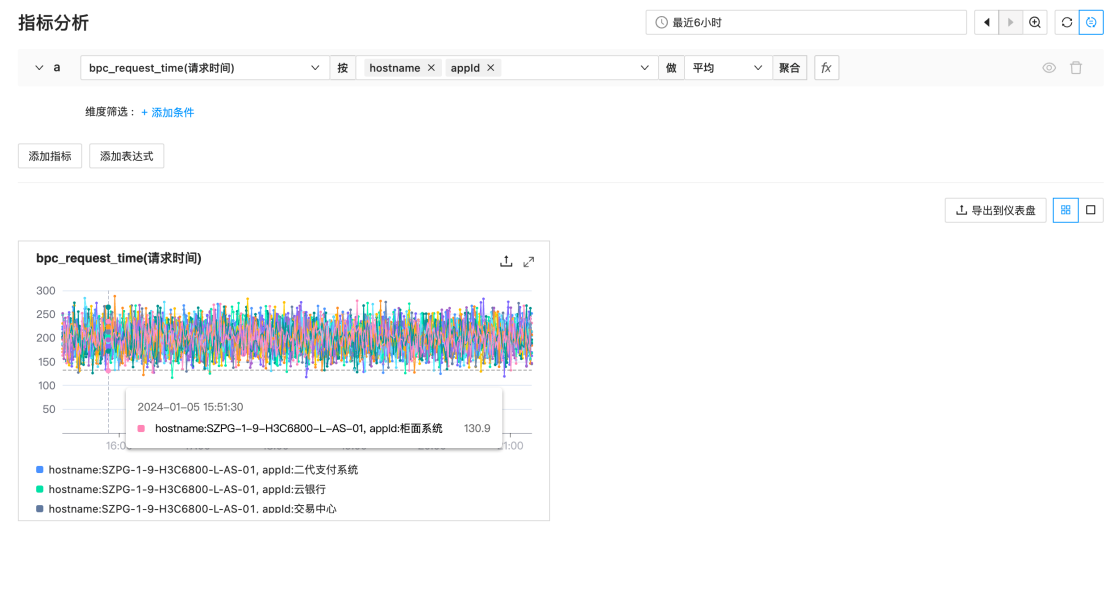
和指标信息。指标分析支持在时间、维度和指标不同的维度对多个指标进行对比分析。同时支持单位自动换算、指标分析导出仪表盘功能,并打通采控中心集成服务信息同步。

可观测的配置数据管理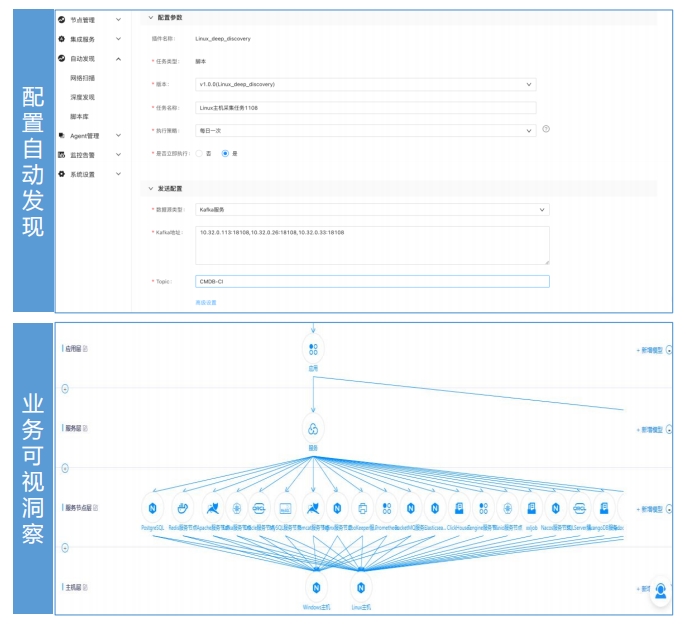
基于一体化采控Agent深度发现
调用链→指标:通过调用链的分析获得调用范围内的指标
指标,日志,调用链→告警:多个源头产生的告警
日志+调用链:一个调用周期内的事件
调用链+指标:一个调用周期内的指标
可观测的数据处理流程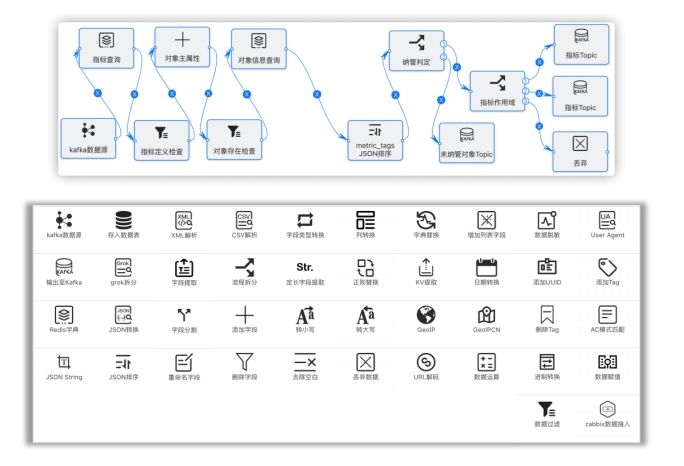

最大化扩展数据计算能力
运维数据的统一治理运维数据治理是在高层次上执行数据管理制度,
构建现实世界的IT系统在数字世界的抽象,为全栈可观测性提供可信赖的数据源。
AI算法赋能,智能分析,快速定位平台提供了强大算法能力为企业AIOps赋能,助力AIOps场景落地,减少问题发现和故障排查的时长(MTTR),提升检测的准确率,提升企业运维效率。
7大类共32种算法及72种开箱即用算法泛型全力支撑可观测平台核心场景。
算法中台提供了丰富的算法,开箱即用,能够支撑丰富的运维场景。

面向场景的监控与分析1. 统一监控
从底层动环到上层业务的全资源监控,整合业务数据、应用性能数据、运行数据等,构建统一监控能力。
2. 多维监控
通过健康度、指标、告警事件、调用关系、日志、关系等进行多维度监控,提供场景化以及智能化的异常监控。
3. 立体化分析
围绕业务构建横向调用和纵向依赖关系拓扑,联动多维监控数据,丰富监控和故障根因分析路径,助力故障根因定位。

