







腾讯云智能内容识别平台
 首页
首页 产品定位 产品矩阵
产品定位 产品矩阵 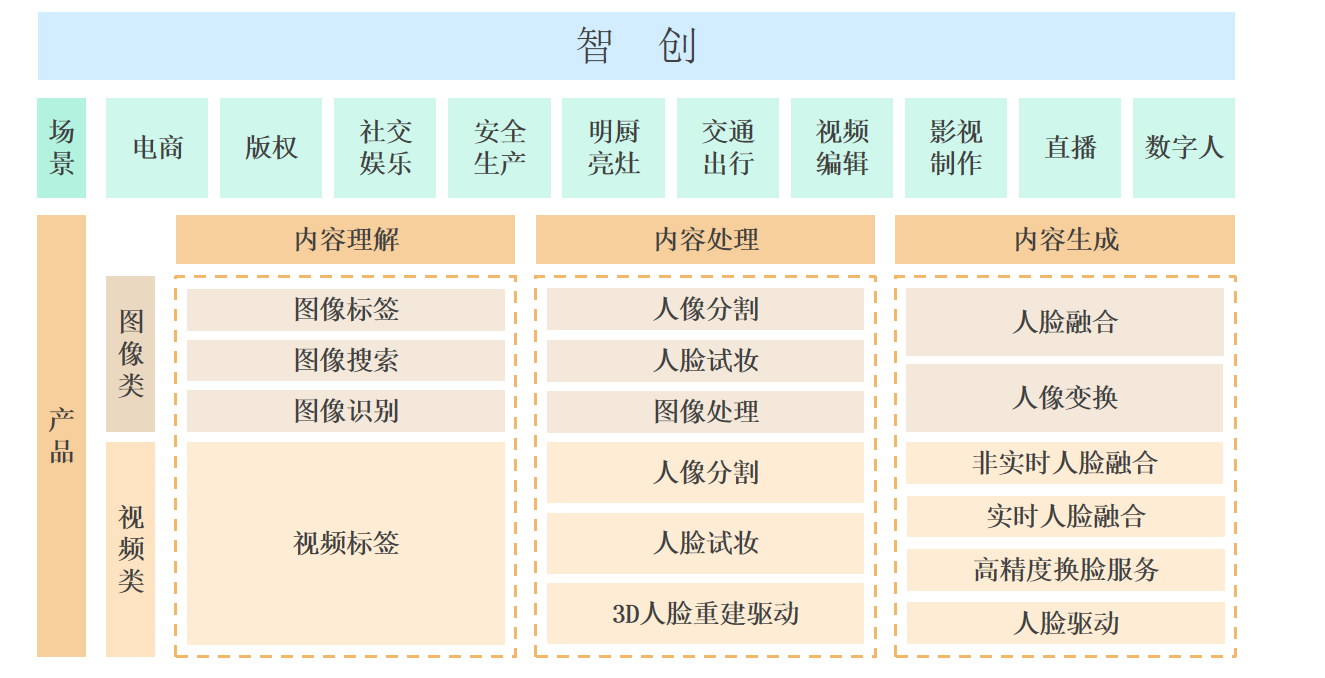 产品优势 演进路线
产品优势 演进路线 由点到面:从图片人脸融合做起,逐步扩展到分割、变换等20+项原子能力,结合云+AI的优势构建起从内容理解、处理到生成的原子能力工具箱,支持客户一站式接入使用。 由浅入深:从支持项目制的营销项目开始,逐步深入建立营销解决方案批量复制爆点活动,再拓展到图片视频编辑领域建立行业影响力,今年从消费级内容市场迁移到虚拟形象生成、影视内容生成等工业级内容市场,建立新的行业壁垒。
 内容理解 · 图像/视频
内容理解 · 图像/视频智能理解图片或视频内容,提供自动打标服务。包含以下两款子产品: 图像标签:识别图片中的各种物体或场景等,返回具体的名称标签、所属类别和置信度等,覆盖日常物品、场景、动物、植物、食物、饮品、交通工具等多个大类,数百个细分类目,数千个具体标签。 视频标签:通过对视频中视觉、场景、行为、物体等信息分析,结合多模态信息融合及对齐技术,实现高准确率内容识别,自动输出视频的多维度内容标签。
 智创 · 内容理解 · 图像/视频标签
智创 · 内容理解 · 图像/视频标签  智创 · 内容理解 · 图像/视频标签
智创 · 内容理解 · 图像/视频标签  智创 · 内容理解 · 图像/视频标签
智创 · 内容理解 · 图像/视频标签  智创 · 内容理解 · 图像搜索
智创 · 内容理解 · 图像搜索 基于图像检索、超细粒度元素挖掘和图像匹配等技术,通过以图搜图的方式在自建图片库中快速检索出与输入图片相似的图片集合。包含以下三款子产品:
智创 · 内容理解 · 图像搜索 相同图像搜索:用于通用图搜场景下的原图等搜索 基于输入检索的图片全图,在用户自建图片库中搜索相同原图或高度相似的图片集,并给出相似度打分,可支持经过裁剪、翻转、模糊、扭曲、滤镜调色、加水印等二次编辑后的图片搜索。
