
天穹SuperSQL:腾讯下一代大数据自适应计算引擎
来源: 云巴巴 2022-08-24 10:52:30导语
SuperSQL是腾讯自研的下一代大数据自适应计算平台。通过开放融合的架构,实现一套代码高效解决公有云、私有云、内网的任何大数据计算场景问题。我们通过将异构计算引擎/异构存储服务、计算引擎的智能化/自动化、SQL的流批一体、算力感知的智能调度纳入内部系统闭环,给用户提供极简统一的大数据计算体验。用户能够从繁杂的底层技术细节中解脱出来,专注于业务逻辑的实现,像使用“数据库”一样使用“大数据”,实现业务逻辑与底层大数据技术的解耦。
SuperSQL作为腾讯大数据智能计算平台的入口和决策中心,整合不同的大数据系统组件,旨在解决传统大数据架构下的痛点和难点问题,诸如大数据的语言门槛高、大数据引擎多而杂、大数据计算链路长而复杂、资源利用率低、存储异构、数据孤岛等。SuperSQL以自适应作为串联不同系统的能力抓手,通过自动、智能的方式解决传统大数据架构中的痛点问题:
-
语法自适应:统一不同的计算入口,自动适配不同的SQL语法和标准,降低大数据系统使用门槛
-
引擎选择自适应:根据SQL特点和历史执行信息,实现SQL引擎的智能选择与加速,自适应调优计算参数,提升整体计算性能,降低失败率
-
计算运行时自适应:根据运行时状态和信息反馈,动态调整计算执行拓扑,解决大数据计算执行链路复杂,稳定性低的问题
-
资源自适应:统一资源管理,屏蔽各类资源的性能差异,使业务能透明地使用资源;通过自适应地弹性扩缩,资源借调,最大化资源使用效率
-
数据编排自适应:实现不同异构存储场景下的存储加载策略,自适应不同架构下的数据融合计算需求,通过自动数据冷热分层,多级缓存,提升存储访问性能
-
场景架构自适应:适配多云混合架构,实现最优的跨集群、跨DC、跨云计算路由,打通数据链路,解决数据孤岛
融合计算平台已在天穹落地,服务微信、QQ、游戏等关键业务。平台每天承载百万级的计算任务,百PB级数据处理,百万级核数资源调度。本文将正式揭开新一代计算平台的面纱,揭秘如何实现大数据平台的自治化、智能化。
计算平台整体架构
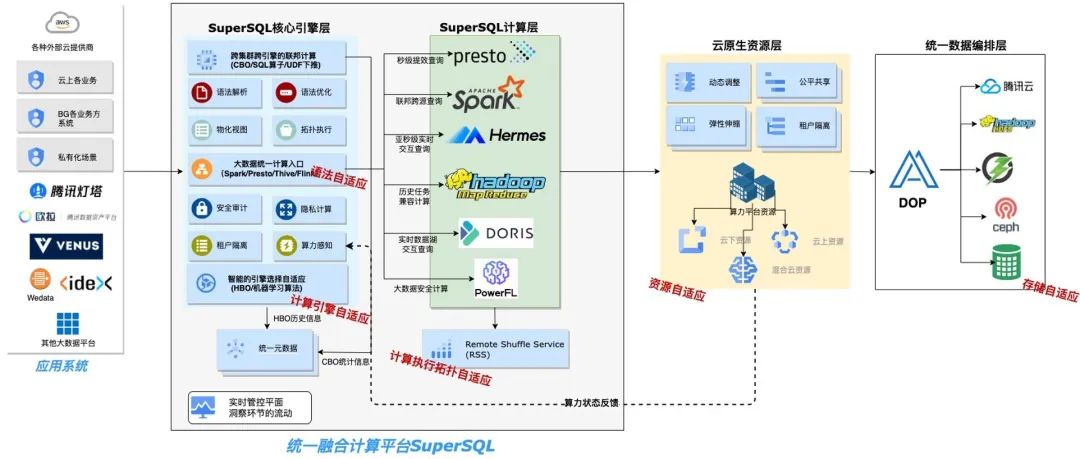
SuperSQL提供了完整的端到端的大数据解决方案,适配公有云、私有云、内网不同的场景。整个架构可以分为四层:核心引擎层、计算层、资源层、数据编排层。
-