统一告警与处置
新一代服务管理ITSM以ITIL4、ITSS为理论基础,以大数据和人工智能技术为支撑,为企业提供标准、高质量的IT服务。能够适应并支撑企业数字化转型中新的业务发展要求与全新的IT架构,为企业建立良好的IT运维环境,帮助企业提高IT效率、提升用户满意度,最终实现IT服务提供者与使用者的价值共创。满足可观测自动化运维全场景服务与流程支持。

标准的服务与工单管理
APM应用性能分析平台
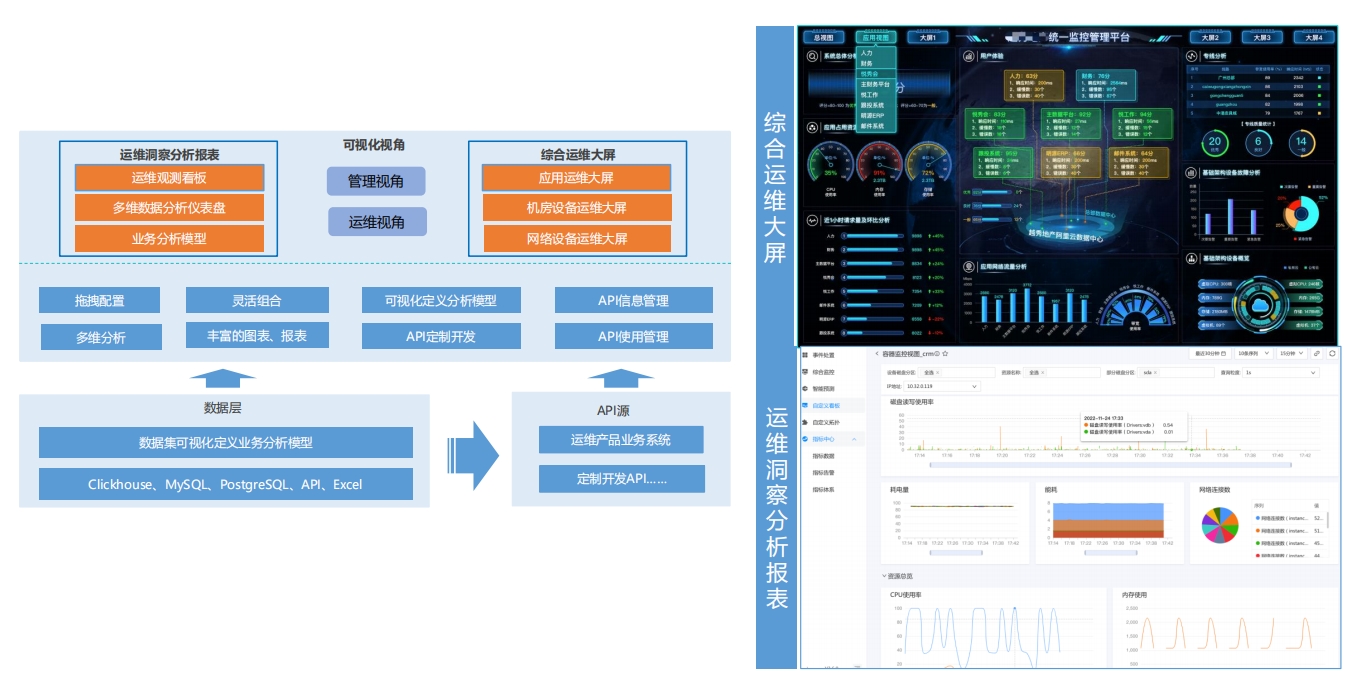
数据可视化,让数据不再沉睡1. 聚焦多类运维数据
综合客观性对运维工作的重新定义,聚焦指标、日志、调用链三类运维数据及告警数据。
2. 快速构建可视化大屏
提供丰富组件与应用模板、可利用模块快速拖拽式开发可视化大屏。
3. 自助式分析
根据业务关注指标及分析视角,灵活选择指标和维度构建多种图表报表。
业务系统全局监控面向运维工具众多、数据隔离、架构复杂导致的问题发现难、业务分析难、排查分析难的问题,基于业务系统视角,串
联多种运维数据,构建系统视角的监控,具备对故障的全链路故障追踪能力。且对于金融行业的交易、开户、委托等业
务场景提供链路级别的分析能力,有效的将网络、主机、数据库、应用(研发为主)、业务运维人员高效的组织在一起,
共同为业务负责。

