







腾讯云语音识别 ASR
立即咨询
 首页
首页 产品功能
产品功能语种
中、英、粤、川、上海话、韩、日、泰、南昌、南京等23种方言,
陆续会支持更多方言及语种。
行业
通用、音视频、金融、法庭、医疗、游戏等领域。
接入方式
API、SDK、小程序插件。
子服务
实时语音识别,对实时音频流进行识别,“边说边出文字一句话识别,对60s之内的录音文件进行识别,半实时返回文字录音文件识别,对较大的录音文件进行识别,异步返回文字。
录音文件识别极速版,对较大的音频极速返回文字。
语音流异步识别,对直播流进行实时识别返回文字。
效果自调优
热词、自学习模型,用户通过添加特定名词、句篇,可显著提升专有词汇或句篇的识别准确率。
语言模型自训练平台
语音识别准确率业界领先
社交对话场景(非电话,带口音,口语化)。
97%+
社交对话场景(非电话,带口音,口语化)。
97%+
实验室环境。
90%+
背景安静,近场,口语化,标准普通话场景下字准率。
85%~90%
背晨轻微噪音,近场,口语化,轻度口音场景下字准率。
背景安静,近场,口语化,标准普通话场景下字准率。
85%~90%
背晨轻微噪音,近场,口语化,轻度口音场景下字准率。
 语音识别产品优势
语音识别产品优势
腾讯云语音识别技术采用自主研发的Dual Path Attention Network(DPAN)模型,通过共享端到端AED系统和Hybrid Conformer系统的Encoder,通过系统融合实现对语音信号高效的建模,在不同应用场景下,具备较好的鲁棒性。同时,根据业务需求,在DPAN框架下,实现了低延时的流式输出,以及在声音和文本层面的自适应能力。针对多语言混合场景,研发了混合语音识别模型,可支持单一模型识别国内20多个地区方言,以及单一型识别中英粤三个语种,极大方便了业务应用。
语音识别产品算法效果16K(非电话) 场景: 整体识别准确率业界领先,基于微信、王者、腾讯自由强势产品积累数据持续打磨模型;
8K(电话)场景: Q2更新一版基于业界最领先技术的模型,整体识别准确率预计可以追齐友商。
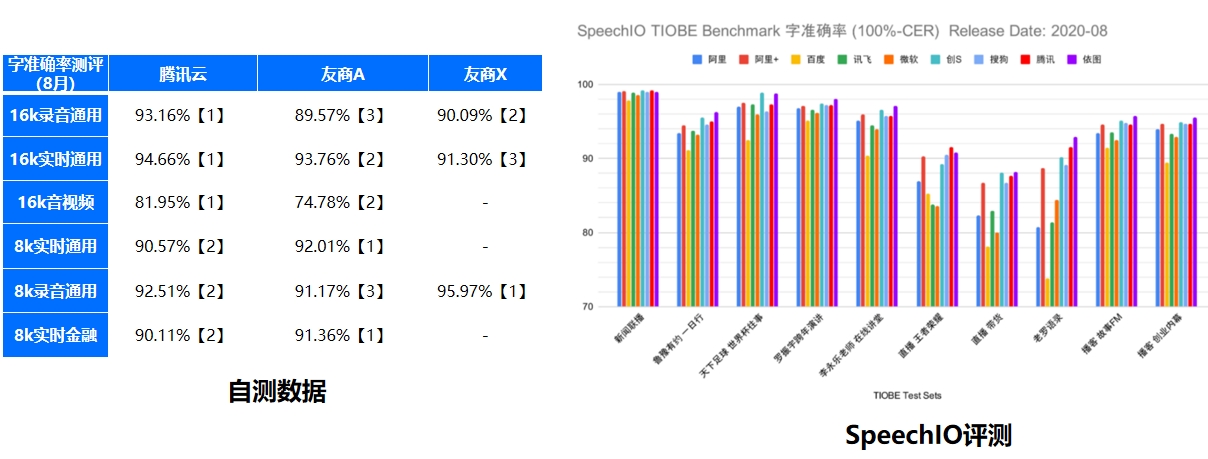
语音识别产品时延效果经过3.0专项打磨,在保证基本准确率的基础上,时延指标处于业界一流水平。

语音质检解决方案
使用场景:
·大型呼叫中心话务员日常工作评价。
业务痛点:
·人工处理速度慢,抽检覆盖率低。
·大型呼叫中心话务员日常工作评价。
业务痛点:
·人工处理速度慢,抽检覆盖率低。
· 标准不一:无法避免个人主观性影响。
·成本高:需要大量人力,且需要定期培训、抽查。
解决问题
·以统一的标准快速实现电话业务的全量质检。
解决问题
·以统一的标准快速实现电话业务的全量质检。