核心引擎层是统一计算入口和智能决策中心。对外提供一套通用SQL语法,并自动适配计算引擎的不同SQL标准。同时汇总来自元数据、历史流水、底层集群状态等不同信息,通过组合算法做出SQL自适应优化、物化视图自主构建、引擎智能选择、计算参数调优等重要决策,从而影响整个计算的生命周期。
-
计算层会根据不同场景,采用不同的计算引擎,其中Spark负责ETL、报表场景,Presto负责交互式查询场景,Hermes负责日志检索、用户画像场景,Doris负责数据湖查询分析,PowerFL负责安全数据计算。核心引擎层根据SQL特点和使用场景选择最佳的计算引擎。为了保证计算在不同架构下的计算稳定性,Remote Shuffle Service(RSS)提供统一的数据Shuffle服务,实现计算执行拓扑自适应。
-
资源层整合云上和云下资源,把能够把所有资源统一管理起来,对计算提供统一的资源池。通过资源自适应调整、租户间资源弹性调度、集群中资源借调等手段,统筹管理调度资源,提升资源整体利用率。
-
数据编排层适配不同异构存储,透明化存储差异,解耦计算和存储。自主学习数据访问模式,自适应缓存热点数据和元数据,加速数据访问性能,提升集群稳定性。
语法自适应:
解耦大数据语法和业务逻辑
SuperSQL支持对接不同类型的外部计算(执行)引擎,包括Presto、Livy、Hive、Flink,以及丰富多样的数据源,如MySQL、PostgreSQL/TBase、Hive、TDW Hive (tHive)、SparkSQL/Livy、Oracle、Phoenix (HBase)、ElasticSearch、Kylin、ClickHouse、Hermes、Druid、H2、Presto。
引擎之间、数据源之间所使用的SQL语法存在一定的差异,SuperSQL作为计算平台的入口能够有效屏蔽语法差异做到语法自适应,从而为整合不同的大数据系统组件提供基石。它能提供一套通用SQL语法,并通过SQL兼容转换功能来实现不同SQL语法之间的转换;做到在用户无需更改SQL语法的前提下实现底层执行引擎的切换,通过一套SQL语法,自动适配不同计算引擎和数据源语法。
顾名思义,SQL兼容转换功能整体可以划分为两个模块,即SQL兼容与SQL转换。
-
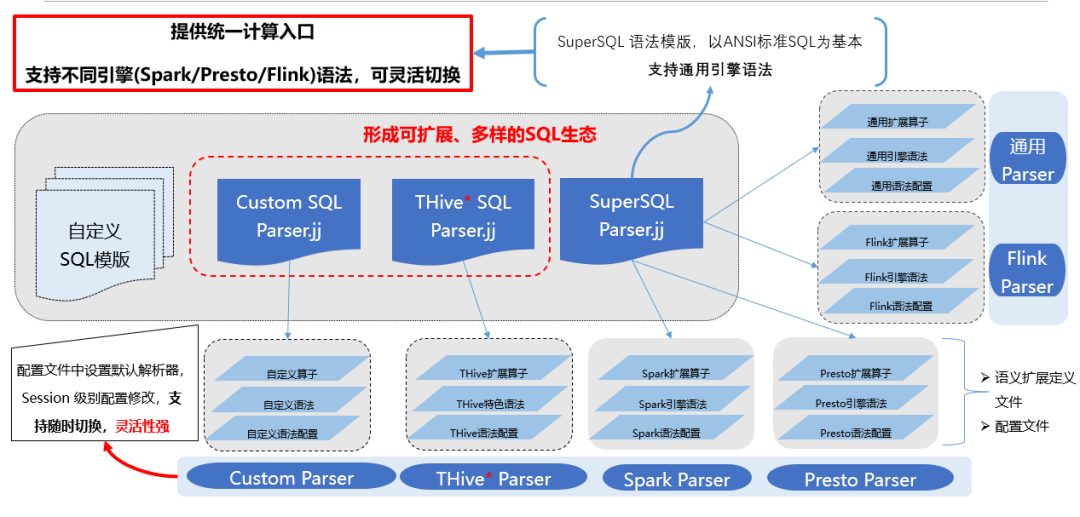
SQL兼容:在进行SQL兼容时,为解决部分大数据平台语法与业务强耦合、定制化严重,以及不同语法强行融合易导致歧义的问题,SuperSQL遵循干净、可扩展、可替换、多场景兼容的兼容准则,提供插件式的解析模块,将SQL语法模板化,分类管理,形成可扩展、多样的SQL生态。
