







阿里云实时计算Flink版
 首页
首页 客户业务与方案痛点阿里云Flink产品介绍
客户业务与方案痛点阿里云Flink产品介绍实时计算 Flink版(Alibaba Cloud Realtime Compute for Apache Flink,Powered by Ververica)是阿里云提供的基于 Apache Flink 构建的企业级、高性能实时大数据处理系统,由Apache Flink创始团队官方出品。在阿里云实时计算团队目前是全球最大、拥有 Committer 数量最多、专业性最强的 Flink 团队,为实时计算用户提供企业级的管理和咨询服务。

阿里云实时计算Flink版简介:产品技术架构企业级引擎功能与性能领先社区,平台化能力帮助用户专注于实时业务实现与运行

阿里云实时计算Flink版简介:产品功能架构 成本与性能优势分析:高性能、高弹性、充分利用资源
成本与性能优势分析:高性能、高弹性、充分利用资源 成本与性能:企业级Flink引擎VVR 性能提升
成本与性能:企业级Flink引擎VVR 性能提升使用Nexmark中的用例和相同的硬件资源,测试并对比了VVR 6.0 和对应开源版本Apache Flink 1.15,平均性能是开源的两倍

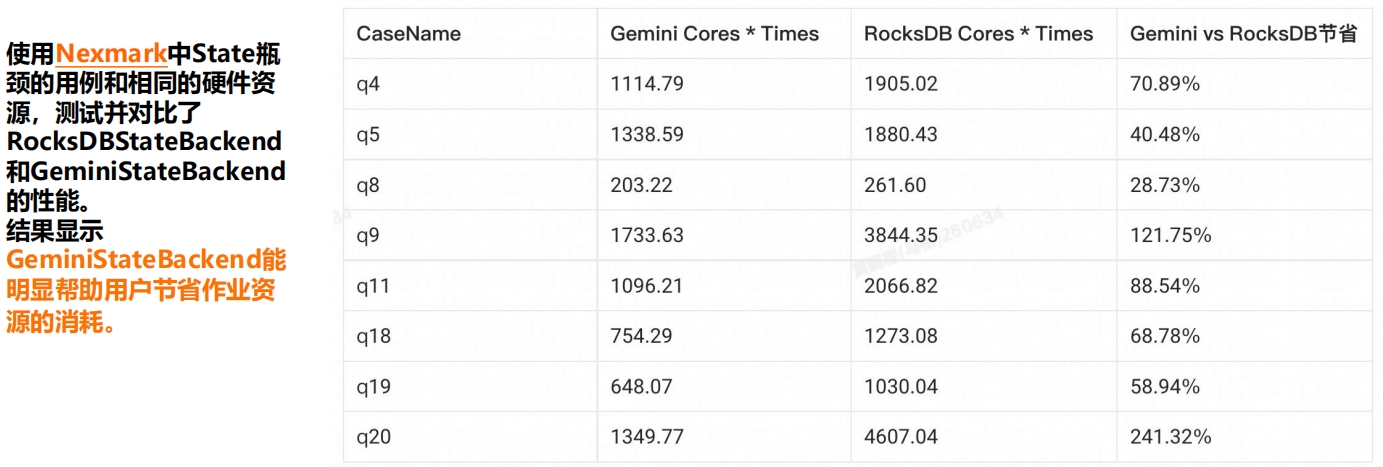
成本与性能:企业级状态后端存储引擎性能提升GeminiStateBackend是一款面向流计算场景的KV存储引擎,并作为实时计算Flink版产品的默认状态存储后端,大规模应用在阿里巴巴集团和阿里云客户生产实践当中。核心能力如下:多流场景join下大幅提升效能,提升资源利用率。全新的架构和数据结构设计,全面的性能提升。支持存储计算分离,彻底摆脱状态数据的本地盘存储限制。自适应参数调优,告别手动调参烦恼。
平台功能介绍:一站式开发运维平台平台功能介绍:流批一体的作业开发与运行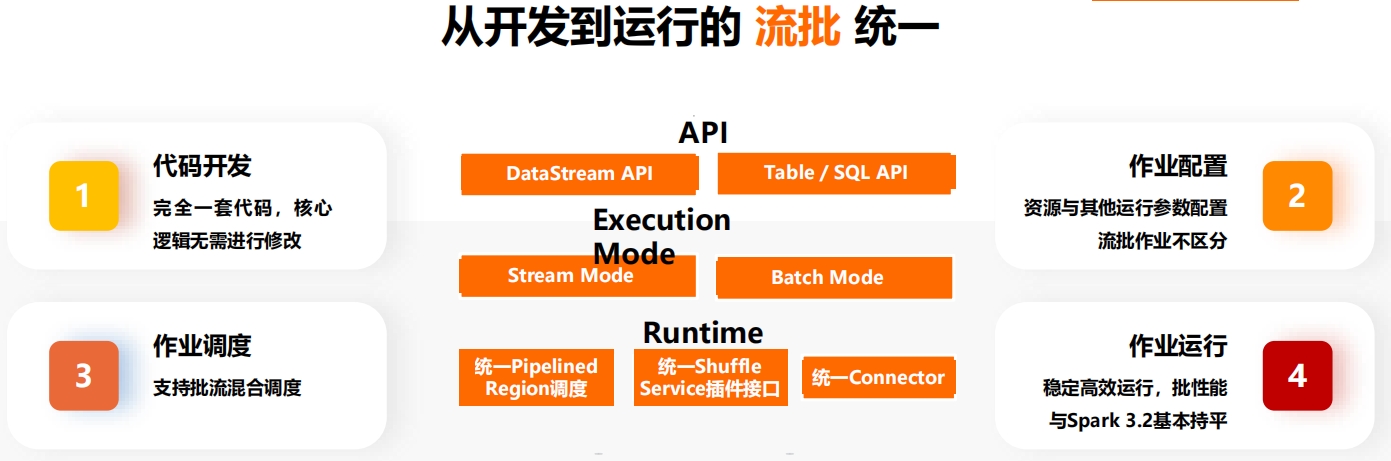 平台功能介绍:纯SQL开发,简单易用,专注业务