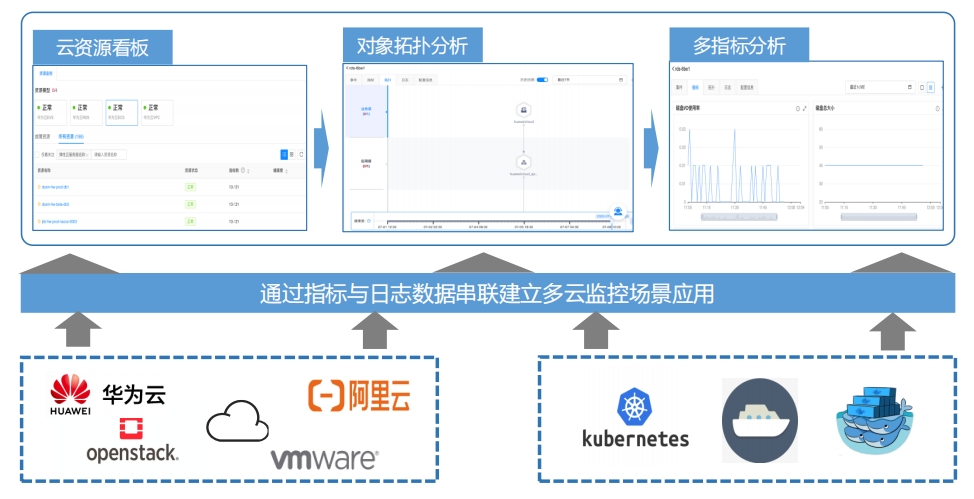
混合云监控场景聚焦企业云平台统一监控告警、云上应用的性能实时监控核心能力要求,通过形成云平台运维指标集,对云平台多租户进行监控,
实现快速发现和定位问题,确保业务连续性,提升整体管控与计划能力,凸显IT部门价值。
业务应用观测场景提供模拟用户的业务访问路径及操作,保障关键业务及API服务的持续可用性、关键数据的正确性,根据监测分析结果
提前发现业务访问异常及性能问题,掌握前端,透视后端,实现全业务链环节问题监控与分析。
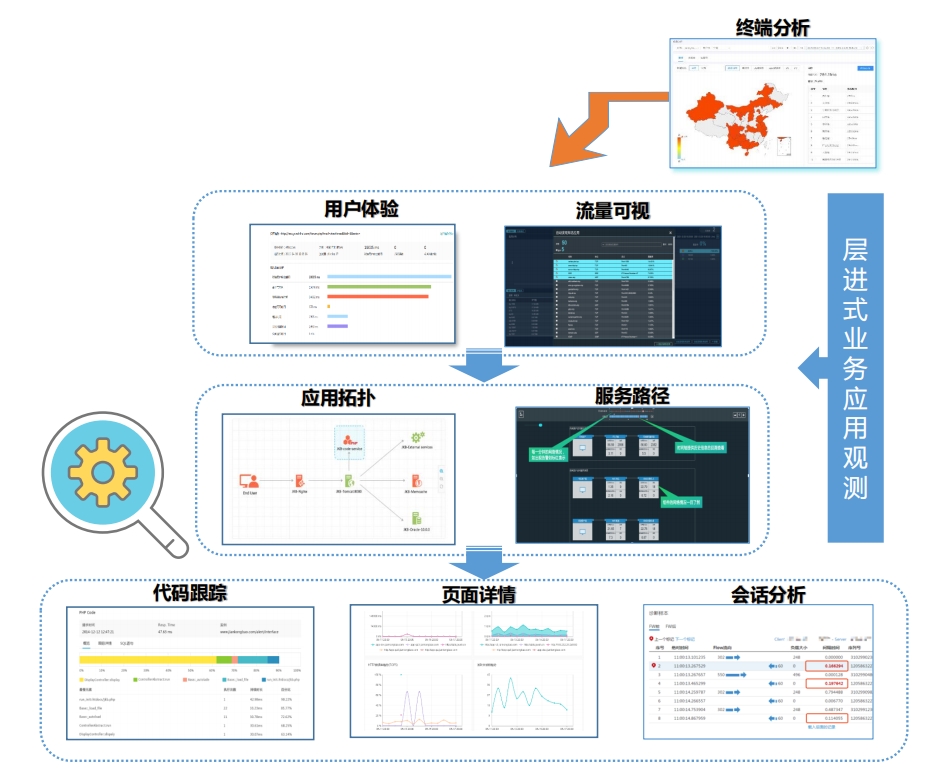
不同地区的可用性和响应时间等指标数据分析。
·结合应用前后端性能指标实时采集,提供全业务链路
问题监控与分析。
·实时关键链路网络质量量化监控,呈现广域网各分支
机构流量实时状态。
数据中心运维管理提供内容完整、流程标准的运维服务功能,实现了企业数据中心日常运维管理的流程化、标准化以及精细化,帮助企
业建立快速响应并适应企业业务环境及业务发展的基础设施运维模式。
平台以ITIL4为设计蓝本实现了数据中心运维工单及流程的规范化管理,在支持事件管理、问题管理、变更管理等功能
的同时提供值班管理、巡检管理、计划性运维、人员进出、设备进出等功能,并最终通过工单中心进行统一整合,使
得运维工作变得更加有效、轻松、快捷。
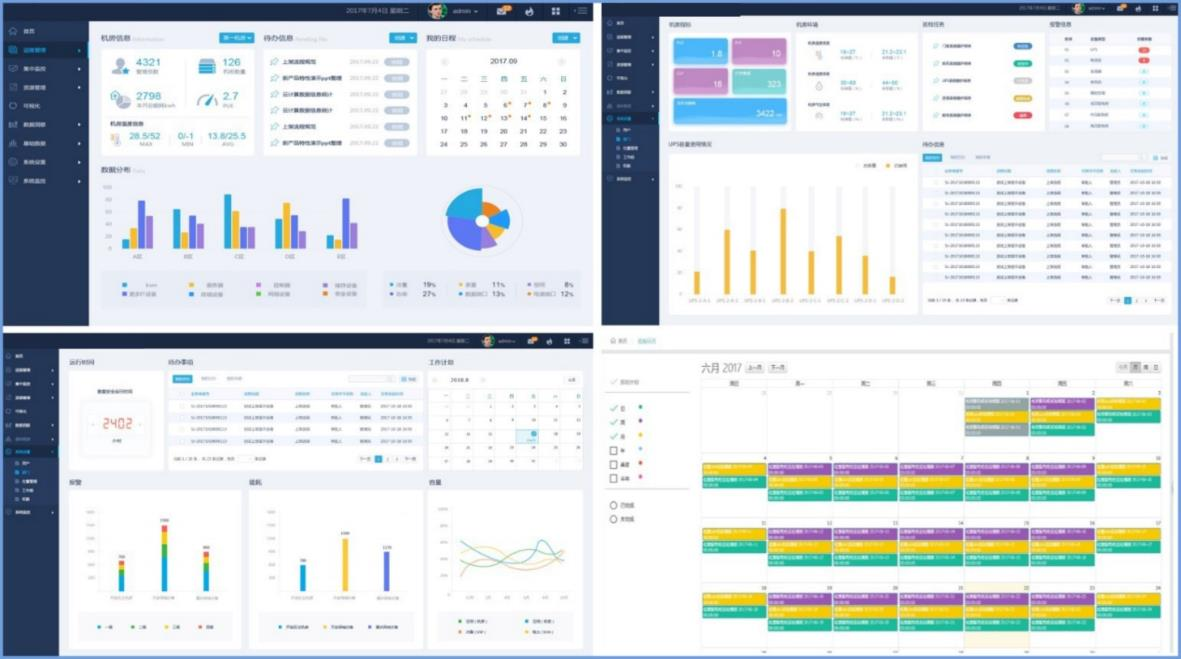
导者能够拥有统一的语言,通过统一的界面
面对挑战,理解新变化所带来的影响;并定
期进行数据的汇总与分析,提高SLA、规避
风险、提供可靠的决策依据。
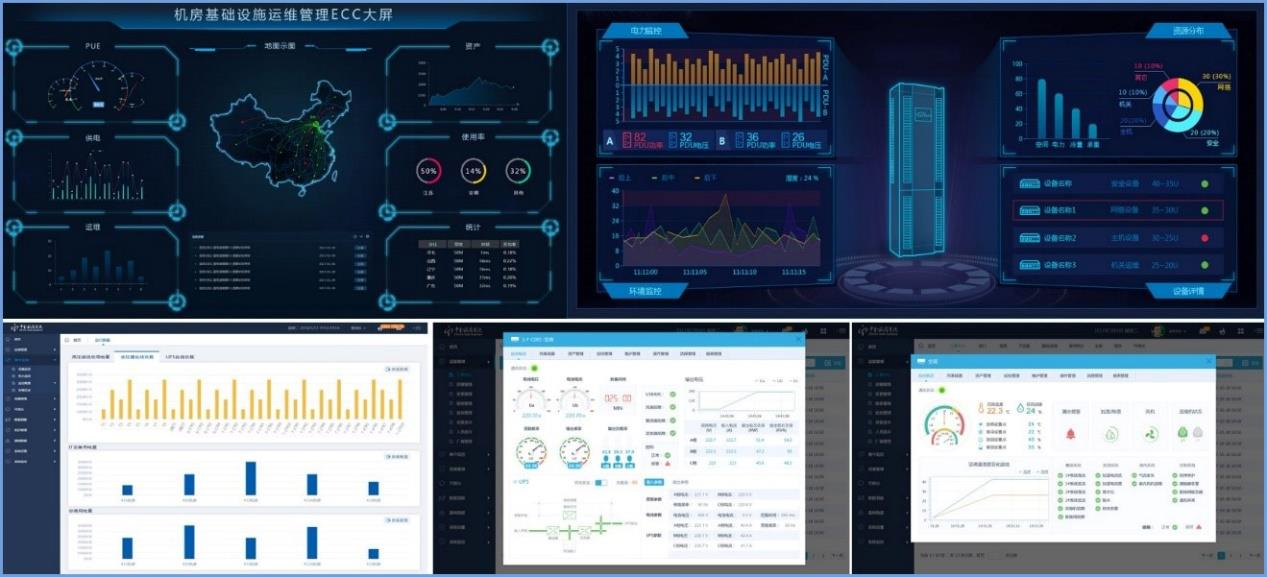
数据中心集中监控平台不仅支持跨设备、跨平台、跨系统的集中数据采集,而且能针对不同的监控对象设置相应的阈值,最终实现统一
告警与展示,让运维人员以一种更快速、更准确的方式发现被管理的组件所出现的故障,从而实现故障的快速定位与
修复,提升业务系统的可用性。
