
庖丁解InnoDB数据库之UNDO LOG
来源: 云巴巴 2021-12-02 15:53:24Undo Log是InnoDB十分重要的组成部分,它的作用横贯InnoDB中两个最主要的部分,并发控制(Concurrency Control)和故障恢复(Crash Recovery),InnoDB中Undo Log的实现亦日志亦数据。本文将从其作用、设计思路、记录内容、组织结构,以及各种功能实现等方面,整体介绍InnoDB中的Undo Log,文章会深入一定的代码实现,但在细节上还是希望用抽象的实现思路代替具体的代码。本文基于MySQL 8.0,但在大多数的设计思路上MySQL的各个版本都是一致的。考虑到篇幅有限,以及避免过多信息的干扰,从而能够聚焦Undo Log本身的内容,本文中一笔带过或有意省略了一些内容,包括索引、事务系统、临时表、XA事务、Virtual Column、外部记录、Blob等。
一 Undo Log的作用
数据库故障恢复机制的前世今生中提到过,Undo Log用来记录每次修改之前的历史值,配合Redo Log用于故障恢复。这也就是InnoDB中Undo Log的第一个作用:
1 事务回滚
在设计数据库时,我们假设数据库可能在任何时刻,由于如硬件故障,软件Bug,运维操作等原因突然崩溃。这个时候尚未完成提交的事务可能已经有部分数据写入了磁盘,如果不加处理,会违反数据库对Atomic的保证,也就是任何事务的修改要么全部提交,要么全部取消。针对这个问题,直观的想法是等到事务真正提交时,才能允许这个事务的任何修改落盘,也就是No-Steal策略。显而易见,这种做法一方面造成很大的内存空间压力,另一方面提交时的大量随机IO会极大的影响性能。因此,数据库实现中通常会在正常事务进行中,就不断的连续写入Undo Log,来记录本次修改之前的历史值。当Crash真正发生时,可以在Recovery过程中通过回放Undo Log将未提交事务的修改抹掉。InnoDB采用的就是这种方式。
既然已经有了在Crash Recovery时支持事务回滚的Undo Log,自然地,在正常运行过程中,死锁处理或用户请求的事务回滚也可以利用这部分数据来完成。
2 MVCC(Multi-Versioin Concurrency Control)
浅析数据库并发控制机制中提到过,为了避免只读事务与写事务之间的冲突,避免写操作等待读操作,几乎所有的主流数据库都采用了多版本并发控制(MVCC)的方式,也就是为每条记录保存多份历史数据供读事务访问,新的写入只需要添加新的版本即可,无需等待。InnoDB在这里复用了Undo Log中已经记录的历史版本数据来满足MVCC的需求。
二 什么样的Undo Log
庖丁解InnoDB之REDO LOG中讲过的基于Page的Redo Log可以更好的支持并发的Redo应用,从而缩短DB的Crash Recovery时间。而对于Undo Log来说,InnoDB用Undo Log来实现MVCC,DB运行过程中是允许有历史版本的数据存在的。因此,Crash Recovery时利用Undo Log的事务回滚完全可以在后台,像正常运行的事务一样异步回滚,从而让数据库先恢复服务。因此,Undo Log的设计思路不同于Redo Log,Undo Log需要的是事务之间的并发,以及方便的多版本数据维护,其重放逻辑不希望因DB的物理存储变化而变化。因此,InnoDB中的Undo Log采用了基于事务的Logical Logging的方式。
同时,更多的责任意味着更复杂的管理逻辑,InnoDB中其实是把Undo当做一种数据来维护和使用的,也就是说,Undo Log日志本身也像其他的数据库数据一样,会写自己对应的Redo Log,通过Redo Log来保证自己的原子性。因此,更合适的称呼应该是Undo Data。
三 Undo Record中的内容
每当InnoDB中需要修改某个Record时,都会将其历史版本写入一个Undo Log中,对应的Undo Record是Update类型。当插入新的Record时,还没有一个历史版本,但为了方便事务回滚时做逆向(Delete)操作,这里还是会写入一个Insert类型的Undo Record。
1 Insert类型的Undo Record
这种Undo Record在代码中对应的是TRX_UNDO_INSERT_REC类型。不同于Update类型的Undo Record,Insert Undo Record仅仅是为了可能的事务回滚准备的,并不在MVCC功能中承担作用。因此只需要记录对应Record的Key,供回滚时查找Record位置即可。

其中Undo Number是Undo的一个递增编号,Table ID用来表示是哪张表的修改。下面一组Key Fields的长度不定,因为对应表的主键可能由多个field组成,这里需要记录Record完整的主键信息,回滚的时候可以通过这个信息在索引中定位到对应的Record。除此之外,在Undo Record的头尾还各留了两个字节用户记录其前序和后继Undo Record的位置。
