







魔音工坊AI配音平台
立即咨询
 首页
首页 出门问问TTS承接平台-魔音工坊 | 产品介绍视频
出门问问TTS承接平台-魔音工坊 | 产品介绍视频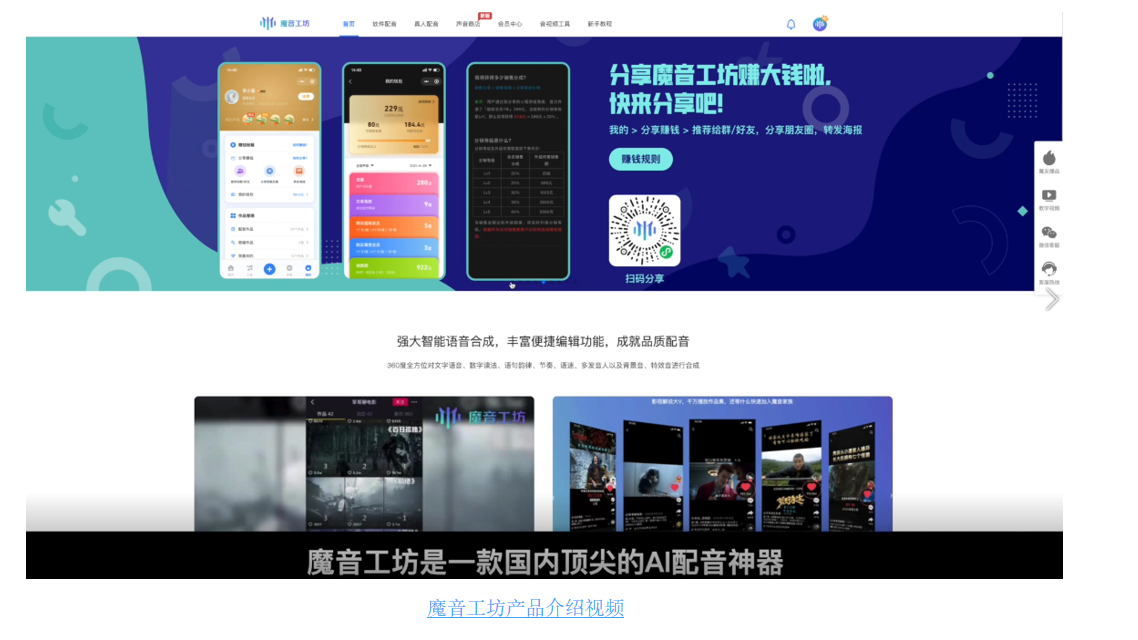 出门问问TTS承接平台-魔音工坊 | 专业的AI配音软件
出门问问TTS承接平台-魔音工坊 | 专业的AI配音软件  强大的音频合成编辑功能
强大的音频合成编辑功能 首创声音编辑器,可实现多音字、重度、停顿调节、连续等功能,支持局部变速、变音、多人配音,自带版权BGM、音效等。
 1000+发音人满足用户多样性需求
1000+发音人满足用户多样性需求 100+方言配音、外语配音,支持老人、小孩等不同年龄、不同音色的声音。
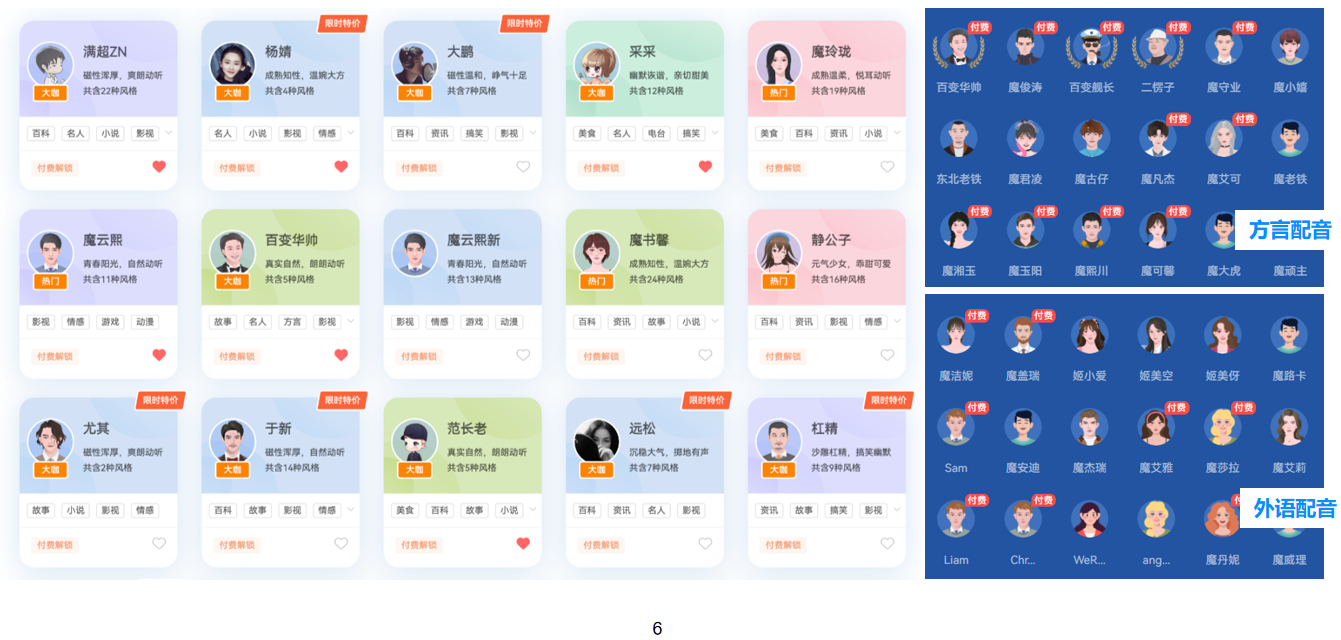 覆盖喜怒哀乐四大维度情绪,让声音更有温度
覆盖喜怒哀乐四大维度情绪,让声音更有温度 同一发音人可支持二十多种情绪表达。
 众多大咖入驻魔音
众多大咖入驻魔音  多元化的解决方案
多元化的解决方案  全新的后付费合作模式
全新的后付费合作模式  领先的声音定制服务魔音工坊声音克隆八大优势 魔音工坊声音克隆八大应用场景 声音转换,音色转化成其他发音人
领先的声音定制服务魔音工坊声音克隆八大优势 魔音工坊声音克隆八大应用场景 声音转换,音色转化成其他发音人 说话人转换:保留「原说话人」的声调、韵律、停顿等特色,音色转换成「目标人」音色。