平台功能介绍:纯SQL开发,简单易用,专注业务 平台功能介绍:SQL代码模板,场景化代码示例
平台功能介绍:SQL代码模板,场景化代码示例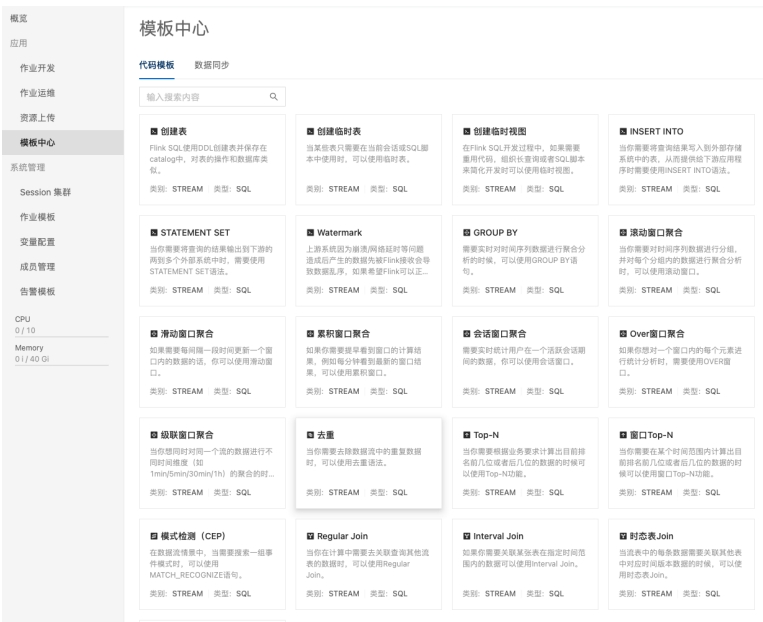 平台功能介绍:统一元数据管理带来的开发便捷,湖、平台功能介绍:简单快速实现SQL调试,支持模拟数据生成
平台功能介绍:统一元数据管理带来的开发便捷,湖、平台功能介绍:简单快速实现SQL调试,支持模拟数据生成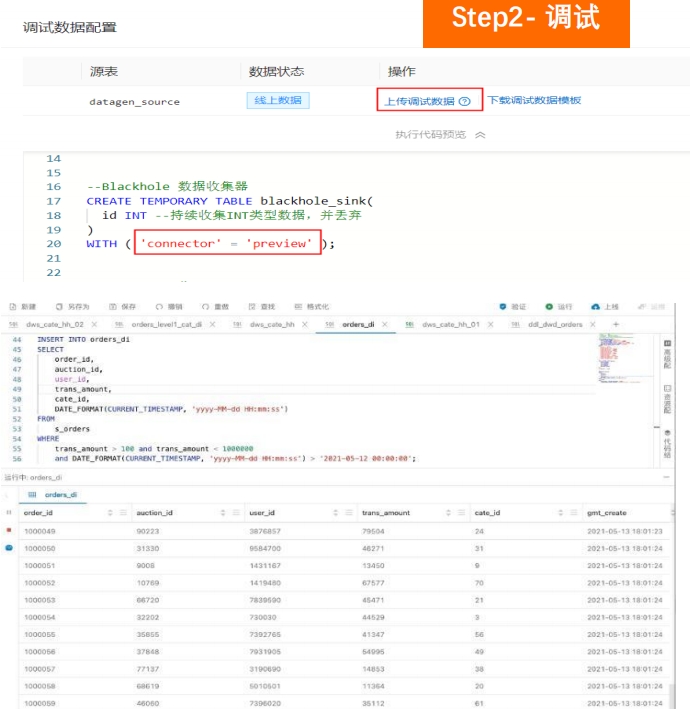 平台功能介绍:作业异常判断、监控与告警平台功能介绍:作业资源自动调优-全自动调优
平台功能介绍:作业异常判断、监控与告警平台功能介绍:作业资源自动调优-全自动调优 平台功能介绍:作业资源自动调优-定时调优
