






 首页
首页基于智能文档处理的招投标信息自动抓取和匹配RPA
智能文档处理(Intelligent Document Processing,简称 IDP)是来也科技智能自动化平台的核心能力之一。IDP 基于光学字符识别(OCR)、计算机视觉(CV)、自然语言处理(NLP)、知识图谱(KG)等前沿技术,对各类文档进行识别、分类、抽取、校验等处理,帮助企业实现文档处理工作的智能化和自动化。本文介绍 IDP 的一个典型应用场景,即利用智能文档处理对大量的招投标文档进行自动抓取、分析和匹配。
背景
工程项目在招标时,通常会在各省市的公共资源交易中心网站上公开发布招标公告,公告内包含对项目信息的基本说明和对投标公司的要求等。有投标意向的公司需要专业的员工去筛选有价值招标公告去投标,但是全国每天有大量(数千篇)新发布的招标公告,公告内包含大量的领域专业信息,形式多种多样(包含段落、列表和表格),因此对于筛选的员工来说压力巨大,需要大量的有经验的员工才能完成。
来也科技的智能文档处理产品基于自然语言处理(NLP)、光学字符识别(OCR)等技术,对海量的招标公告进行结构化处理,提炼出项目信息和投标要求,自动过滤与公司拥有的资质、历史业绩与公告要求不匹配的公告,大幅度减少了市场人员需要阅读的公告数量,减轻基层工作人员的负担。

解决方案
招投标公告通常由各招标单位自行发布在当地的公共资源交易中心、行业招投标等网站上,具有来源众多、文档结构各异、文档形式多样(Word/PDF/HTML/扫描图片等)的特点。如果仅仅通过解析 HTML 的 DOM 结构的方式进行文档的解析,信息提取的效果并不理想,针对不同网站或文档的适应性也很差。
为了尽可能让方案通用,来也科技通过 RPA 机器人将所有招标文档转换为 PDF 文档,然后利用 OCR 技术识别文档内容和结构信息,最后使用 NLP 技术对文档内容进行解析,形成 RPA+OCR+NLP 的智能文档处理解决方案。来也科技的招投标智能文档处理系统分为公告抓取、信息抽取、业务决策三个大的环节。
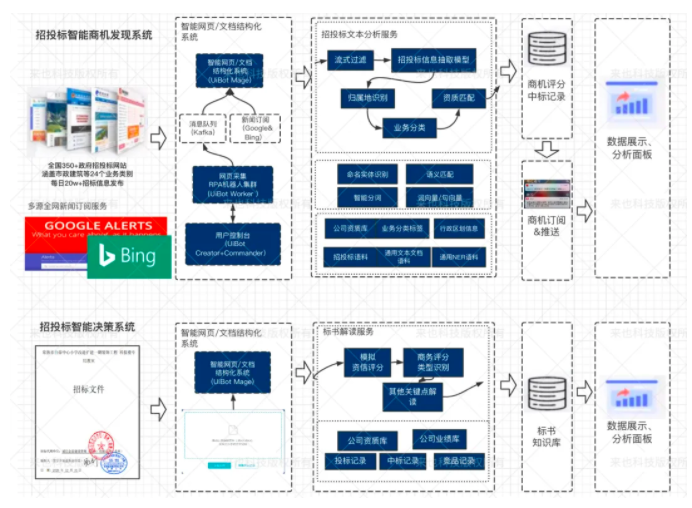
公告抓取
在招标公告抓取方面,我们搭建了面向重点信息来源(如中国政府采购网、公共资源交易网和各地区及行业核心招投标网站)的采集机器人,去实时采集建筑工程类招标公告、标书、中标公告 3 种文档,确保数据全量覆盖,随时掌握最新商机。使用来也科技的 RPA 工具搭建的采集机器人,具有低代码、易维护的优点,并且通过来也科技的人机协同中心,可做到人工抽检、流程快速干预,解决了以往数据抓取必须由专业人员维护的难点。

信息抽取
抓取到的公告经过 OCR 得到文档包含的内容和结构信息后,就可以开始进行信息抽取了。招标公告一般包含多种结构(段落、列表、表格等),每个省市的格式也各有差异,内容由自然语言描述构成,再加上需要抽取的字段多达近 20 个,因此信息抽取的挑战十分巨大。因此需要大量的标注数据来训练深度学习模型。