平台通过可视化、图表等人机交互界面,对数据中心内全部资源及子系统进行集中管理;利用数据处理引擎对数据进
行多维度的处理与分析,不断提升故障预警的时效性和准确性;通过友好的交互界面进行监控对象的统一管理、告警
的集中呈现、多维信息融合、问题快速溯源、故障影响判断,真正做到统一平台界面的综合类监控交付。
数据中心容量管理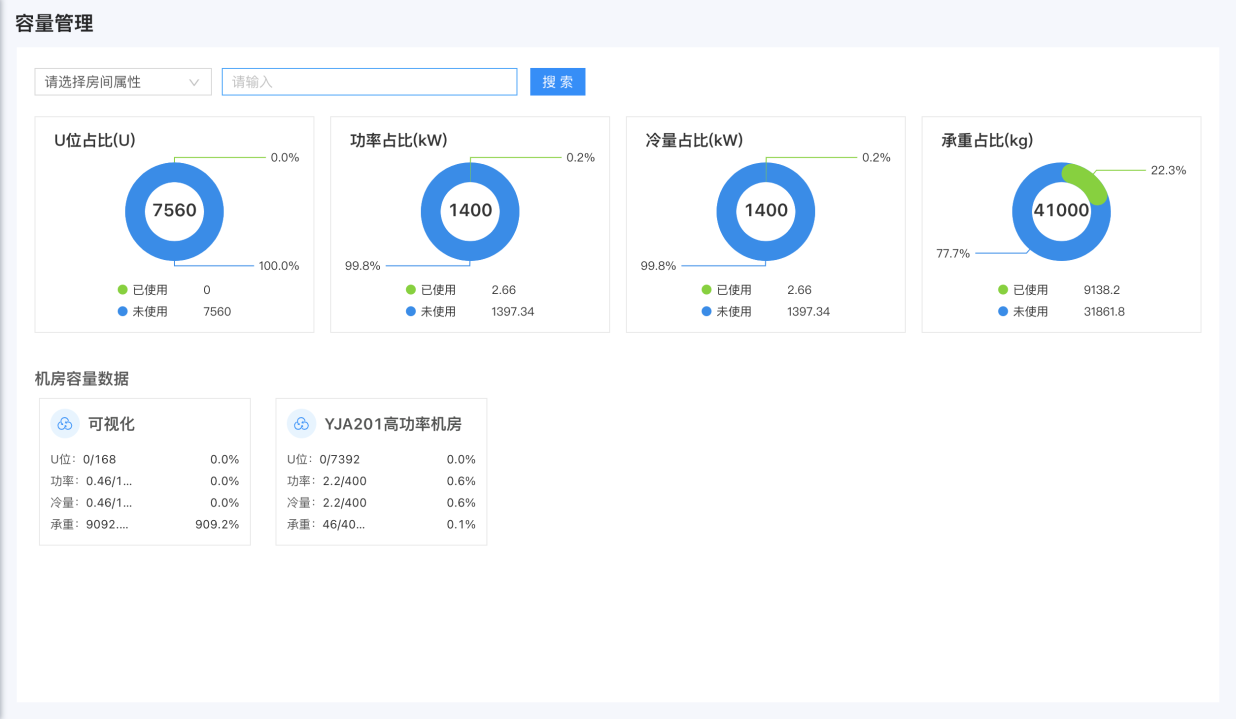
·平台通过对各类容量的测量与科学的计算,得到资源容量的准确数据,再通过严格执行运维管理、资产管理等流程来有效管控容量的变更,实现容量数据变更的自动动态更新。
·平台提供包含场地资源、空间、制冷、连接、称重等多个维度资源的检索、添加、删除、修改、导入、到处等操作,并通过多种图表进行多维度、多形式的展示,让运维人员实时掌握设计容量、额定容量、预留容量、使用容量、剩余容量的使用情况,从而实现合理的容量规划。
数据中心能耗管理
·平台对外部采集设备、设施进行数据整合,通过后台算法计算出数据中心实时的PUE、CLF、PLF、WUE等能耗指标;对采集的数据进行统计、分析,按设备类型、机房区域等方式自动计算电量及PUE等数据,形成趋势图。
·平台将能耗成本、能耗组成情况进行ECC大屏等多种形式的展现,同时可根据变化趋势进行及时的信息预判。
·平台结合多种数据采集方式和特定的算法模型,实现了企业全数据中心范围内的实时、历史各类能效数据(PUE、SUE、UUE、AUE等)的自动计算及展示,帮助客户分析效率损失的原因,协助客户从整体上改善效能。
数字孪生·平台支持3D可视化功能,该功能基于数字孪生和严肃游戏理念研发的,利用强大的可视化引擎,将多维度动态数据,融入到数据中心园区、楼宇、设备、设施、管路、桥架等实物3D呈现之中实现全元素三维可视化呈现。
·平台提供了强大的2D/3D可视化自动切换展现、自定义路线巡游、第一视角参观功能,并通过鼠标、键盘的简单操作即可实现数据的查询、检索、分类、定位等功能,极大改善了普通静态界面的单调、交互性差、操作和信息传递效率低、决策和响应速度慢等问题,让运维工作变得简单、直观、灵活、有效。