平台功能介绍:作业资源自动调优-定时调优很多业务都具备可预见性的、周期性的流量高峰段和低谷段,例如电商平台每年双十一、直播平台晚高峰时期,可以根据压测确定的资源用量,设定Flink作业不同时段的资源使用量,为业务洪峰提前做好资源准备。

平台功能介绍:作业智能诊断,一键诊断问题产品能力孵化于阿里巴巴集团,在内部各种实时应用的作业上有着广泛的应用,具备成熟的经验和能力
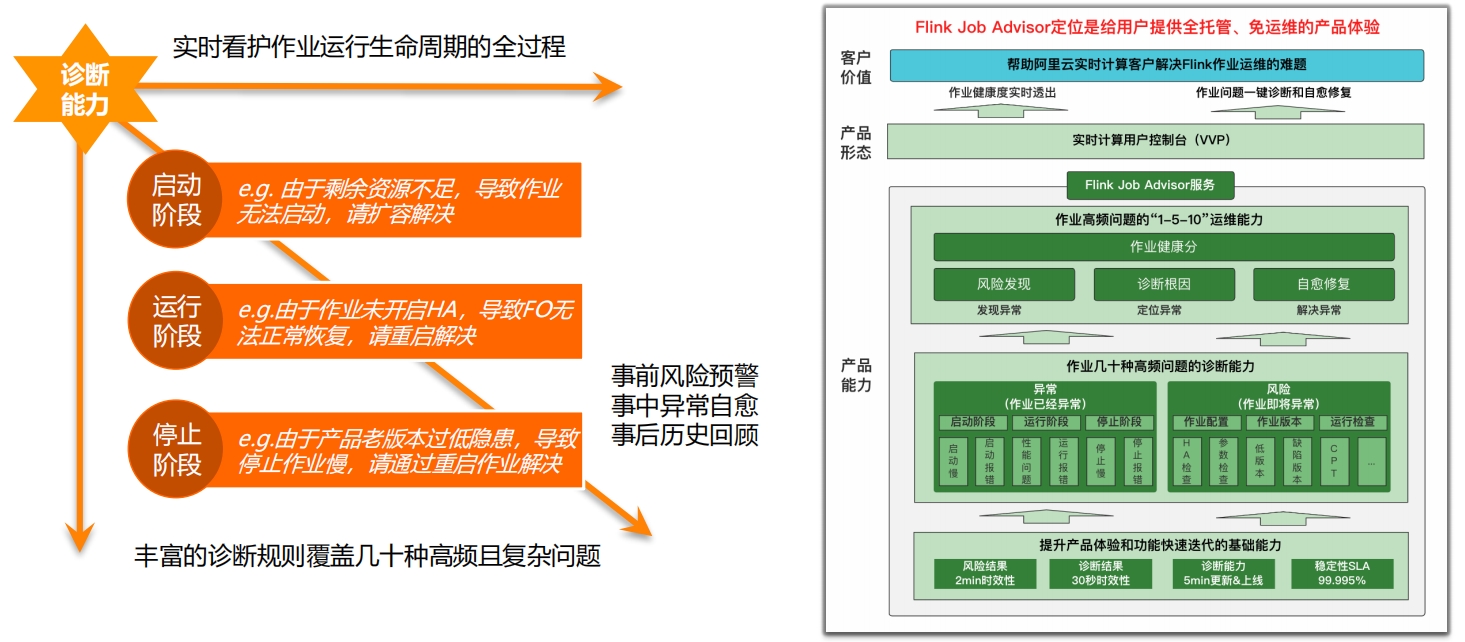
平台功能介绍: Flink作业State的全生命周期管理Flink作业有状态的计算,对于用户业务稳定性、业务连续性、灵活性等至关重要

平台功能介绍:灵活的被集成能力基于OpenAPI 的集成能力、CI/CD*、本地开发*

平台功能介绍:安全权限管理 引擎能力介绍:内置丰富的上下游数据连接(Connector)
引擎能力介绍:内置丰富的上下游数据连接(Connector)
 引擎能力介绍:业务连续性 -- 失败快速恢复
引擎能力介绍:业务连续性 -- 失败快速恢复 引擎能力介绍:业务连续性 -- 参数热更新