 实时变声功能&声纹识别-听音识人
实时变声功能&声纹识别-听音识人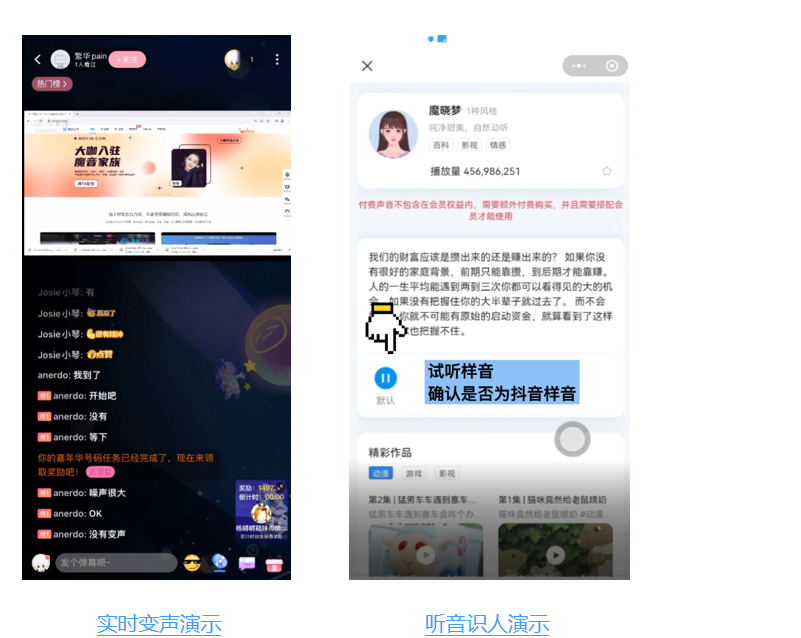 Dupdub(魔音海外版):助力短视频出海
Dupdub(魔音海外版):助力短视频出海  Overview of DupDub
Overview of DupDub  品牌合作案例
品牌合作案例  品牌合作案例-微信读书
品牌合作案例-微信读书 
出门问问TTS技术优势
1-TTS端到端语音合成引擎,合成效果媲美真人 业界领先的完全端到端模型,合成效果高度接近真人(MOS:4.488) 端到端语音合成方案MeetHiFiVoice (Mobvoi End-to-End TTS HiFiVoice)MOS是通信术语,值常以衡量通信系统语音质量的重要指标, MOS值在4.0-5.0区间,音频级别为优,表示听的清楚,延迟小,交流顺畅。
 领先的韵律准确率,多音字准确率业界Top 1
领先的韵律准确率,多音字准确率业界Top 1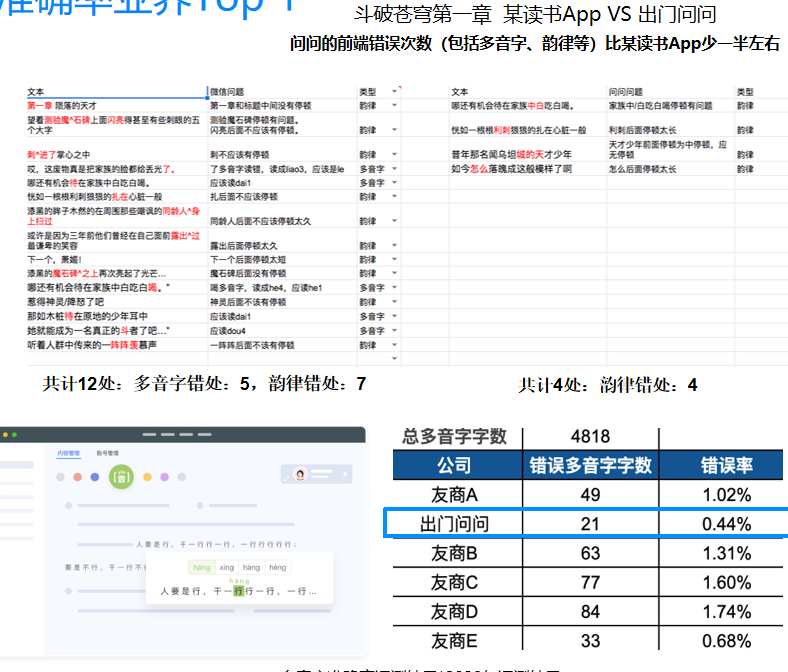
 丰富的语气/语调合成和重读/拖音功能,增强声音的表现力拟人化TTS,让声音更自然
丰富的语气/语调合成和重读/拖音功能,增强声音的表现力拟人化TTS,让声音更自然 情感语音合成
情感语音合成 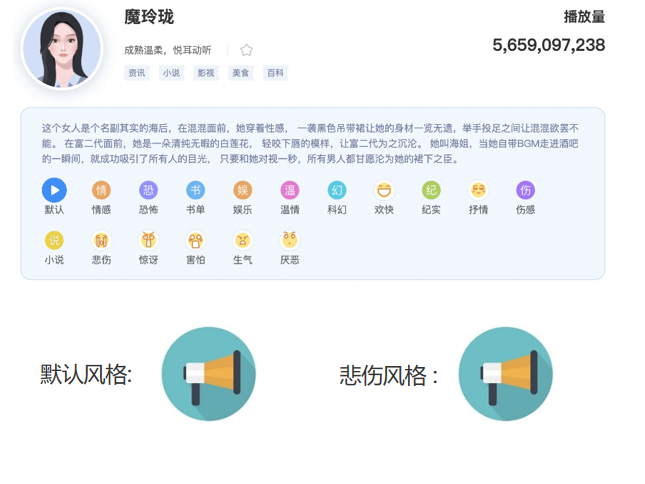