2 Update类型的Undo Record
由于MVCC需要保留Record的多个历史版本,当某个Record的历史版本还在被使用时,这个Record是不能被真正的删除的。因此,当需要删除时,其实只是修改对应Record的Delete Mark标记。对应的,如果这时这个Record又重新插入,其实也只是修改一下Delete Mark标记,也就是将这两种情况的delete和insert转变成了update操作。再加上常规的Record修改,因此这里的Update Undo Record会对应三种Type:TRX_UNDO_UPD_EXIST_REC、TRX_UNDO_DEL_MARK_REC和TRX_UNDO_UPD_DEL_REC。他们的存储内容也类似:
除了跟Insert Undo Record相同的头尾信息,以及主键Key Fileds之外,Update Undo Record增加了:
-
Transaction Id记录了产生这个历史版本事务Id,用作后续MVCC中的版本可见性判断
-
Rollptr指向的是该记录的上一个版本的位置,包括space number,page number和page内的offset。沿着Rollptr可以找到一个Record的所有历史版本。
-
Update Fields中记录的就是当前这个Record版本相对于其之后的一次修改的Delta信息,包括所有被修改的Field的编号,长度和历史值。
四 Undo Record的组织方式
上面介绍了一个Undo Record中的存放的内容,每一次的修改都会产生至少一个Undo Record,那么大量Undo Record如何组织起来,来支持高效的访问和管理呢,这一小节我们将从几个层面来进行介绍:首先是在不考虑物理存储的情况下的逻辑组织方式;之后,物理组织方式介绍如何将其存储到到实际16KB物理块中;然后文件组织方式介绍整体的文件结构;最后再介绍其在内存中的组织方式。
1 逻辑组织方式 - Undo Log
每个事务其实会修改一组的Record,对应的也就会产生一组Undo Record,这些Undo Record收尾相连就组成了这个事务的Undo Log。除了一个个的Undo Record之外,还在开头增加了一个Undo Log Header来记录一些必要的控制信息,因此,一个Undo Log的结构如下所示:

Undo Log Header中记录了产生这个Undo Log的事务的Trx ID;Trx No是事务的提交顺序,也会用这个来判断是否能Purge,这个在后面会详细介绍;Delete Mark标明该Undo Log中有没有TRX_UNDO_DEL_MARK_REC类型的Undo Record,避免Purge时不必要的扫描;Log Start Offset中记录Undo Log Header的结束位置,方便之后Header中增加内容时的兼容;之后是一些Flag信息;Next Undo Log及Prev Undo Log标记前后两个Undo Log,这个会在接下来介绍;最后通过History List Node将自己挂载到为Purge准备的History List中。
索引中的同一个Record被不同事务修改,会产生不同的历史版本,这些历史版本又通过Rollptr穿成一个链表,供MVCC使用。
示例中有三个事务操作了表t上,主键id是1的记录,首先事务I插入了这条记录并且设置filed a的值是A,之后事务J和事务K分别将这条id为1的记录中的filed a的值修改为了B和C。I,J,K三个事务分别有自己的逻辑上连续的三条Undo Log,每条Undo Log有自己的Undo Log Header。从索引中的这条Record沿着Rollptr可以依次找到这三个事务Undo Log中关于这条记录的历史版本。同时可以看出,Insert类型Undo Record中只记录了对应的主键值:id=1,而Update类型的Undo Record中还记录了对应的历史版本的生成事务Trx_id,以及被修改的field a的历史值。
2 物理组织格式 - Undo Segment
上面描述了一个Undo Log的结构,一个事务会产生多大的Undo Log本身是不可控的,而最终写入磁盘却是按照固定的块大小为单位的,InnoDB中默认是16KB,那么如何用固定的块大小承载不定长的Undo Log,以实现高效的空间分配、复用,避免空间浪费。InnoDB的基本思路是让多个较小的Undo Log紧凑存在一个Undo Page中,而对较大的Undo Log则随着不断的写入,按需分配足够多的Undo Page分散承载。下面我们就看看这部分的物理存储方式:
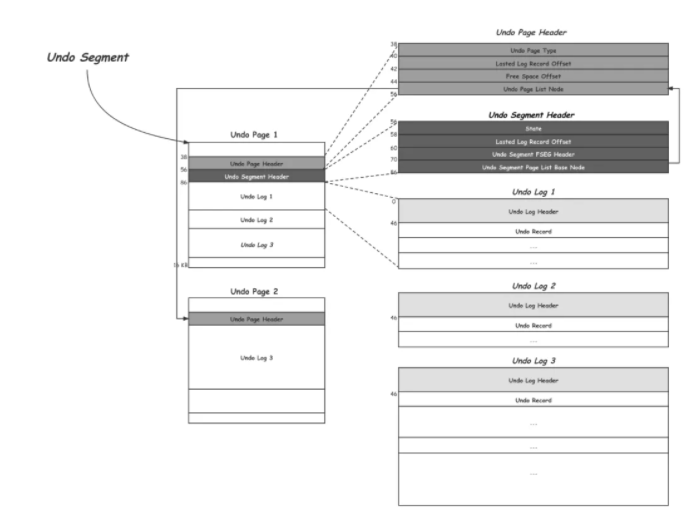