引擎能力介绍:业务连续性 -- 参数热更新开源Flink 修改并发度等参数需全局重启 -> 阿里云Flink在线热更新,基于当前作业修改生成新作业

引擎能力介绍:业务连续性 -- 参数热更新的原理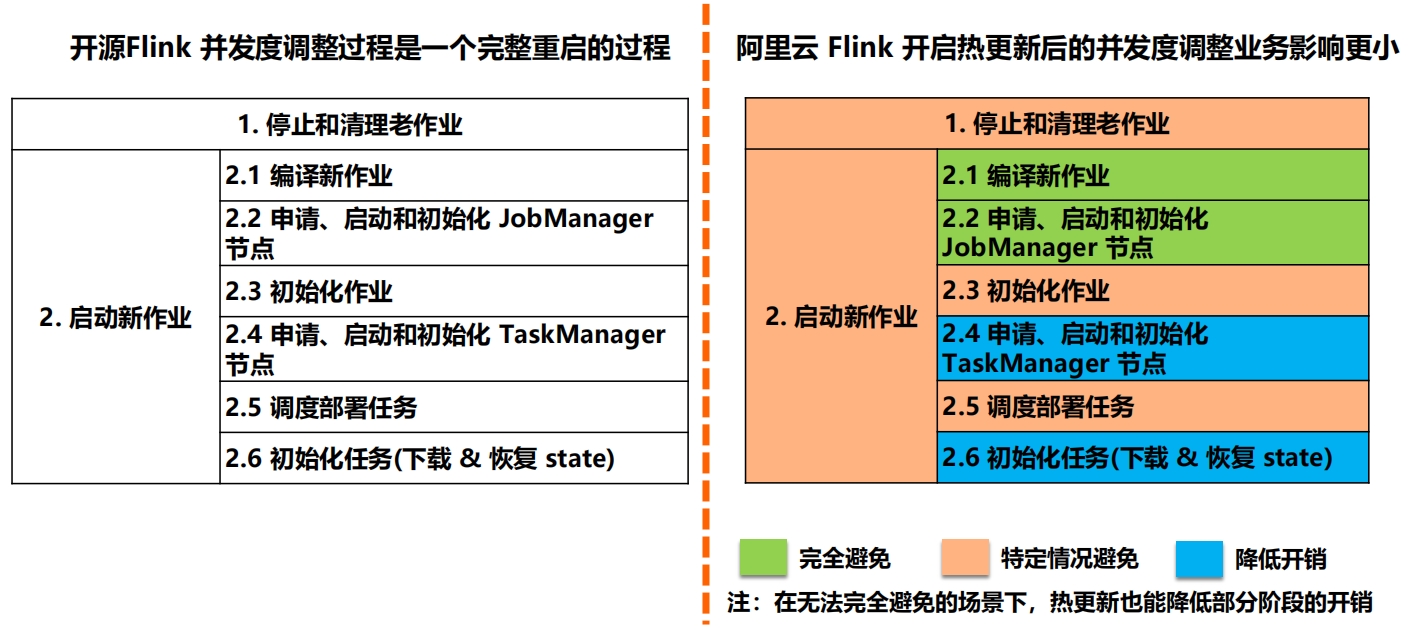 引擎能力介绍:业务连续性 -- 参数热更新的原理
引擎能力介绍:业务连续性 -- 参数热更新的原理 引擎能力介绍:业务连续性 -- 参数热更新的结果对比
引擎能力介绍:业务连续性 -- 参数热更新的结果对比 引擎能力介绍:Flink CDC的数据实时入湖入仓
引擎能力介绍:Flink CDC的数据实时入湖入仓基于Flink CDC,One SQL,One Job,Distributed Canal、 Debezium 、Maxwell、各种数据同步集成工具的替代品

引擎能力介绍:实时入湖入仓 -- 全增量一体化并发读取 引擎能力介绍:实时入湖入仓 -- 表结构变更自动同步