报告报表·平台提供以业务为中心的自助式分析工具,主要面向运维、数据分析师、业务人员,以问题为导向的探索分析和以结果为导向的数据可视化,让数据价值清晰可见。
·平台在数据源基础上定义上层数据集合,为应用分析提供数据模型。可根据分析目标,灵活选择合适的数据来源,并结合业务场景,可视化拖拽定义数据分析模型。

数据洞察可视化大屏平台能够对企业数据中心的资源使用情况以及健康状态进行实时监控,及时进行故障预警并帮助运维管理者进行问题
分析与定位,提高企业数据中心的稳定性和可用性。管理者可以通过可视化大屏直观了解数据中心的整体运行情况,
从而实现对企业数据中心的全面掌控。
AIOpsGPT特色
大模型下运维场景变革

运维知识库产品变革相似的原理,针对多文件的分析、生成总结、对比、合规性检查、分类等操作都可借助基于大模型的知识库实现。

大模型+知识库的核心问题及方案


大模型+知识库的核心问题及知识注入方案-信息安全问题依据语义对知识库现有数据进行切片、Word Embedding等操作,形成大语言模型能够理解、处理的数据形式。将数据信息与大语言模型进行结合,使得大模型能够学习、理解知识库里的信息,进一步针对用户提问进行回答,并且提供相应的资料链接。借助大语言模型的能力能够实现顺畅的自然语言交互,多轮对话,知识解析等能力。