如上所示,是一个Undo Segment的示意图,每个写事务开始写操作之前都需要持有一个Undo Segment,一个Undo Segment中的所有磁盘空间的分配和释放,也就是16KB Page的申请和释放,都是由一个FSP的Segment管理的,这个跟索引中的Leaf Node Segment和Non-Leaf Node Segment的管理方式是一致的,这部分之后会有单独的文章来进行介绍。
Undo Segment会持有至少一个Undo Page,每个Undo Page会在开头38字节到56字节记录Undo Page Header,其中记录Undo Page的类型、最后一条Undo Record的位置,当前Page还空闲部分的开头,也就是下一条Undo Record要写入的位置。Undo Segment中的第一个Undo Page还会在56字节到86字节记录Undo Segment Header,这个就是这个Undo Segment中磁盘空间管理的Handle;其中记录的是这个Undo Segment的状态,比如TRX_UNDO_CACHED、TRX_UNDO_TO_PURGE等;这个Undo Segment中最后一条Undo Record的位置;这个FSP Segment的Header,以及当前分配出来的所有Undo Page的链表。
Undo Page剩余的空间都是用来存放Undo Log的,对于像上图Undo Log 1,Undo Log 2这种较短的Undo Log,为了避免Page内的空间浪费,InnoDB会复用Undo Page来存放多个Undo Log,而对于像Undo Log 3这种比较长的Undo Log可能会分配多个Undo Page来存放。需要注意的是Undo Page的复用只会发生在第一个Page。
3 文件组织方式 - Undo Tablespace
每一时刻一个Undo Segment都是被一个事务独占的。每个写事务都会持有至少一个Undo Segment,当有大量写事务并发运行时,就需要存在多个Undo Segment。InnoDB中的Undo 文件中准备了大量的Undo Segment的槽位,按照1024一组划分为Rollback Segment。每个Undo Tablespace最多会包含128个Rollback Segment,Undo Tablespace文件中的第三个Page会固定作为这128个Rollback Segment的目录,也就是Rollback Segment Arrary Header,其中最多会有128个指针指向各个Rollback Segment Header所在的Page。Rollback Segment Header是按需分配的,其中包含1024个Slot,每个Slot占四个字节,指向一个Undo Segment的First Page。除此之前还会记录该Rollback Segment中已提交事务的History List,后续的Purge过程会顺序从这里开始回收工作。
可以看出Rollback Segment的个数会直接影响InnoDB支持的最大事务并发数。MySQL 8.0由于支持了最多127个独立的Undo Tablespace,一方面避免了ibdata1的膨胀,方便undo空间回收,另一方面也大大增加了最大的Rollback Segment的个数,增加了可支持的最大并发写事务数。
4 内存组织结构
上面介绍的都是Undo数据在磁盘上的组织结构,除此之外,在内存中也会维护对应的数据结构来管理Undo Log
对应每个磁盘Undo Tablespace会有一个undo::Tablespace的内存结构,其中最主要的就是一组trx_rseg_t的集合,trx_rseg_t对应的就是上面介绍过的一个Rollback Segment Header,除了一些基本的元信息之外,trx_rseg_t中维护了四个trx_undo_t的链表,Update List中是正在被使用的用于写入Update类型Undo的Undo Segment;Update Cache List中是空闲空间比较多,可以被后续事务复用的Update类型Undo Segment;对应的,Insert List和Insert Cache List分别是正在使用中的Insert类型Undo Segment,和空间空间较多,可以被后续复用的Insert类型Undo Segment。因此trx_undo_t对应的就是上面介绍过的Undo Segment。接下来,我们就从Undo的写入、Undo用于Rollback、MVCC、Crash Recovery以及如何清理Undo等方面来介绍InnoDB中Undo的角色和功能。
五 Undo的写入