SuperSQL将SQL语法分为两大类即通用型(如SQL标准语法,以及常见的Spark、Hive、Flink等大数据查询语法)、独特型(自定义语法,不具有普适性),基于分类语法模板、语义扩展定义、配置文件生成多样的SQL解析器,并且支持动态切换解析器,灵活性强。任意解析器得到的语法树均将转换为SuperSQL统一的逻辑计划,SuperSQL可基于此逻辑计划生成符合不同引擎或数据源方言语法的执行语句(这一过程即SQL转换)。SuperSQL默认使用通用Parser,其基于SQL标准语法,支持大部分通用大数据语法(如Spark、Hive语法),适用于大部分的大数据系统组件。而对于一些与业务逻辑强耦合的自定义语法,支持自定义SQL模板,生成自定义解析器,通过这种做法,结合上文提及的生成SuperSQL统一执行计划以及下文提及的SQL转换,可以灵活地将业务任务切换到指定引擎。
-
SQL转换:SQL转换发生在两个阶段,一阶段是通过解析器得到抽象语法树后,进行语法树重写以确保该语法树能转换为SuperSQL统一逻辑计划;另一阶段是基于SuperSQL统一逻辑计划与不同引擎或者数据源语法之间的等价映射关系,能够将SuperSQL逻辑计划转换为不同的引擎或数据源语法,做到执行引擎的无感切换,也为下文的智能引擎选择功能奠定基石。
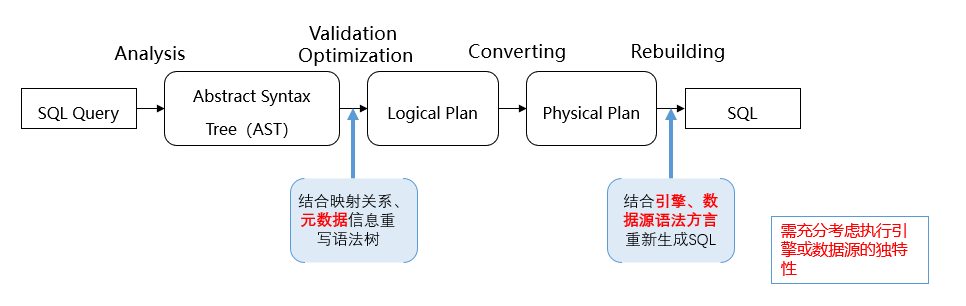
这种执行引擎的无感切换,不光能让SuperSQL平滑进行智能引擎选择,充分发挥引擎的优势特点,增加SQL执行效率;还能支持业务无感迁移,做到在用户无需更改SQL语法的前提下实现底层执行引擎的切换,并且尽量最小程度地更改用户的使用习惯。
通过SQL兼容和SQL转换,SuperSQL能够统一计算入口,整合大数据平台组件,降低大数据系统使用的门槛和繁琐程度。
引擎选择自适应:
智能选择引擎,加速SQL计算
智能引擎选择是自适应智能计算的核心功能之一,作为决策中心,SuperSQL通过组合算法,自动为每条用户SQL,挑选合适的不同类型的计算引擎(如Presto、Spark等)来执行,以提升用户体验(如响应时间快、可靠性高等)和资源利用率(CPU、内存等)。传统基于RBO/CBO的SQL优化框架,存在规则人工定制、统计信息缺失、历史流水闲置、失效资源浪费等几个主要问题。