 情感强度控制
情感强度控制  跨语种语音合成
跨语种语音合成  歌唱合成&歌唱合成迁移
歌唱合成&歌唱合成迁移  实时声音转换
实时声音转换  角色迁移
角色迁移  声音克隆
声音克隆  高品质声音输出
高品质声音输出
 愿景:定义下一代人机交互,让人和机器的交互更自然
愿景:定义下一代人机交互,让人和机器的交互更自然 



 浓厚的技术基因 商业逻辑架构:以AI算法为切入点,赋能各行各业 AI算法:基于神经网络的自主全栈式AI算法
浓厚的技术基因 商业逻辑架构:以AI算法为切入点,赋能各行各业 AI算法:基于神经网络的自主全栈式AI算法 核心技术能力:语音交互
核心技术能力:语音交互 商业落地:全球领先的AI可穿戴设备
商业落地:全球领先的AI可穿戴设备  AI可穿戴:一流的国际产业合作伙伴
AI可穿戴:一流的国际产业合作伙伴  商业落地:智能车载(德国车规级前装语音助手)
商业落地:智能车载(德国车规级前装语音助手) 出门问问车载前装“离线在线融合语音助手”落地多款大众主力车型
 商业落地:AI算法license落地
商业落地:AI算法license落地 智能手表和真无线蓝牙耳机是高增长、高天花板的市场,将持续成为ToC增长引擎。

产品推荐

美洽智能语音机器人专注解决呼叫难题,全面触达目标客户,助力全域提效。无需购买额外设备,功能丰富,简单易学,支持自定义拖拽配置,操作自由流畅,更可以一键启动,快速投入使用。基于实时语音识别(ASR)、自然语言处理(NLP)、语音合成(TTS)等技术,实现智能外呼与应答,媲美真人的语音及对话,助力企业与客户高效沟通,让数智化客户服务为企业带来更高转化。