当写事务开始时,会先通过trx_assign_rseg_durable分配一个Rollback Segment,该事务的内存结构trx_t也会通过rsegs指针指向对应的trx_rseg_t内存结构,这里的分配策略很简单,就是依次尝试下一个Active的Rollback Segment。之后当第一次真正产生修改需要写Undo Record的时,会调用trx_undo_assign_undo来获得一个Undo Segment。这里会优先复用trx_rseg_t上Cached List中的trx_undo_t,也就是已经分配出来但没有被正在使用的Undo Segment,如果没有才调用trx_undo_create创建新的Undo Segment,trx_undo_create中会轮询选择当前Rollback Segment中可用的Slot,也是就值FIL_NUL的Slot,申请新的Undo Page,初始化Undo Page Header,Undo Segment Header等信息,创建新的trx_undo_t内存结构并挂到trx_rseg_t的对应List中。
获得了可用的Undo Segment之后,该事务会在合适的位置初始化自己的Undo Log Header,之后,其所有修改产生的Undo Record都会顺序的通过trx_undo_report_row_operation顺序的写入当前的Undo Log,其中会根据是insert还是update类型,分别调用trx_undo_page_report_insert或者trx_undo_page_report_modify。本文开始已经介绍过了具体的Undo Record内容。简单的讲,insert类型会记录插入Record的主键,update类型除了记录主键以外还会有一个update fileds记录这个历史值跟索引值的diff。之后指向当前Undo Record位置的Rollptr会返回写入索引的Record上。
当一个Page写满后,会调用trx_undo_add_page来在当前的Undo Segment上添加新的Page,新Page写入Undo Page Header之后继续供事务写入Undo Record,为了方便维护,这里有一个限制就是单条Undo Record不跨page,如果当前Page放不下,会将整个Undo Record写入下一个Page。
当事务结束(commit或者rollback)之后,如果只占用了一个Undo Page,且当前Undo Page使用空间小于page的3/4,这个Undo Segment会保留并加入到对应的insert/update cached list中。否则,insert类型的Undo Segment会直接回收,而update类型的Undo Segment会等待后台的Purge做完后回收。根据不同的情况,Undo Segment Header中的State会被从TRX_UNDO_ACTIVE改成TRX_UNDO_TO_FREE,TRX_UNDO_TO_PURGE或TRX_UNDO_CACHED,这个修改其实就是InnoDB的事务结束的标志,无论是Rollback还是Commit,在这个修改对应的Redo落盘之后,就可以返回用户结果,并且Crash Recovery之后也不会再做回滚处理。
六 Undo for Rollback
InnoDB中的事务可能会由用户主动触发Rollback;也可能因为遇到死锁异常Rollback;或者发生Crash,重启后对未提交的事务回滚。在Undo层面来看,这些回滚的操作是一致的,基本的过程就是从该事务的Undo Log中,从后向前依次读取Undo Record,并根据其中内容做逆向操作,恢复索引记录。
回滚的入口是函数row_undo,其中会先调用trx_roll_pop_top_rec_of_trx获取并删除该事务的最后一条Undo Record。如下图例子中的Undo Log包括三条Undo Records,其中Record 1在Undo Page 1中,Record 2,3在Undo Page 2中,先通过从Undo Segment Header中记录的Page List找到当前事务的最后一个Undo Page的Header,并根据Undo Page 2的Header上记录的Free Space Offset定位最后一条Undo Record结束的位置,当然实际运行时,这两个值是缓存在trx_undo_t的top_page_no和top_offset中的。利用Prev Record Offset可以找到Undo Record 3,做完对应的回滚操作之后,再通过前序指针Prev Record Offset找到前一个Undo Record,依次进行处理。处理完当前Page中的所有Undo Records后,再沿着Undo Page Header中的List找到前一个Undo Page,重复前面的过程,完成一个事务所有Page上的所有Undo Records的回滚。
拿到一个Undo Record之后,自然地,就是对其中内容的解析,这里会调用row_undo_ins_parse_undo_rec,从Undo Record中获取修改行的table,解析出其中记录的主键信息,如果是update类型,还会拿到一个update vector记录其相对于更新的一个版本的变化。