针对这些问题,SuperSQL设计实现了基于历史负载的查询优化(History-Based Optimization,HBO)和基于机器学习的引擎选择。HBO目标是分析处理历史用户SQL流水,以通用、抽象化的HBO策略,增强补充(非取代)已有的具体化RBO/CBO策略。机器学习算法可以自动学习SQL特征,更好地弥补人为规则的黑角。把HBO和机器学习结合起来,可以更好地降低日均提效失败(即错误选择引擎后执行失败)的SQL数,提升用户SQL的平均执行时间,减少引擎集群无效负载的同时节省宝贵的计算资源。
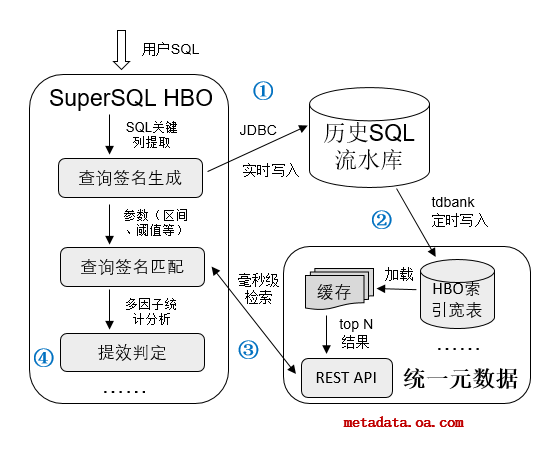
HBO框架的设计实现包括四个子模块,如下图中标示;它们也代表了一条用户SQL HBO优化的四个串行阶段。基于引擎选择(SQL优化)的实时性要求,整个HBO耗时必须控制在毫秒级。
-
查询签名:SuperSQL执行的所有计算类SQL语句(DQL/DML),无论执行结束后状态是成功还是失败,流水入库时都新增生成查询签名(Query Signature,QS)字段。
查询签名是SuperSQL自研设计的SQL文本的 “浓缩” 表示,包含SQL访问的库表名和关键子句(Filter/Join/GroupBy/Orderby)中包含的列名。SuperSQL通过QS来匹配判断当前用户SQL与哪些历史SQL “HBO等价”,然后通过分析汇总这些历史等价SQL的执行特征,来决定当前SQL是否应选某类引擎执行。 -
索引宽表:HBO要求为每个最新提交的用户SQL,从历史流水库中查找其最近一段时间内等价的历史SQL集。SuperSQL依赖外部的统一元数据服务,固化缓存HBO索引宽表来解决检索的实时性能问题。宽表的每一条记录对应一条历史SuperSQL查询,包括查询签名、执行时间、引擎类型、结果状态、数据量、引擎shuffle数据等信息。
-
历史检索:基于查询签名的完全匹配(exact match),调用统一元数据服务的REST API,返回最近历史区间(如一周)内的索引宽表记录集。SuperSQL通过不同的API入参,指定返回记录集的最大行数、起止日期、超时时间等属性,确保检索的实时性能(平均 < 100ms)。
-
提效判定:分析统计获取的历史记录集,综合执行时间、失败率、引擎分布等数据,对比系统阈值参数,决定是否对当前SQL选择使用的某类计算引擎来执行。