语音质检 -- 携程客服呼叫中心
项目背景:携程拥有超过10000个坐席的呼叫中心,对呼叫中心员工的通话内容的质检是一个业务痛点和难点,影响到呼叫中心员工的工作评定和呼叫中心整体运营水平的提升
解决方案:录音文件识别
客户价值:大幅提升呼叫中心工作质量管控能力,完成人力不可能完成的超大规模呼叫中心的电话录音质检问题
解决方案:录音文件识别
客户价值:大幅提升呼叫中心工作质量管控能力,完成人力不可能完成的超大规模呼叫中心的电话录音质检问题
语音客服 -- 中信银行智能客服
项目背景:中信银行有大量的客户咨询、投诉电话需要呼叫中心人工客服进行处理,人力成本极高,并且客服员工流动性大,导致服务质量不一致,培训成本也很高
解决方案:实时语音识别+BOT+语音合成
客户价值:大幅降低客户呼叫中心人力&培训成本,客服场景由机器人处理大部分重复性任务,由人工兜底剩余复杂业务。
解决方案:实时语音识别+BOT+语音合成
客户价值:大幅降低客户呼叫中心人力&培训成本,客服场景由机器人处理大部分重复性任务,由人工兜底剩余复杂业务。
语音敏感分析解决方案高效识别各类场景的涉政、色情、娇喘、广告、辱骂、 歪唱国歌等违规内容提前防御内容风险,提高审核效率,净化网络环境,提升用户体验。
· 涉政语音识别
· 娇喘语音识别
· 辱骂语音识别
· 色情语音识别
· 娇喘语音识别
· 辱骂语音识别
· 色情语音识别
直播质检 - 拼多多
项目背景:“直播带货”已经成为潮流,可以有效提升了消费者的消费体验,但同时对于直播的合法合规监控也成为一项必须要做的事情。
解决方案:录音文件识别极速版(音视频模型)。
客户价值:把商家在直播时主播的语音转为文字,再依靠后端语义的能力进行审核,可快速有效的完成对整个电商平台直播合法合规的监控与管理。
视频添加字幕 -- 美图秀秀
项目背景:在短视频领域,越来越多的公司不断发力,视频自动识别添加字幕是标准功能。
解决方案:公有云录音文件识别极速版(音视频模型)。
客户价值:语音识别能力准确,性能稳定,帮助美图秀秀顺利赶上短视频浪潮,也提升了用户活跃度
项目效果:腾讯云语音识别产品逐步成为美图集团全产品线共同的选择。
音视频标签 -- 喜马拉雅
项目背景:对于UGC音频内容,中长尾用户上传的材料,标签是缺失或错误的,无法做对应的内容挖掘及推荐。
解决方案:录音文件识别极速版(音视频模型)。
客户价值:依赖语音识别的能力,可以把语音转成文字,再依靠后端语义的能力形成内容标签,把中长尾用户的UGC内容整合入推荐系统。
语音输入法/语音弹幕
场景:在很多带交流功能的app中,语音输入是一项很方便和实用的功能,可极大缩短用户打字时间,提高交流效率。
解决方案:实时语音识别(iOS/Android SDK接入)
腾讯优势:
解决方案:实时语音识别(iOS/Android SDK接入)
腾讯优势:
1、识别效果业界领先:微信、王者海量匹配场景的数据积累,准确率、识别时延、流畅度业界领先;
2、灵活后处理:增加用户的易用性;
3、支持高并发:在线识别服务支持数千路高并发且不针对并发路数增加收费;
4、接入成本低:在线+离线的iOS/Android SDK完备。
高潜客户:输入法app、在线教育、社交类app、团战类游戏app。
4、接入成本低:在线+离线的iOS/Android SDK完备。
高潜客户:输入法app、在线教育、社交类app、团战类游戏app。