TRX_UNDO_INSERT_REC类型的Undo回滚在row_undo_ins中进行,insert的逆向操作当然就是delete,根据从Undo Record中解析出来的主键,用row_undo_search_clust_to_pcur定位到对应的ROW, 分别调用row_undo_ins_remove_sec_rec和row_undo_ins_remove_clust_rec在二级索引和主索引上将当前行删除。
update类型的undo包括TRX_UNDO_UPD_EXIST_REC,TRX_UNDO_DEL_MARK_REC和TRX_UNDO_UPD_DEL_REC三种情况,他们的Undo回滚都是在row_undo_mod中进行,首先会调用row_undo_mod_del_unmark_sec_and_undo_update,其中根据从Undo Record中解析出的update vector来回退这次操作在所有二级索引上的影响,可能包括重新插入被删除的二级索引记录、去除其中的Delete Mark标记,或者用update vector中的diff信息将二级索引记录修改之前的值。之后调用row_undo_mod_clust同样利用update vector中记录的diff信息将主索引记录修改回之前的值。
完成回滚的Undo Log部分,会调用trx_roll_try_truncate进行回收,对不再使用的page调用trx_undo_free_last_page将磁盘空间交还给Undo Segment,这个是写入过程中trx_undo_add_page的逆操作。
七 Undo for MVCC
多版本的目的是为了避免写事务和读事务的互相等待,那么每个读事务都需要在不对Record加Lock的情况下, 找到对应的应该看到的历史版本。所谓历史版本就是假设在该只读事务开始的时候对整个DB打一个快照,之后该事务的所有读请求都从这个快照上获取。当然实现上不能真正去为每个事务打一个快照,这个时间空间都太高了。InnoDB的做法,是在读事务第一次读取的时候获取一份ReadView,并一直持有,其中记录所有当前活跃的写事务ID,由于写事务的ID是自增分配的,通过这个ReadView我们可以知道在这一瞬间,哪些事务已经提交哪些还在运行,根据Read Committed的要求,未提交的事务的修改就是不应该被看见的,对应地,已经提交的事务的修改应该被看到。
作为存储历史版本的Undo Record,其中记录的trx_id就是做这个可见性判断的,对应的主索引的Record上也有这个值。当一个读事务拿着自己的ReadView访问某个表索引上的记录时,会通过比较Record上的trx_id确定是否是可见的版本,如果不可见就沿着Record或Undo Record中记录的rollptr一路找更老的历史版本。如下图所示,事务R开始需要查询表t上的id为1的记录,R开始时事务I已经提交,事务J还在运行,事务K还没开始,这些信息都被记录在了事务R的ReadView中。事务R从索引中找到对应的这条Record[1, C],对应的trx_id是K,不可见。沿着Rollptr找到Undo中的前一版本[1, B],对应的trx_id是J,不可见。继续沿着Rollptr找到[1, A],trx_id是I可见,返回结果。
前面提到过,作为Logical Log,Undo中记录的其实是前后两个版本的diff信息,而读操作最终是要获得完整的Record内容的,也就是说这个沿着rollptr指针一路查找的过程中需要用Undo Record中的diff内容依次构造出对应的历史版本,这个过程在函数row_search_mvcc中,其中trx_undo_prev_version_build会根据当前的rollptr找到对应的Undo Record位置,这里如果是rollptr指向的是insert类型,或者找到了已经Purge了的位置,说明到头了,会直接返回失败。否则,就会解析对应的Undo Record,恢复出trx_id、指向下一条Undo Record的rollptr、主键信息,diff信息update vector等信息。之后通过row_upd_rec_in_place,用update vector修改当前持有的Record拷贝中的信息,获得Record的这个历史版本。之后调用自己ReadView的changes_visible判断可见性,如果可见则返回用户。完成这个历史版本的读取。
八 Undo for Crash Recovery