合合信息的企业数字化转型解决方案以智能文字识别和商业大数据技术为核心,为30多个行业提供全面的数字化服务。该方案通过多样化的高性能产品体系,帮助企业实现智能决策,涵盖智慧银行、保险、证券、供应链、地产、政务和医药等多个领域。服务优势包括17年的技术积累、灵活接入方式、稳定的服务、过硬的技术支持和无忧的售后服务。此外,合合信息与腾讯云等合作伙伴共同推动企业加速数字化转型,构建数字转型共同体的强大生态力量。在数据资产管理方面,合合信息分享了从数据到智能的数据资产管理经验,通过创新数据资产管理方法,解决数据资产管理难点,释放数据要素价值,发展新质生产力。合合信息的“数字政务大脑”作为其数字政府智能解决方案,依托智能OCR识别技术和企业全景实时数据,为政府提供精细化的数据采集、分析、治理、应用的解决方案,推动城市产业数字化和数字产业化的转型升级。


腾讯云微瓴是一个腾讯自主设计研发的,适合各行业的、安全、灵活且可以高效触达用户的物联网操作系统,在智慧建筑和智慧城市场景中担当物、信息与人协作的枢纽。微瓴智能建造平台是基于微瓴数字开放平台,通过对工程建造领域IOT数据、业务数据、空间数据的融合,为工程建造提供数据共建共用、模型共建共享、应用共建共生的一站式建筑 产业互联网平台。