 智创 · 内容理解 · 图像搜索
智创 · 内容理解 · 图像搜索 相似图像搜索:针对图案的搜索。针对输入检索的图片中包含的图像元素或主体,例如图案、logo、纹理等,在用户自建图片库中搜索与之相似的元素图片,并给出相似度打分。
 智创 · 内容理解 · 图像搜索
智创 · 内容理解 · 图像搜索 商品图像搜索:针对同款商品的搜索 基于输入检索的图片,可智能识别图片中的商品主体,在自建图片库中搜索相同或相似的商品图片,并给出相似度打分。如果输入检索的图片包含服饰类商品,可智能识别上衣、下装、裙装、鞋、包、配饰等多种服饰的类别、颜色以及其他特征属性。
 智创 · 内容理解 · 图像搜索
智创 · 内容理解 · 图像搜索  智创 · 内容理解 · 图像搜索 典型案例
智创 · 内容理解 · 图像搜索 典型案例  典型案例
典型案例  典型案例
典型案例  典型案例
典型案例  针对不同细分领域提供专业性的图像智能识别服务
针对不同细分领域提供专业性的图像智能识别服务 典型案例 智创 · 内容处理 · 人像分割
典型案例 智创 · 内容处理 · 人像分割 对图片或视频中的人体轮廓范围进行识别,将其与背景进行分离,实现精细化抠图的效果。包含以下三款子产品: 图片二分类人像分割:识别图片中完整的人体轮廓并将其与背景进行分离,对图片中无正脸、侧脸、背影,单人,多人等可实现分割。 图片多分类人像分割:在图片前后景分割的基础上进行多分类分割,支持对头发、五官、头部等21种类目信息的分割,既可作为换发型、挂件等底层技术,也可用于抠人头、抠人脸等玩法。 视频人像分割:识别视频流中的人体轮廓并将其与背景分离,可满足单人、多人、半身、全身、无人脸、侧脸等多种不同场景,提供离线SDK、API等部署方式。
 应用场景
应用场景 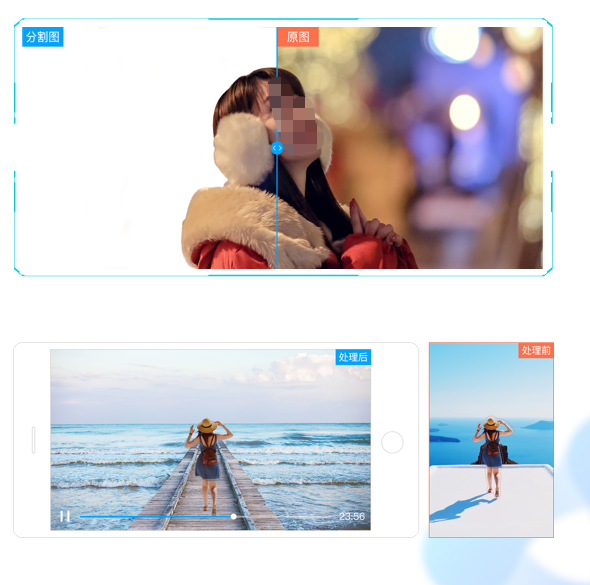 典型案例