Crash Recovery时,需要利用Undo中的信息将未提交的事务的所有影响回滚,以保证数据库的Failure Atomic。前面提到过,InnoDB中的Undo其实是像数据一样处理的,也从上面的组织结构中可以看出来,Undo本身有着比Redo Log复杂得多、按事务分配而不是顺序写入的组织结构,其本身的Durability像InnoDB中其他的数据一样,需要靠Redo来保证,像庖丁解InnoDB之REDO LOG中介绍的那样。除了通用的一些MLOG_2BYTES、MLOG_4BYTES类型之外,Undo本身也有自己对应的Redo Log类型:MLOG_UNDO_INIT类型在Undo Page舒适化的时候记录初始化;在分配Undo Log的时候,需要重用Undo Log Header或需要创建新的Undo Log Header的时候,会分别记录MLOG_UNDO_HDR_REUSE和MLOG_UNDO_HDR_CREATE类型的Redo Record;MLOG_UNDO_INSERT是最常见的,在Undo Log里写入新的Undo Record都对应的写这个日志记录写入Undo中的所有内容;最后,MLOG_UNDO_ERASE_END 对应Undo Log跨Undo Page时抹除最后一个不完整的Undo Record的操作。
如数据库故障恢复机制的前世今生中讲过的ARIES过程,Crash Recovery的过程中会先重放所有的Redo Log,整个Undo的磁盘组织结构,也会作为一种数据类型也会通过上面讲到的这些Redo类型的重放恢复出来。之后在trx_sys_init_at_db_start中会扫描Undo的磁盘结构,遍历所有的Rollback Segment和其中所有的Undo Segment,通过读取Undo Segment Header中的State,可以知道在Crash前,最后持有这个Undo Segment的事务状态。如果是TRX_UNDO_ACTIVE,说明当时事务需要回滚,否则说明事务已经结束,可以继续清理Undo Segment的逻辑。之后,就可以恢复出Undo Log的内存组织模式,包括活跃事务的内存结构trx_t,Rollback Segment的内存结构trx_rseg_t,以及其中的trx_undo_t的四个链表。
Crash Recovery完成之前,会启动在srv_dict_recover_on_restart中启动异步回滚线程trx_recovery_rollback_thread,其中对Crash前还活跃的事务,通过trx_rollback_active进行回滚,这个过程跟上面提到的Undo for Rollback是一致的。
九 Undo的清理
我们已经知道,InnoDB在Undo Log中保存了多份历史版本来实现MVCC,当某个历史版本已经确认不会被任何现有的和未来的事务看到的时候,就应该被清理掉。因此就需要有办法判断哪些Undo Log不会再被看到。InnoDB中每个写事务结束时都会拿一个递增的编号trx_no作为事务的提交序号,而每个读事务会在自己的ReadView中记录自己开始的时候看到的最大的trx_no为m_low_limit_no。那么,如果一个事务的trx_no小于当前所有活跃的读事务Readview中的这个m_low_limit_no,说明这个事务在所有的读开始之前已经提交了,其修改的新版本是可见的, 因此不再需要通过undo构建之前的版本,这个事务的Undo Log也就可以被清理了。如下图所所以,由于ReadView List中最老的ReadView在获取时,Transaction J就已经Commit,因此所有的读事务都一定能被Index中的版本或者第一个Undo历史版本满足,不需要更老的Undo,因此整个Transaction J的Undo Log都可以清理了。
Undo的清理工作是由专门的后台线程srv_purge_coordinator_thread进行扫描和分发, 并由多个srv_worker_thread真正清理的。coordinator会首先在函数trx_purge_attach_undo_recs中扫描innodb_purge_batch_size配置个Undo Records,作为一轮清理的任务分发给worker。
1 扫描一批要清理Undo Records
事务结束的时候,对于需要Purge的Update类型的Undo Log,会按照事务提交的顺序trx_no,挂载到Rollback Segment Header的History List上。Undo Log回收的基本思路,就是按照trx_no从小到大,依次遍历所有Undo Log进行清理操作。前面介绍了,InnoDB中有多个Rollback Segment,那么就会有多个History List,每个History List内部事务有序,但还需要从多个History List上找一个trx_no全局有序的序列,如下图所示:
图中的事务编号是按照InnoDB这里引入了一个堆结构purge_queue,用来依次从所有History List中找到下一个拥有最小trx_no的事务。purge_queue中记录了所有等待Purge的Rollback Segment和其History中trx_no最小的事务,trx_purge_choose_next_log依次从purge_queue中pop出拥有全局最小trx_no的Undo Log。调用trx_purge_get_next_rec遍历对应的Undo Log,处理每一条Undo Record。之后继续调用trx_purge_rseg_get_next_history_log从purge_queue中获取下一条trx_no最小的Undo Log,并且将当前Rollback Segment上的下一条Undo Log继续push进purge_queue,等待后续的顺序处理。对应上图的处理过程和对应的函数调用,如下图所示:
[trx_purge_choose_next_log] Pop T1 from purge_queue;[trx_purge_get_next_rec] Iterator T1;[trx_purge_rseg_get_next_history_log] Get T1 next: T5;[trx_purge_choose_next_log] Push T5 into purge_queue;
[trx_purge_choose_next_log] Pop T4 from purge_queue;[trx_purge_get_next_rec] Iterator T4;[trx_purge_rseg_get_next_history_log] Get T4 next: ...;[trx_purge_choose_next_log] Push ... into purge_queue;
[trx_purge_choose_next_log] Pop T5 from purge_queue;[trx_purge_get_next_rec] Iterator T5;[trx_purge_rseg_get_next_history_log] Get T5 next: T6;[trx_purge_choose_next_log] Push T6 into purge_queue;......
其中,trx_purge_get_next_rec会从上到下遍历一个Undo Log中的所有Undo Record,这个跟前面讲过的Rollback时候从下到上的遍历方向是相反的,还是以同样的场景为例,要Purge的Undo Log横跨两个Undo Page,Undo Record 1在Page 1中,而Undo Record 2,3在Page 2中。如下图所示,首先会从当前的Undo Log Header中找到第一个Undo Record的位置Log Start Offset,处理完Undo Record1之后沿着Next Record Offset去找下一个Undo Record,当找到Page末尾时,要通过Page List Node找下一个Page,找到Page内的第一个Undo Record,重复上面的过程直到找出所有的Undo Record。
对每个要Purge的Undo Record,在真正删除它本身之前,可能还需要处理一些索引上的信息,这是由于正常运行过程中,当需要删除某个Record时,为了保证其之前的历史版本还可以通过Rollptr找到,Record是没有真正删除的,只是打了Delete Mark的标记,并作为一种特殊的Update操作记录了Undo Record。那么在对应的TRX_UNDO_DEL_MARK_REC类型的Undo Record被清理之前,需要先从索引上真正地删除这个Delete Mark的记录。因此Undo Record的清理工作会分为两个过程:
-
TRX_UNDO_DEL_MARK_REC类型Undo Record对应的Record的真正删除,称为Undo Purge;
-
以及Undo Record本身从旧到新的删除,称为Undo Truncate。
除此之外,当配置的独立Undo Tablespace大于两个的时候,InnoDB支持通过重建来缩小超过配置大小的Undo Tablespace:
-
Undo Tablespace的重建缩小,称为Undo Tablespace Truncate
2 Undo Purge
这一步主要针对的是TRX_UNDO_DEL_MARK_REC类型的Undo Record,用来真正的删除索引上被标记为Delete Mark的Record。worker线程会在row_purge函数中,循环处理coordinator分配来的每一个Undo Records,先通过row_purge_parse_undo_rec,依次从Undo Record中解析出type、table_id、rollptr、对应记录的主键信息以及update vector。之后,针对TRX_UNDO_DEL_MARK_REC类型,调用row_purge_remove_sec_if_poss将需要删除的记录从所有的二级索引上删除,调用row_purge_remove_clust_if_poss从主索引上删除。另外,TRX_UNDO_UPD_EXIST_REC类型的Undo虽然不涉及主索引的删除,但可能需要做二级索引的删除,也是在这里处理的。