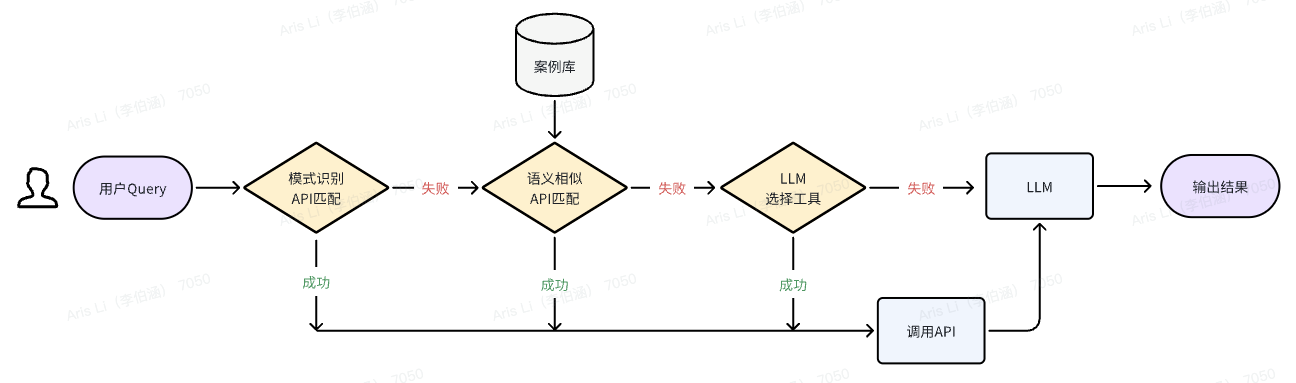
大模型+知识库的核心问题及方案-技术核心基于结构的信息提取技术

信息提取框架
基于结构的信息提取技术

库查询MECE拆分器
混合相似性搜索

颠覆日志、告警、进程、CMDB等运维产品形态
知其然,不知其所以然

知其然,知其所以然
智能日志分析能力
智能告警分析能力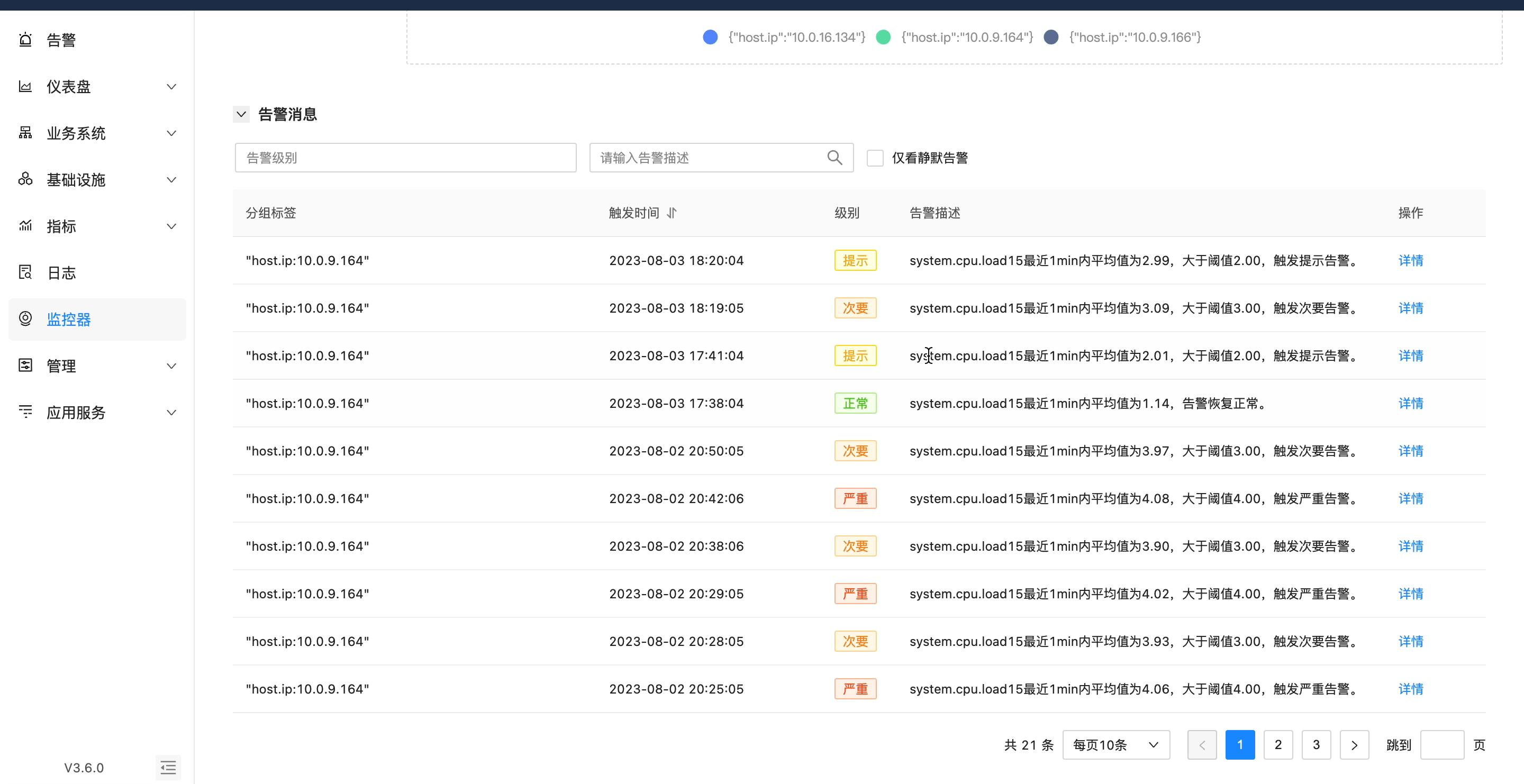
智能系统进程解析能力