作为业务效果样例,根据对接SuperSQL的某数据分析中台的SQL流水统计,HBO加持的SuperSQL智能引擎选择,可以大幅减少因为引擎选择错误导致的SQL failver。HBO规避的SQL类别大都是超大资源占用、海量分区读写、大规模Join等高计算开销类,日均可减少Presto引擎 34TB 的无效内存占用以及 33小时 的无效CPU时间。
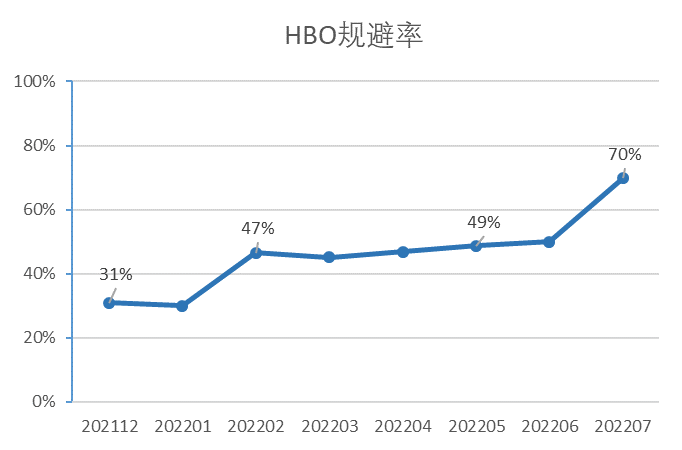
HBO不能覆盖所有的SQL场景,对于周期性任务较为有效,但如果用户提交了新的查询,签名和历史不匹配,则难以决策。机器学习可以自动学习SQL特征,很好地弥补规则的缺失。实践中,直接把SQL字符串作为原始数据,具体训练过程如下:
-
特征处理:使用自然语言处理中的n-gram TF-IDF方法,将文本转化为数值特征,供机器学习模型训练。具体做法为,将SQL语句按字符(或单词,字符效果更好)进行分割,相邻的1-5个字符构成一个元组,选取训练数据中出现频率最高的50万个元组,计算全部训练数据中对应元组的词频-逆文档词频(TF-IDF)值,从而将每个SQL语句转化为50万维的特征向量
-
特征选择。由于特征维度大,训练数据多,模型训练慢,因此对特征进行降维。使用基于模型的降维方法,先利用逻辑回归(LR)模型在数据上执行训练,之后逻辑回归模型会根据模型系数对特征给出重要性分析,选择最重要的1万维特征,供后续模型执行训练
-
模型训练。采用梯度提升树XGBoost拟合训练数据,数据特征为如上所述的1万维特征。由于数据类别分布不均(失衡),通过调节模型的类别权重参数,达到最优的拟合效果
机器学习可以进一步提升引擎选择的准确性,降低SQL failover率。基于内网的SQL流水测试,机器学习算法能够在HBO的基础上,SQL failover率降低60%。
计算运行时自适应:
实时捕捉环境变化,动态调整计算拓扑
传统的大数据架构下,整个计算链路通常是单向的,上层计算缺少底层状态(比如资源状态)的反馈。单向链路虽然简单,但会造成计算资源不均衡、资源利用不充分等问题。算力感知是自适应计算架构里底层反馈的桥梁,让上层计算具备感知资源状态的能力,进而自适应地调整资源使用。通过算力感知,可以获取计算资源整体的资源状态以及单节点详细的算力指标,上层计算借此自适应地动态调整计算决策、资源使用、任务调度等。