引擎能力介绍:实时入湖入仓 -- 表结构变更自动同步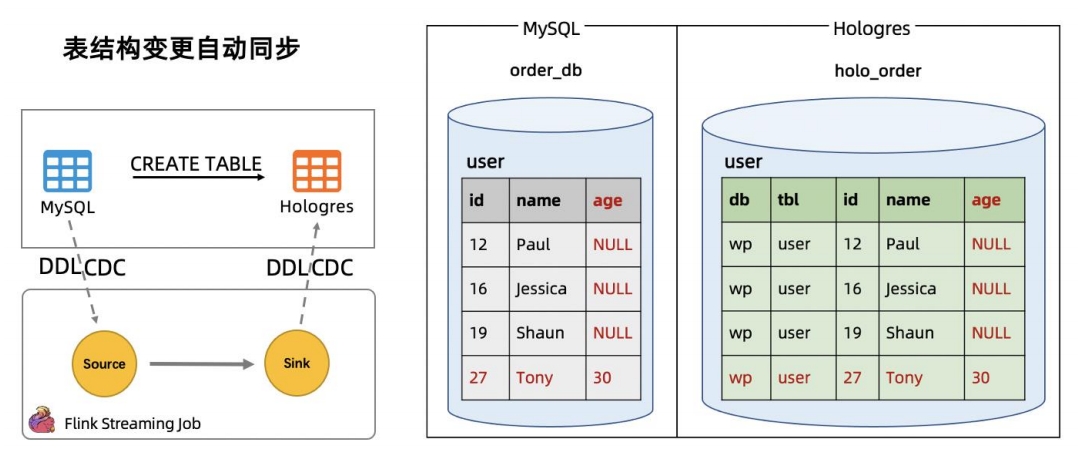 引擎能力介绍:实时入湖入仓 -- 分库分表与整库同步
引擎能力介绍:实时入湖入仓 -- 分库分表与整库同步 引擎能力介绍:动态CEP – 工作原理
引擎能力介绍:动态CEP – 工作原理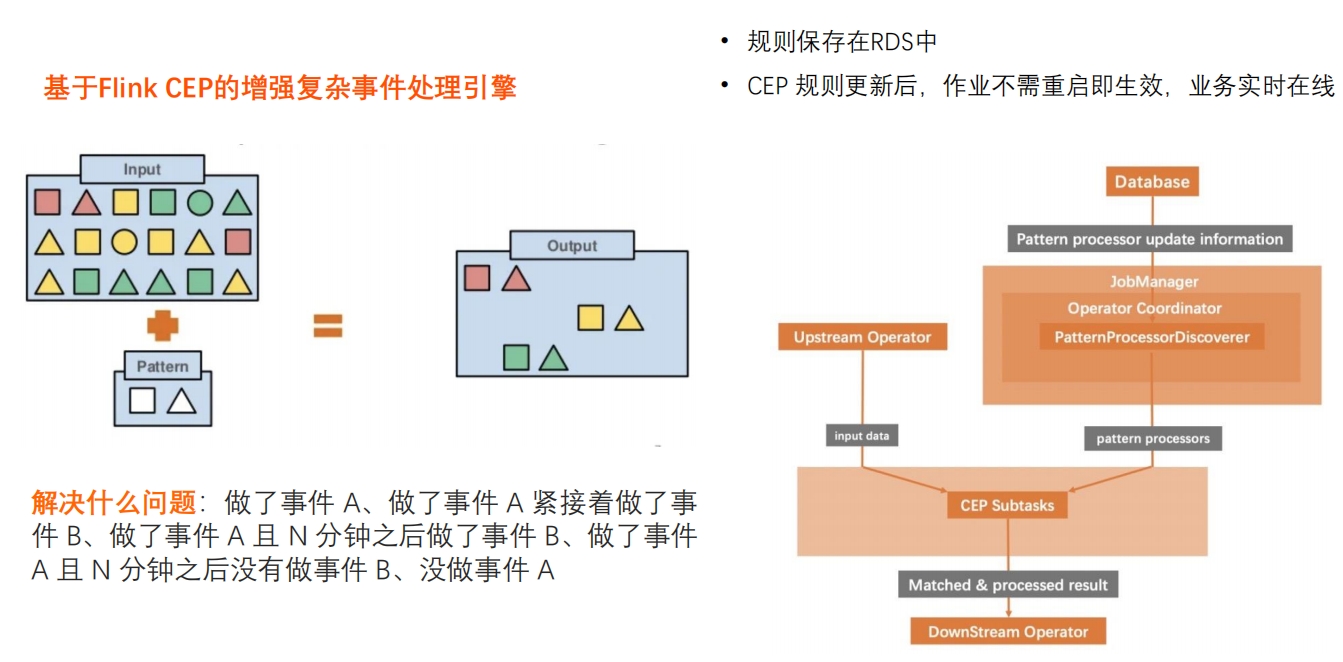 引擎能力介绍:实时数据入仓阿里云Hologres
引擎能力介绍:实时数据入仓阿里云Hologres 引擎能力介绍:流式数仓 Flink Table Store 能力
引擎能力介绍:流式数仓 Flink Table Store 能力 引擎能力介绍:流式数仓 Flink Table Store 基本原
引擎能力介绍:流式数仓 Flink Table Store 基本原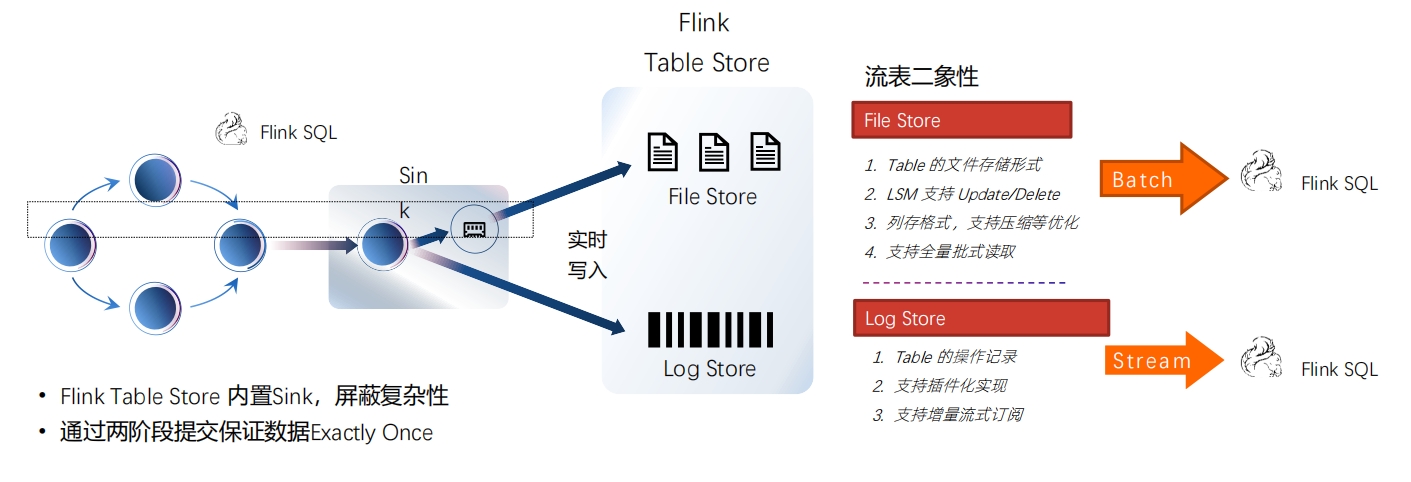 业界认可 – 国内
业界认可 – 国内 业界认可 – 国际