为了应对上述难点,我们采用了深度学习+领域专家经验组合的抽取方案。深度学习模型方面我们基于大量招标公告数据训练了 BERT 模型,加上专家经验进行一定的后处理,成功让信息抽取的 F1 指标*达到 0.88。
*F1 指标:准确率及召回率的综合评价指标,越趋近于 1 则表明算法或模型越佳
为了降低标注的难度,我们还配套开发了一个数据标注平台,支持框选、划词等多种标注方式,可以为 NER、分类、文档序列化、实体关系抽取等多种 NLP 任务提供数据标注。
业务决策
当完成信息抽取后,为了达到商机筛选的目的,还需要进行业务分类、归属地识别、资质匹配等业务逻辑处理。
以资质匹配为例,这个过程包括招标公告资质表达式生成、目标公司资质库结构化、表达式求解三个过程。
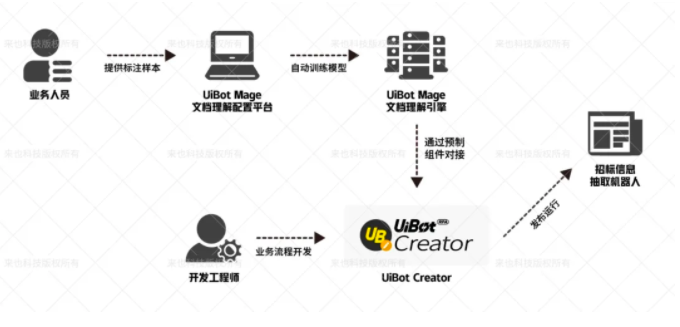
招标公告资质表达式生成
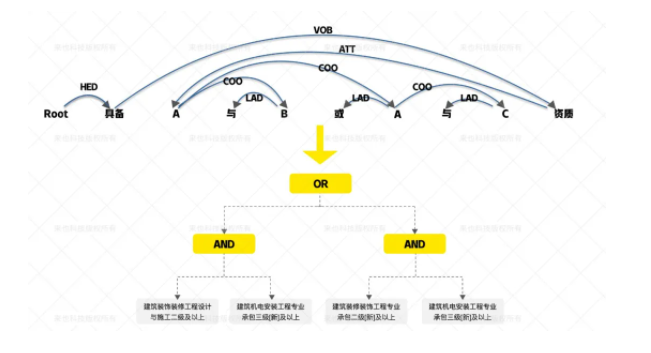
建筑工程招标公告中“申请人资格要求”部分包含投标单位必须具备的资格条件,其中最重要的就是对企业资质的要求。首先,我们将识别到的资质要求,比如“建筑装饰装修工程设计与施工二级及以上”,用占位符(Token)替换(如下图中的A、B、C);然后,对文本做依存句法分析,识别句子中不同占位符之间、占位符与逻辑关系关键词(与、或等)之间的依存关系;最后将依存句法树通过规则转化成逻辑表达式。如下图示意。
示例:本专业承包工程资格预审要求申请人具备 建筑装饰装修工程设计与施工二级及以上与建筑机电安装工程专业承包三级[新]及以上,或建筑装修装饰工程专业承包二级[新]及以上与建筑机电安装工程专业承包三级[新]及以上 资质,近 3 年已完工的单项合同额 600 万元(含)以上或建筑面积 4000 平方米(含)以上的房屋建筑工程。
目标公司资质库结构化
通常一个资质要求由“行业资质”、“专业资质”、“等级要求”三部分构成,尽管不同的招标人在撰写标书时这三个部分会有不同的描述方式,但三部分的顺序一定是固定不变的,否则将是完全不同的资质。
如:“建筑装饰装修工程设计与施工二级”和“建筑装修装饰工程设计与施工二级”就是同一个资质
目标公司资质库结构化的目的是,将目标公司所有的资质拆分成上述三部分,方便每个部分可以去和目标资质做模糊判别。

表达式求解
有了目标公司的结构化资质库和建立好的资质要求逻辑表达式,就可以最终输出目标公司是否满足招标资质。
资质匹配示例
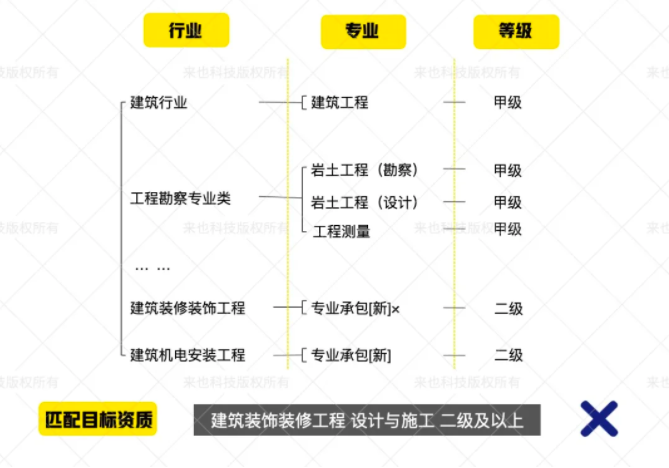
表达式求解示例

人机协作优化模型
以上内容就是来也科技的招投标信息自动抓取和匹配部分的系统设计,然而在实际中,我们都知道机器无法做到百分百的准确(新的格式、领域词汇、表达方式等),因此我们还准备了人机协作模块。
在 RPA 的处理流程中,当完成信息抽取和业务推理后,会根据模型输出的置信度辅以业务经验(如不可能没有招标金额),将低置信度或违背业务经验的数据发送给人工进行校正,同时人工也可以对每天处理的数据进行抽检,当人工发现错误后可以直接在标注平台上进行纠正。纠正后的数据积累到一定程度后会启动模型的增量训练,改善模型的效果,做到数据的闭环。