以Presto为例,作为一款典型的MPP架构、纯内存计算的交互式查询引擎,为了追求性能的最大化,Presto会尽可能地利用节点上可用的资源,包括CPU/内存/网络带宽等,节点间的物理资源规格也需要尽可能保持一致。然而在实际的使用场景中,节点的CPU/内存等负载(算力)是随时波动的,而Presto的原生任务调度策略并未将节点的算力考虑在内,导致在节点算力明显下降的情况下,计算任务会受到严重的影响,从而产生长尾问题。为此,天穹Presto做了针对性的优化,在动态的计算环境中,通过感知节点算力的变化,自适应地调整计算任务的调度,避免低算力节点的影响。
天穹Presto自适应任务调度主要分为:Task自适应调度与Split自适应调度,方案实现的核心思想是:根据节点的算力情况动态分配Split和Task,整体架构如下图所示:
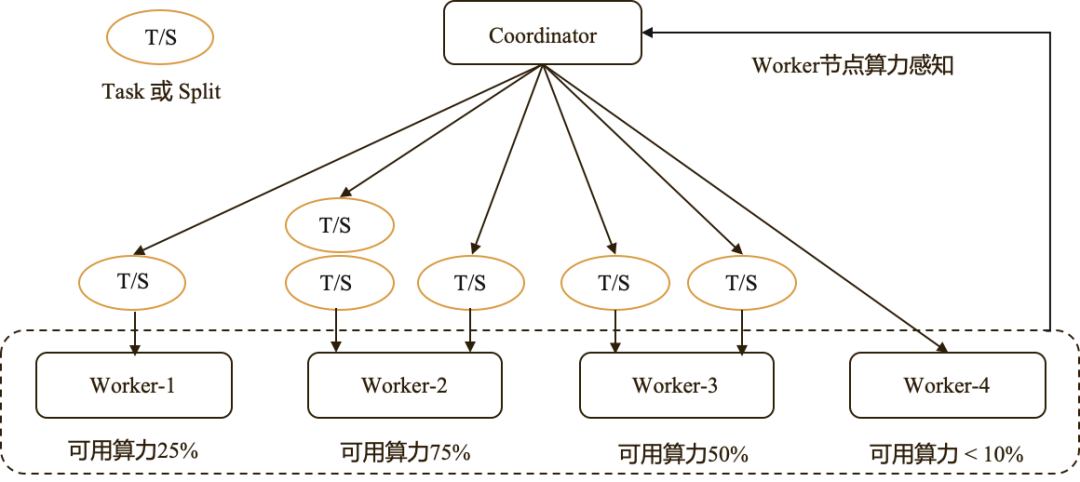
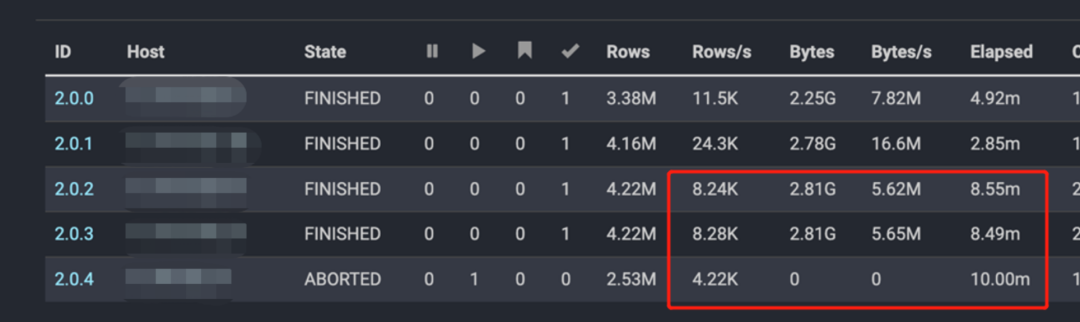
天穹Presto Coordiantor在运行过程中,会实时感知Worker节点的算力变化情况,同时计算出对应的节点可用算力权重,在Task和Split的调度过程中,针对不同的算力权重,根据模型计算出相应的Worker上还可分配的Task或Split数目,对于算力严重下降的节点,少分配或不分配Task或Split,尽量避免长尾问题,从而做到自适应的调度。自适应调度效果:当计算Task在CPU波动比较大的节点上,会造成明显的计算长尾的问题,拖慢整个任务的运行,如下图所示,在没有开始自适应调度的情况下,Task的执行时间波动很大。
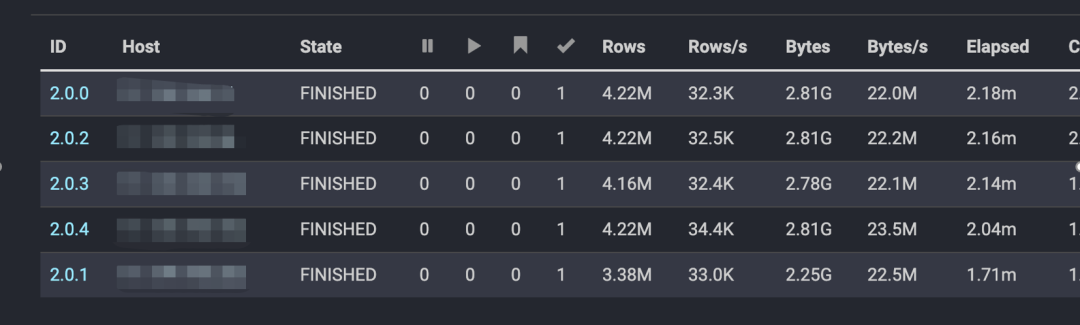
在开启自适应调度后,Task会避免调度到CPU算力差的节点,有效地消除长尾问题。如下图所示,Task的执行时间更加均衡,避免长尾问题影响整个计算任务的性能。
资源自适应:
资源统一池化,透明弹性伸缩
面向大规模集群部署,多集群是运维管理的常规手段。但从资源管理的角度,多集群会带来诸多问题:
-
资源对业务不透明,业务在使用计算资源时,需要人为指定特定集群。人为选择集群的方式不仅麻烦,也会带来集群负载不均衡的问题;
-
由于资源不能统筹管理,资源整体利用率不高。资源自适应的目标是把能够把所有资源统一管理起来,对计算提供统一的资源池,对资源统一调度,打破集群间的隔离问题,实现对资源的公平共享,充分利用空闲资源,提高资源利用率,同时对业务透明化。
资源自适应主要包括集群间弹性伸缩和集群内资源调度。每个租户对应一个虚拟K8S集群,每个租户都有最低的资源保障,租户之间能借用资源,也可以借用集群空闲资源。通过自适应调配资源,打破集群间的隔离,充分利用不同业务的潮汐效应,错峰使用资源,提升整体的资源利用率。