3 Undo Truncate
coordinator线程会等待所有的worker完成一批Undo Records的Purge工作,之后尝试清理不再需要的Undo Log,trx_purge_truncate函数中会遍历所有的Rollback Segment中的所有Undo Segment,如果其状态是TRX_UNDO_TO_PURGE,调用trx_purge_free_segment释放占用的磁盘空间并从History List中删除。否则,说明该Undo Segment正在被使用或者还在被cache(TRX_UNDO_CACHED类型),那么只通过trx_purge_remove_log_hd将其从History List中删除。
需要注意的是,Undo Truncate的动作并不是每次都会进行的,它的频次是由参数innodb_rseg_truncate_frequency控制的,也就是说要攒innodb_rseg_truncate_frequency个batch才进行一次,前面提到每一个batch中会处理innodb_purge_batch_size个Undo Records,这也就是为什么我们从show engine innodb status中看到的Undo History List的缩短是跳变的。
4 Undo Tablespace Truncate
如果innodb_trx_purge_truncate配置打开,在函数trx_purge_truncate中还会去尝试重建Undo Tablespaces以缩小文件空间占用。Undo Truncate之后,会在函数trx_purge_mark_undo_for_truncate中扫描所有的Undo Tablespace,文件大小大于配置的innodb_max_undo_log_size的Tablespace会被标记为inactive,每一时刻最多有一个Tablespace处于inactive,inactive的Undo Tablespace上的所有Rollback Segment都不参与给新事物的分配,等该文件上所有的活跃事务退出,并且所有的Undo Log都完成Purge之后,这个Tablespace就会被通过trx_purge_initiate_truncate重建,包括重建Undo Tablespace中的文件结构和内存结构,之后被重新标记为active,参与分配给新的事务使用。
十 总结
本文首先概括地介绍了Undo Log的角色,之后介绍了一个Undo Record中的内容,紧接着介绍它的逻辑组织方式、物理组织方式、文件组织方式以及内存组织方式,详细描述了Undo Tablespace、Rollback Segment、Undo Segment、Undo Log和Undo Record的之间的关系和层级。这些组织方式都是为了更好的使用和维护Undo信息。最后在此基础上,介绍了Undo在各个重要的DB功能中的作用和实现方式,包括事务回滚、MVCC、Crash Recovery、Purge等。
 更多产品了解
更多产品了解
欢迎扫码加入云巴巴企业数字化交流服务群
产品交流、问题咨询、专业测评
都在这里!

为你推荐

10个关于数据库设计的最佳实践(上)
上篇文章中,小编已经讲了为什么数据库的设计是非常重要的,本位就来和朋友们介绍几个个关于数据库设计的最佳实践。 将所有人的观点列入考量 为了设计一个良好的数据库,必须考虑到所有相关利益攸关方的意见。建立数据库之前,去收集有关他们所期望的数据库和数据库的操2022-11-22 15:47:31

金融业务数字化,关键在于不断的数据库创新
TDSQL是腾讯云打造的一款企业级分布式数据库产品,其自研的金融级新敏态引擎支持无限扩展、在线变更,可以完美解决对于敏态业务发展过程中业务形态、业务量的不可预知性,适配金融敏态业务。2024-03-27 13:55:08

你的数据库“云原生”了吗?
TDSQL-C 是腾讯自研的云原生分布式数据库(原CynosDB), 基于共享存储,实现了强大的扩展能力和超百万级QPS的高吞吐性能。2022-03-31 19:58:26

据说数据库也去中心化,关于分布式数据库
带您了解“分布式数据库”。 通过云计算的新技术的推动下,大数据,越来越多的大型企业需要在管理查询,分析,处理和更新结构的数据。2020-04-16 17:39:37

世界级的业务压力的产品,云数据库
众所周知,我们生活在一个动态的世界里,面临很多困难。我们只能面对他们,所迈出的第一步路是关键,阿里云云数据库这个产品和阿里旗下的很多产品/服务一样,首先来自阿里自己的需求,然后产品成熟后经过阿里自己的验证才对外输出。 云数据库产品最早源于,2020-04-28 17:28:23
严选云产品







领先的企业数字化服务平台
客服电话:400-0972-788


评论列表