语音输入法 -- KK键盘
项目背景:语音输入法一致时语音识别的重要领域之一,北京义享科技打造的KK键盘致力于为年轻人提供娱乐性最强的语音输入法,不仅支持表情包、动图等趣味性高的能力,也支持语音输入转文字。
解决方案:实时语音识别(通用)。
客户价值:通过语音3.0专项的优化,目前腾讯云实时语音识别能力与精品相比处理领先位置,尤其是最重要的首字延迟上,1-1.2秒的延迟远超竟品,是客户选择腾讯云AI能力为服务的重要原因。
解决方案:实时语音识别(通用)。
客户价值:通过语音3.0专项的优化,目前腾讯云实时语音识别能力与精品相比处理领先位置,尤其是最重要的首字延迟上,1-1.2秒的延迟远超竟品,是客户选择腾讯云AI能力为服务的重要原因。
游戏语音--王者荣耀
游戏娱乐一站式语音解决方案
实现功能
· 游戏语音开黑
· 游戏语音开黑
· 语音聊天室
· 语音直播
· 线上 K歌
语音技术支撑
· 实时语音对讲
· 多人连麦
语音技术支撑
· 实时语音对讲
· 多人连麦
· 语音消息及语音转文本
语音游戏 -- 你演我猜
项目背景:重庆米虫科技与腾讯云AI语音联合GME团队,为台北及东南亚地区开发你画我猜游戏,使用实时语音识别转文字。
解决方案:实时语音识别(通用)
客户价值:依赖高精准的语音识别能力,可以把语音快速,准确地转成文字,再依旱后端文本匹配的能力进行游戏推演语音识别能力是这个游戏的重要核心,优秀稳定的语音识别能力将客户日活从8万提升至20万,DUA增长超过149%。
解决方案:实时语音识别(通用)
客户价值:依赖高精准的语音识别能力,可以把语音快速,准确地转成文字,再依旱后端文本匹配的能力进行游戏推演语音识别能力是这个游戏的重要核心,优秀稳定的语音识别能力将客户日活从8万提升至20万,DUA增长超过149%。
应用场景&解决方案
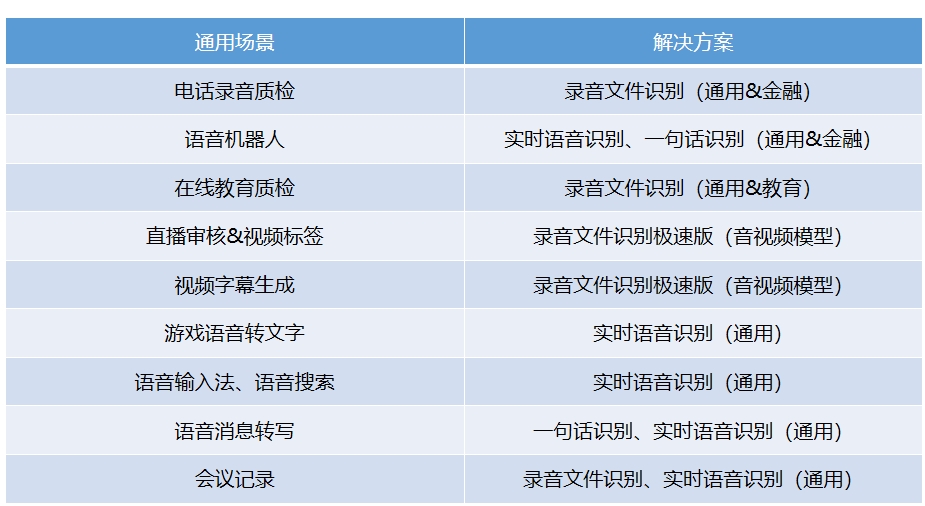
客户案例集锦
产品推荐

艾客全网会员数智营销平台利用社交助力功能,帮助商家方便完成核心消费者(KOC) 的助力加粉,为商家通过私域流量撬动源源不断的新客户, 带动业绩的大幅提升。将朋友圈素材通知同步到每名员工,并提醒发送,大幅提升朋友圈营销效率,为客户高效打造企业人设。通过用户属性、行为、购物数据设置标签,构建用户画像,为客户分层运营提供依据同时节省客服人工,提升营销效率。

帆软智慧水务可视化大屏包括四个分页,分别为水厂总览、管网监控、营收数据、巡检养护,帮助经营管理者实现水务业务系统的控制智能化、数据资源化、管理精确化,保障水务设施安全运行,使水务运营更高效。

网御数据防泄露系统(DLP),是一款敏感数据防泄露产品,它从敏感信息内容、敏感信息的拥有者、对敏感信息的操作行为三个角度对数据进行分析,通过清晰直观的视图,让管理者及时了解企业内部的敏感信息使用情况。帮助管理者发现组织内部潜在的泄密风险,监管组织内部重要数据的合规合理使用,保障组织知识产权与核心竞争力。

身边云房地产行业灵活用工解决方案以房地产及其上下游行业用工场景的特点为依据,通过对其进行用工关系、岗位设置及项目内容的全方位梳理,提供综合解决方案,助力房地产行业最大限度合规减负。