中间件变量解析能力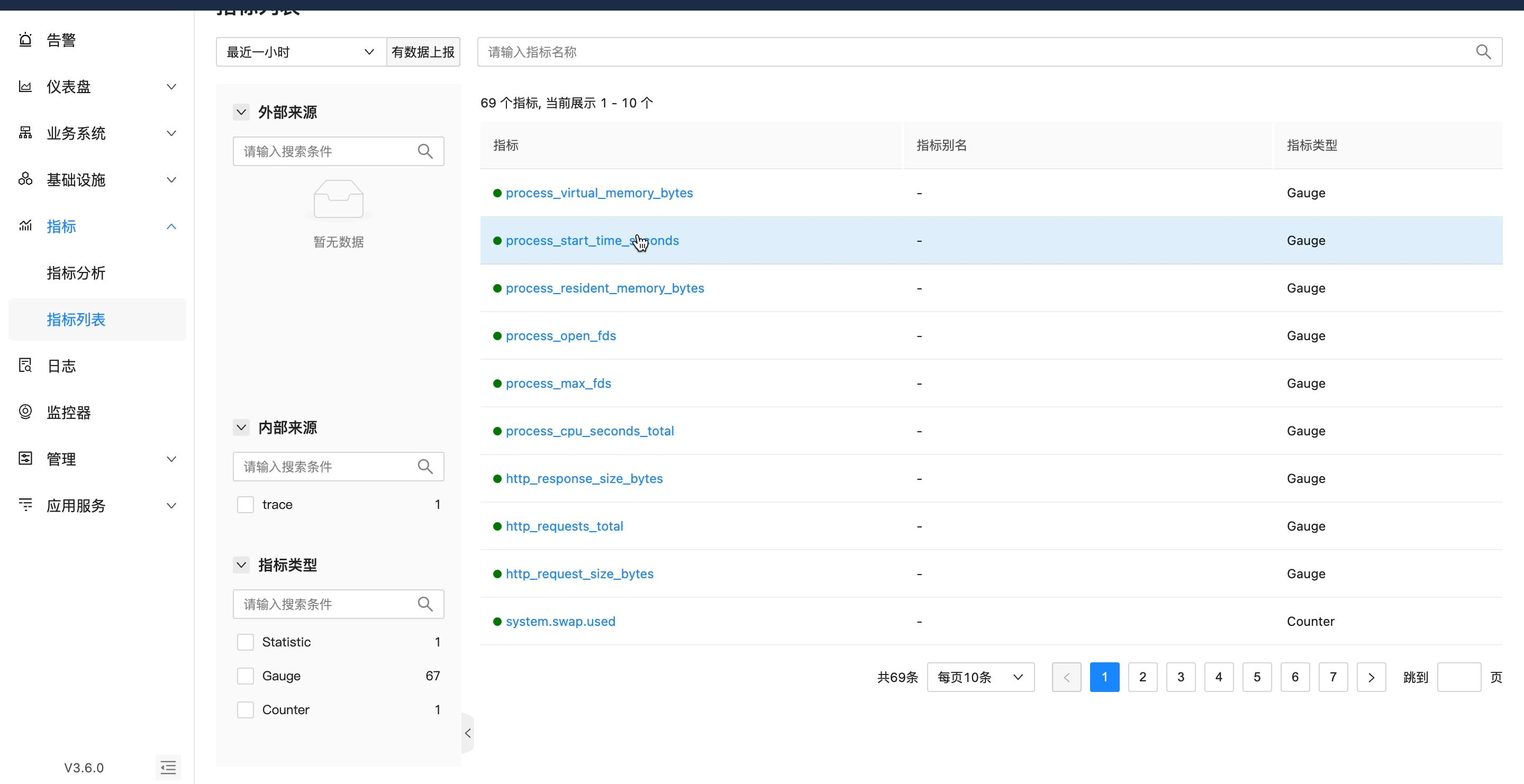
CMDB节点解析能力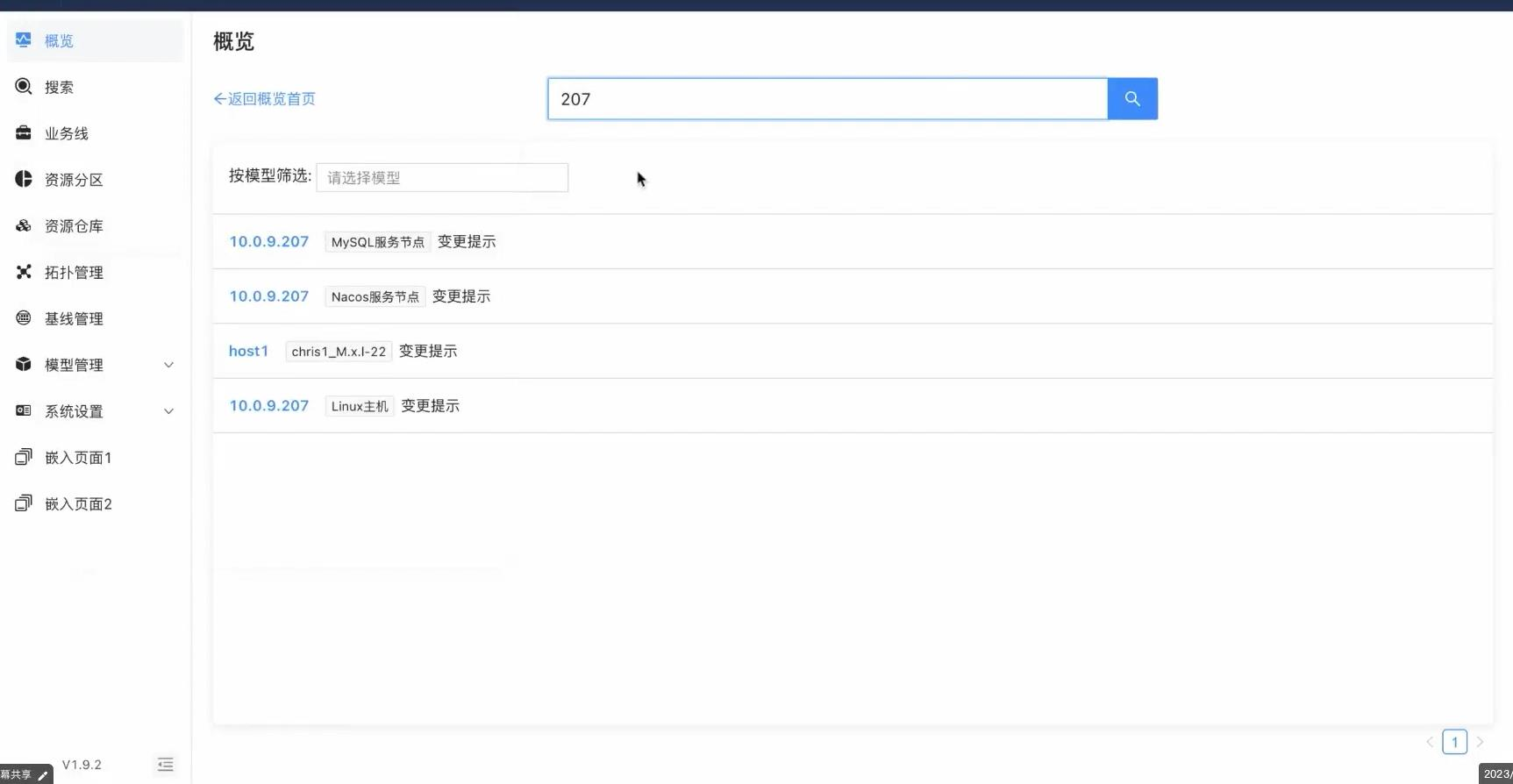
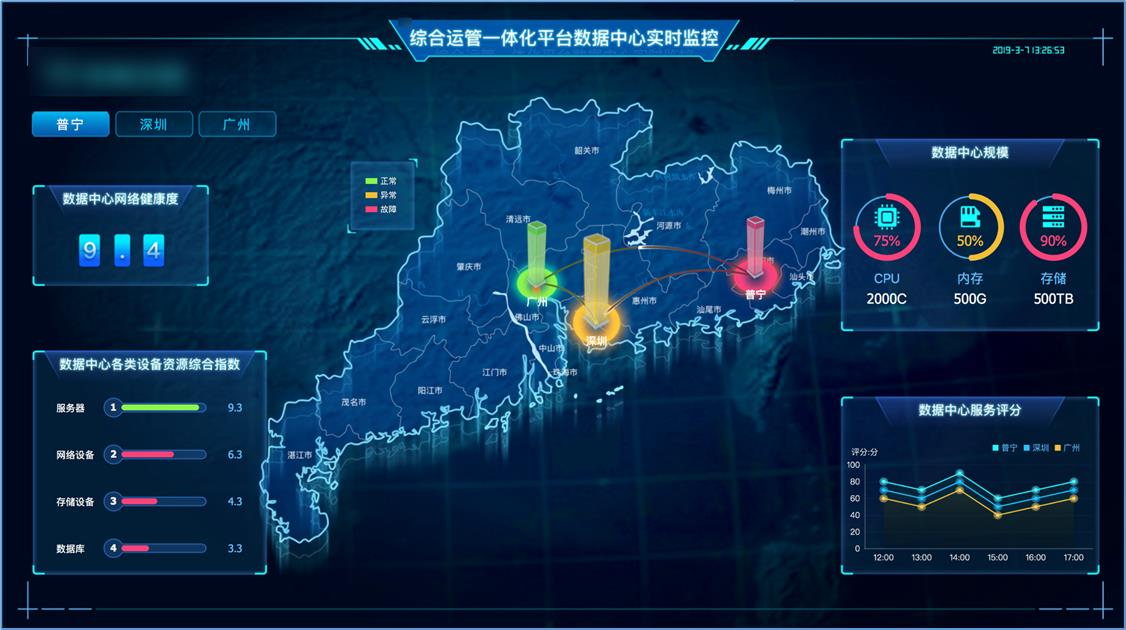
案例分享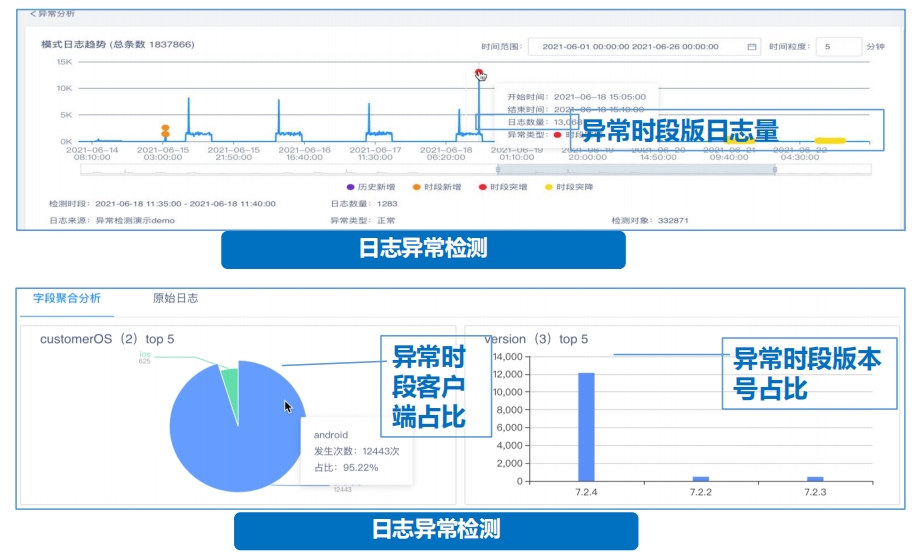
覆盖业务节应用:10个;
监控对象:1300+;
监控指标:2874个;
接入指标:15552个;
日志采集:2.5亿条/日;
每日数据:450G。