典型案例 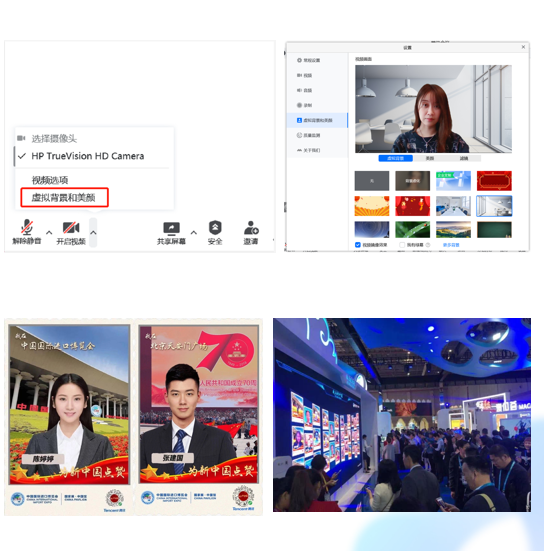 智创 · 内容处理 · 人脸试妆
智创 · 内容处理 · 人脸试妆 提供多种美颜美妆功能,打造自然清晰的人像处理效果。包含以下三款子产品: 试唇色:对人脸图片进行唇部彩妆替换,实现唇部色彩自然融合处理。同时支持在视频流中进行唇色的选择和替换,色彩还原度、素材贴合度更高,带来更好的试妆效果。 图片滤镜:对图片进行滤镜处理,支持七十多种不同风格的滤镜效果,包含日系、甜美、质感、清新等滤镜。 效果自然 适用不同表情、性别、年龄、姿态、光照条件,美妆美颜效果处理自然,打造无暇妆容。 调参灵活 支持通过 API 调整细节参数,使面部处理更精细贴切,可根据业务实际使用反馈随时调整。
 应用场景
应用场景 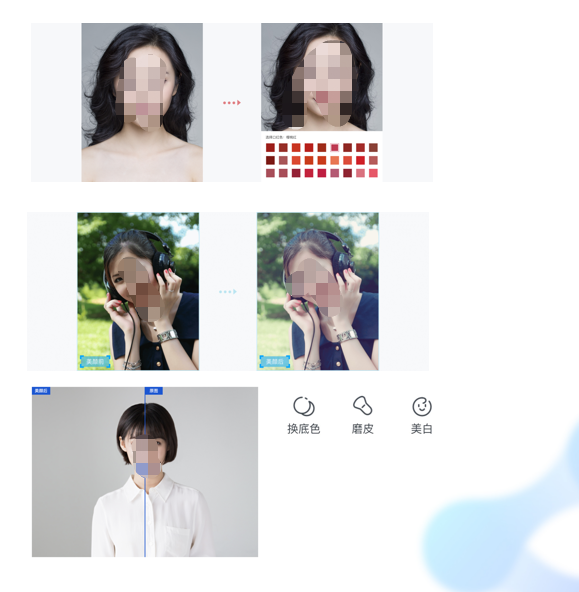 智创 · 内容处理 · 3D人脸重建驱动
智创 · 内容处理 · 3D人脸重建驱动 通过人脸3D重建技术,依靠用户2D人脸图像估计精确的人脸3D姿态和表情,进而驱动虚拟3D形象进行相应的姿态表情变化,达到高精度人脸表情驱动的目的。 输入输出: 输入一张人脸图片/一段人脸视频。 输出重建结果及表情系数,驱动3D人脸虚拟Avatar。 接入方式: 支持多端口接入,包括安卓端、IOS端和Win端。
 应用场景
应用场景  典型案例
典型案例  智创 · 内容处理 · 图像处理
智创 · 内容处理 · 图像处理 基于深度学习等人工智能技术,提供综合性的图像优化处理服务。包含以下子产品: 图像质量评估:评估输入图片在视觉上的质量,给出综合的、客观的清晰度评分,和主观的美观度评分。 图像清晰度增强:消除图片因有损压缩导致的噪声,改善因使用滤镜、拍摄失焦等导致的图像模糊问题,让图片的边缘和细节更加清晰自然。 图片智能裁剪:根据输入的裁剪比例,智能判断一张图片的最佳裁剪区域。 黑白图片上色:给定一张给白图像,输出上色后的结果
 应用场景及典型案例
应用场景及典型案例 产品推荐