业界认可 – 国际 典型场景与方案
典型场景与方案 典型场景与方案:基于阿里云技术产品的实时数仓
典型场景与方案:基于阿里云技术产品的实时数仓 典型场景与方案:基于开源技术架构的实时离线数仓
典型场景与方案:基于开源技术架构的实时离线数仓 上述实时数仓面临的问题和挑战
上述实时数仓面临的问题和挑战 典型场景与方案:Flink + Hologres 构建实时数仓
典型场景与方案:Flink + Hologres 构建实时数仓 典型场景与方案:Flink + Hologres 流批一体数仓
典型场景与方案:Flink + Hologres 流批一体数仓 典型场景与方案:基于 Flink Table Store 的流式数仓
典型场景与方案:基于 Flink Table Store 的流式数仓 典型场景与方案:基于CEP动态规则的实时风控平台
典型场景与方案:基于CEP动态规则的实时风控平台 典型场景与方案:实时大屏
典型场景与方案:实时大屏 典型场景与方案:实时监控
典型场景与方案:实时监控 典型场景与方案:在线机器学习
典型场景与方案:在线机器学习 具体案例:满帮集团实时业务上云方案
具体案例:满帮集团实时业务上云方案 具体案例:钱大妈实时风控与营销系统构建
具体案例:钱大妈实时风控与营销系统构建 具体案例:全球Top 20 的某游戏公司实时数仓架构演进
具体案例:全球Top 20 的某游戏公司实时数仓架构演进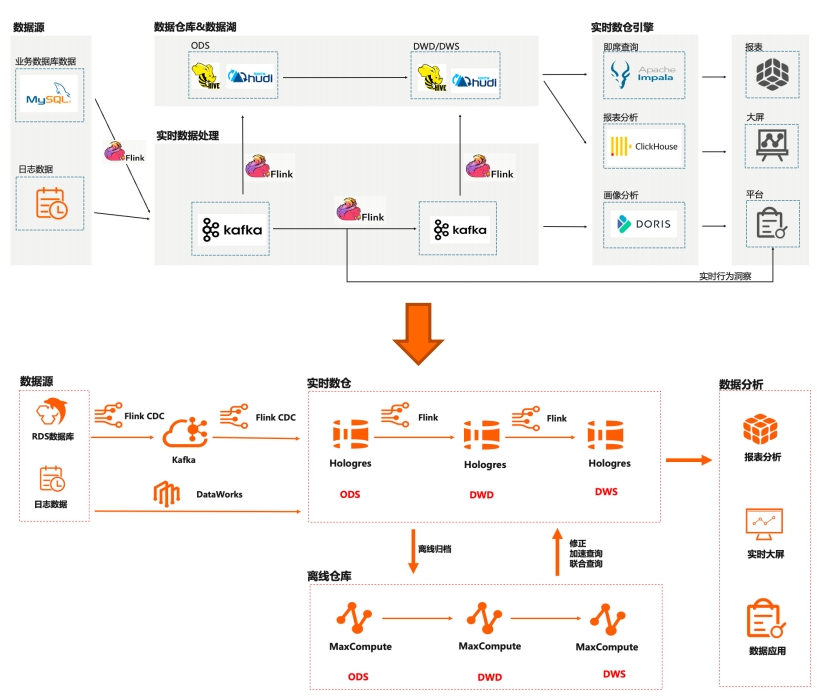 具体案例:长城汽车,主机厂车企的数据中台
具体案例:长城汽车,主机厂车企的数据中台 具体案例:某跨境电商实时数据入仓方案
具体案例:某跨境电商实时数据入仓方案
 具体案例:天猫核心交易数据流批一体化计算
具体案例:天猫核心交易数据流批一体化计算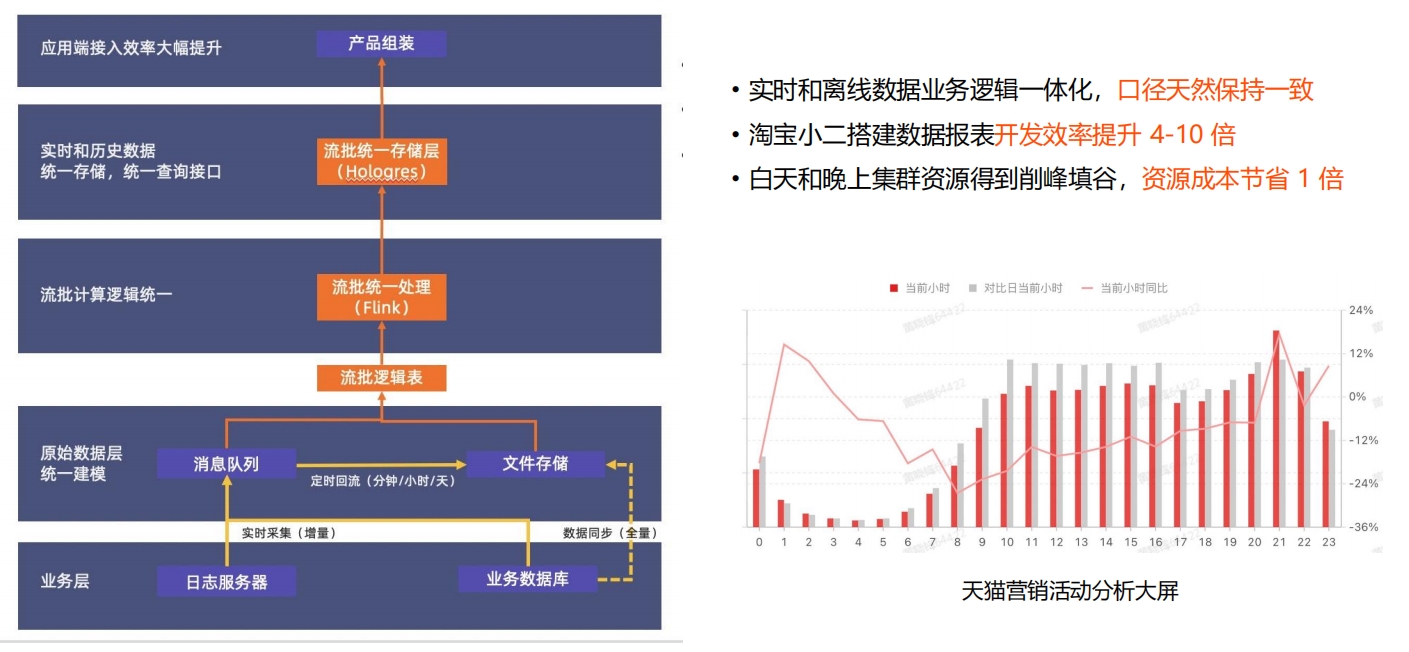 具体案例:微博实时机器学习系统构建
具体案例:微博实时机器学习系统构建
产品推荐