数据编排自适应:
融合异构存储,自动查询加速
在公有云、私有云、内网不同场景中,大数据底层存储是异构的,主要涉及COS、HDFS、Ceph、Ozone等。面向异构化的存储,统一融合计算平台构建了一层统一的数据编排层(DOP),位于计算和存储之间,透明化存储差异。通过适配不同的权限和认证体系的统一的存储Client,解耦计算和存储,避免不同计算引擎和不同存储间的相互适配工作,让计算和存储更加专注。
在大数据场景中,每天产生海量的数据,而数据治理往往赶不上数据积累的速度,海量元数据以及小文件会给存储Master节点(例如HDFS NameNode)极大压力,造成性能抖动。数据编排层会自适应缓存存储元数据,以及自动小文件合并,减轻Master节点压力,同时在跨DC数据访问时,加速元数据访问,提升数据访问速度。
数据编排层会针对不同的场景通过热数据缓存,加速计算性能。在内网的ad-hoc场景中,采用LRU/LRFU相结合的数据缓存策略,整体计算性能加速比2.6倍,而对于 IO 密集的SQL,加速达6.2倍。

场景架构自适应:
多元混合,架构统一
SuperSQL通过完善的数据下推、自研的跨DC CBO,可在多云混部架构中构建出最优的计算路径,实现更高效、更安全的数据分析。SuperSQL支持多云混合架构、跨DC、及跨云的联合数据分析,可打破数据孤岛,实现跨DC、跨云的数据访问链路,助力客户实现最大化的数据价值。在腾讯内部应用场景测试中,可以有效地降低跨DC高峰时段网络流量约30%。

总结 & 未来规划
未来SuperSQL会持续专注在统一融合计算平台中,打造更快、更稳定、更易用的大数据自适应智能计算架构,具体会在以下方向上持续探索潜力:
-
计算任务自适应优化:根据任务本身的特点和历史相似任务的执行状态,通过自动调整计算参数,提升计算任务的稳定性和资源的使用效率。
-
计算运行时自适应计算框架:构建灵活的自适应计算运行时框架,让引擎动态调整计算执行拓扑,更好地适配不同的计算场景和复杂的计算环境。
-
热点查询智能缓存:自动学习业务SQL查询的Pattern,自适应地构造视图物化不同SQL的共同查询结果,加速(周期性)SQL执行性能。
-
高性能融合分布式计算框架:构建属于腾讯的大数据融合计算框架,成为多种计算模式的解决方案,作为一个真正的原生的可扩展的分布式框架。实现用一套代码自动切换不同的计算引擎,解耦业务和底层大数据引擎的强关联。