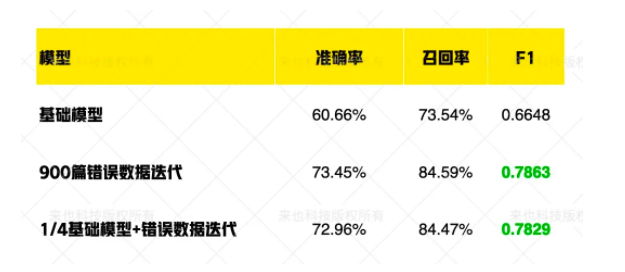
通过实验验证,通过在 900 篇错误数据上进行迭代训练,模型的 F1 指标能迅速提升 0.12,效果十分可观。
在上述的实验中,我们发现通过少量的错误数据进行模型迭代(900 篇对比 1w 篇)可以有效的提升模型的效果,因此我们尝试将基础模型的训练数据降到原来的 1/4 重新训练模型,再利用 900 篇错误数据对模型进行迭代,我们发现同样能很好的改善模型的效果(仅比原方案降低 F1 指标降低 0.003)。
通过人机协作模块的实验,我们得出了通过少量数据启动训练后再在错误样本上进行迭代训练,既能快速提升模型的效果,也能极大的降低初始的标注成本。
效果评估
针对招标公告的抽取效果评估整体的 F1 指标在 0.88,重要字段的 F1 指标均超过 0.85。以下是部分字段的效果:
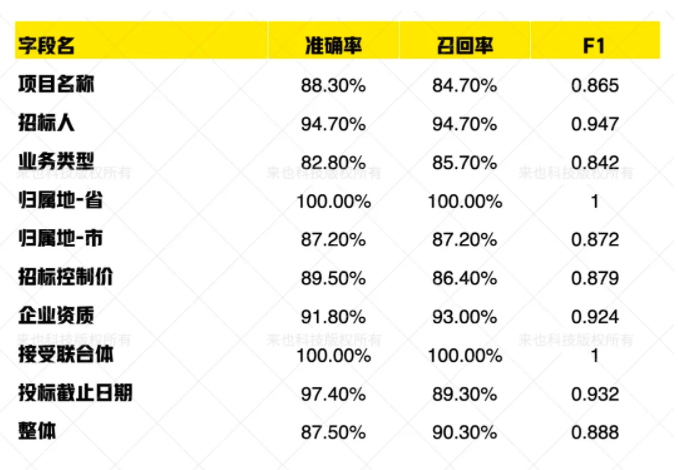
为了验证数据闭环的效果,我们选取了一些处理有错误的数据,在原来的基础上进行增量训练后,信息抽取模型部分的 F1 指标从 0.665 提升到了 0.786。在讲基础模型的训练数据随机削减到原来的 25% 后,在错误数据上进行迭代,F1 指标仍然能够达到 0.783。
在上述案例客户的应用过程中,日均处理约 3000 篇招投标文件,涉及 34 个省级行政区、357 个市,软件机器人可帮助目标公司提前筛选掉约 40% 的不符合要求的招标文件,极大的节省了筛选的人力成本。
本文介绍了智能文档处理在招投标领域的应用。通过使用来也的 RPA 和 NLP 技术对招投标文件的自动抓取、信息抽取、业务辅助判断,能够做到实时发现商机及辅助决策,提升商机的转化率,降低人力筛选招投标的成本,增强企业的竞争力。该解决方案同样也适用于其他需要对大量文档分析和决策的场景,可广泛应用于各类企业文档的处理上。
 更多产品了解
更多产品了解
欢迎扫码加入云巴巴企业数字化交流服务群
产品交流、问题咨询、专业测评
都在这里!


热门数字化产品






1月16日,2025腾讯产业合作伙伴大会在三亚召开。云巴巴,荣膺“2024腾讯云卓越合作伙伴奖—星云奖”和“2024腾讯云AI产品突出贡献奖”双项大奖

腾讯TAPD作为国内领先的敏捷研发管理平台,可以说是最早拥抱MCP的研发管理工具之一,凭借其全生命周期的研发管理能力,成为AI代码助手的“最强外挂”,其创新功能直击开发痛点。

基于预设规则和对象特征,让消息推送更智能更精准,帮助企业打通内外部系统的数据系统,实现更多灵活、更个性化的营销和服务能力开发。

海纳嗨数凭借其专业的数据分析能力,为企业提供从数据采集到深度洞察的一站式解决方案,助力活动策划与执行实现质的飞跃。

网宿科技全站加速产品以弱网优化与源站灾备技术矩阵,构建全链路加速体系,通过核心技术为多场景提供端到端保障,实现弱网效率跃升、源站切换无感,助企业突破网络桎梏。