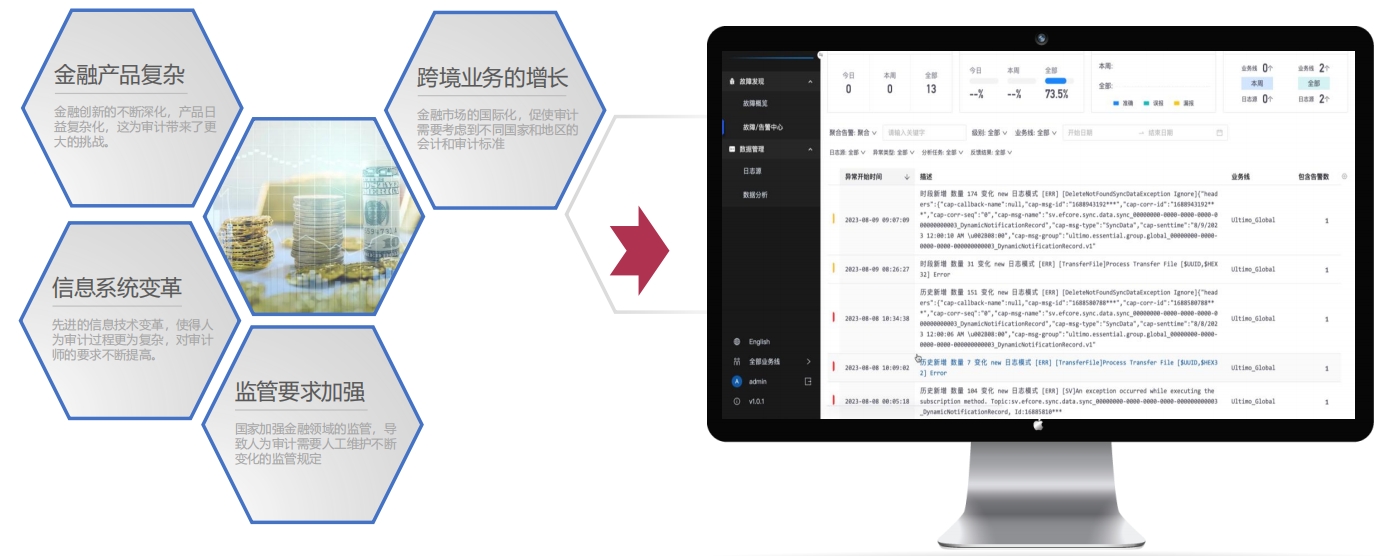
 大模型管理平台赋能金融审计结合日志流实时信息审查
大模型管理平台赋能金融审计结合日志流实时信息审查大语言模型赋能金融合规性审查审计,降低企业合规性风险20%
产品推荐