 更多产品了解
更多产品了解
欢迎扫码加入云巴巴企业数字化交流服务群
产品交流、问题咨询、专业测评
都在这里!

为你推荐

2019大数据产业创新峰会,星环科技荣获创新金奖
2019年12月5日,由上海市经信委、上海市科委、静安区人民政府共同指导,上海大数据联盟主办的2019中国 (上海) 大数据产业创新峰会在静安隆重举行。会上,星环科技荣誉当选为上海市大数据联盟副主席,同时,斩获2019年度大数据产业技术创新金奖。2020-01-21 16:04:15

快来了解一下如何避免数据泄漏吧
随着可用数据在规模和复杂性上的不断增长,直接的“手动”数据分析被间接的、和自动数据处理所不断增强,而在这数据分析与数据挖掘的过程中,如何避免数据泄露也是十分重要的。 防止操作系统文件造成的数据泄漏,通常以明文形式将数据存储在操作系统文件中;益于计算机科学2022-11-22 16:39:15

艺赛旗iS-CDA与达梦数据库完成兼容性互认证,基于信创环境构建产业发展
iS-CDA桌面行为分析产品与达梦数据库管理系统V8能够相互兼容,系统运行稳定,性能表现优异。2024-03-27 10:29:50

你不知道的关于大数据的那些政策支持(一)
李克强总理签发过程中,2015年9月,国务院发布“关于推进大数据行动纲要的发展”(以下简称“纲要”),部署大数据系统的开发工作。 《纲要》明确,推动大数据技术发展和应用,建立企业运行进行平稳、安全管理高效的经济市场运行新机制,在未来5至10年打造一个精准2022-11-22 10:05:59

大数据技术助力抗击疫情,帮助城市恢复运转
近日,在国务院联防联控机制举行以“新冠肺炎的防控和医疗就治”为主题的消息宣布会上。中国工程院院士吴曼青表示,疫情时期,大数据技术在抗击疫情事情中发挥了积极的作用,吴曼青提出,针对支持企复工复产的各项事情,大数据技术起到了首要作用。2020-03-13 16:44:08

洞悉健康医疗市场需求,高效提升数据价值
大数据在医疗卫生领域的不断进行应用和发展,已为广大人民群众工作提供了优质、便捷的服务,也为医疗卫生健康教育领域的科技经济发展企业带来动力,特别是在新冠肺炎疫情背景下,各地卫健委为了能够更好的管理辖区内医疗服务机构运营情况。 着力将辖区内医疗信息数据统一2022-11-21 15:49:33
严选云产品









领先的企业数字化服务平台
客服电话:400-0972-788


评论列表