







Zilliz Cloud全托管向量数据库服务
立即咨询
 首页
首页 非结构数据处理面临的挑战
非结构数据处理面临的挑战• 数据体量巨大,未来超过80%的数据属于非结构化数据,AIGC时代多模态数据的生成速度远远超过结构化数据,系统扩展性性能至关重要。
• 非结构化数据理解困难,虽然LLM已经大幅降低了非结构化数据理解的成本,但由于数据质量、多模态,成本性能等问题,单一大模型并不能完全解决非结构化数据理解的问题,很多场景下依然需要多模型组合,搜索与生成结合等方法。
• 算力的要求巨大,推理、向量数据库存储检索等都是算力密集型应用。算力的需求和成本往往成为挖掘非结构化数据的一大阻碍。
• 缺乏工具,虽然传统的结构化数据处理并不简单,但由于ETL、数据库、数据仓库等工具在过去30年的发展,已经变得相对成熟。然而,非结构化数据处理的工具链刚刚开始构建,这就使得非结构化数据的处理相比结构化数据更具挑战性。
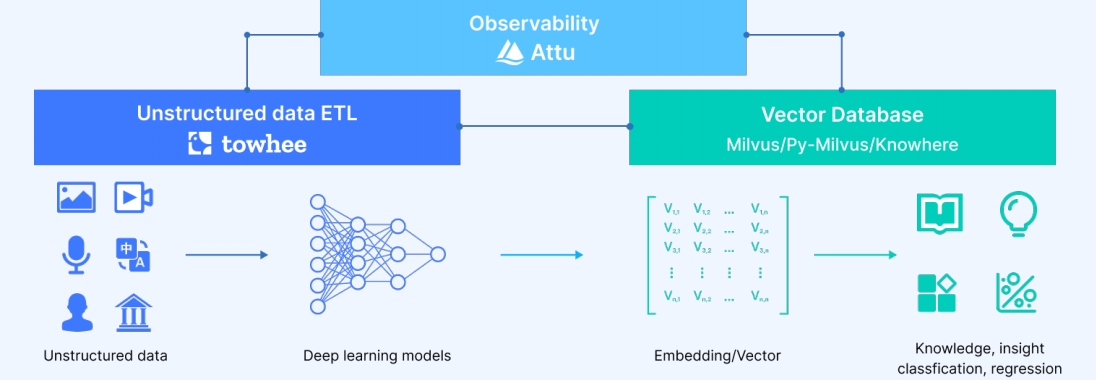 向量数据管理的主要挑战
向量数据管理的主要挑战 Zilliz - 构建开源+云的非结构化数据处理方案
Zilliz - 构建开源+云的非结构化数据处理方案
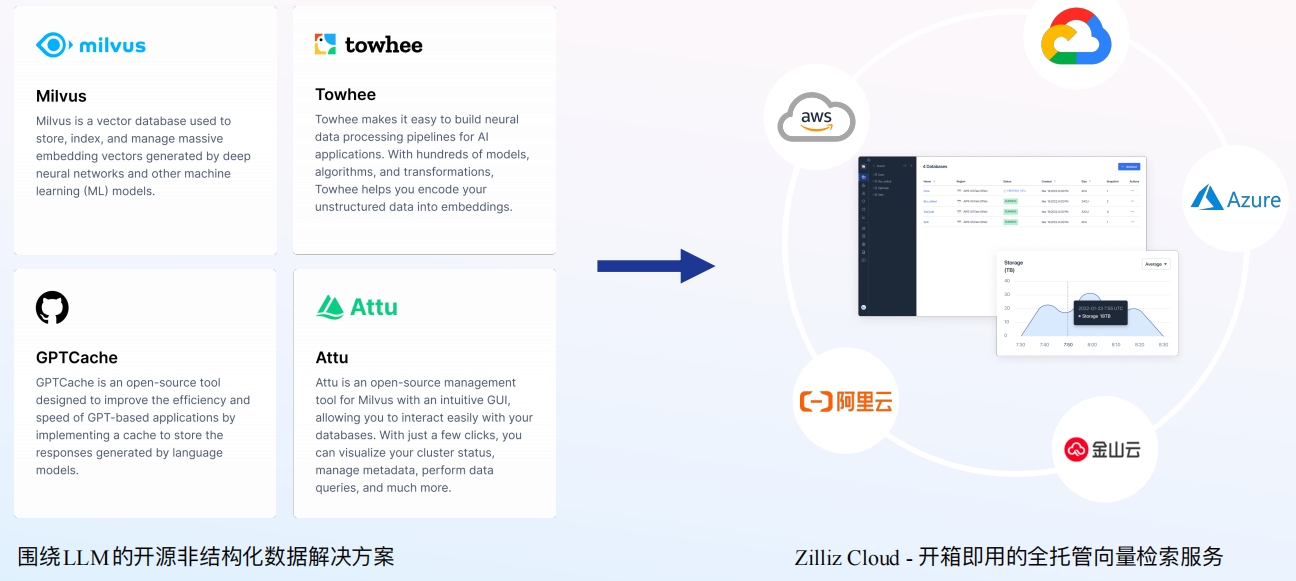 Zilliz Cloud - 助力全球企业构建云上全托管向量检索服务Zilliz Cloud功能架构
Zilliz Cloud - 助力全球企业构建云上全托管向量检索服务Zilliz Cloud功能架构
 全球服务覆盖
全球服务覆盖
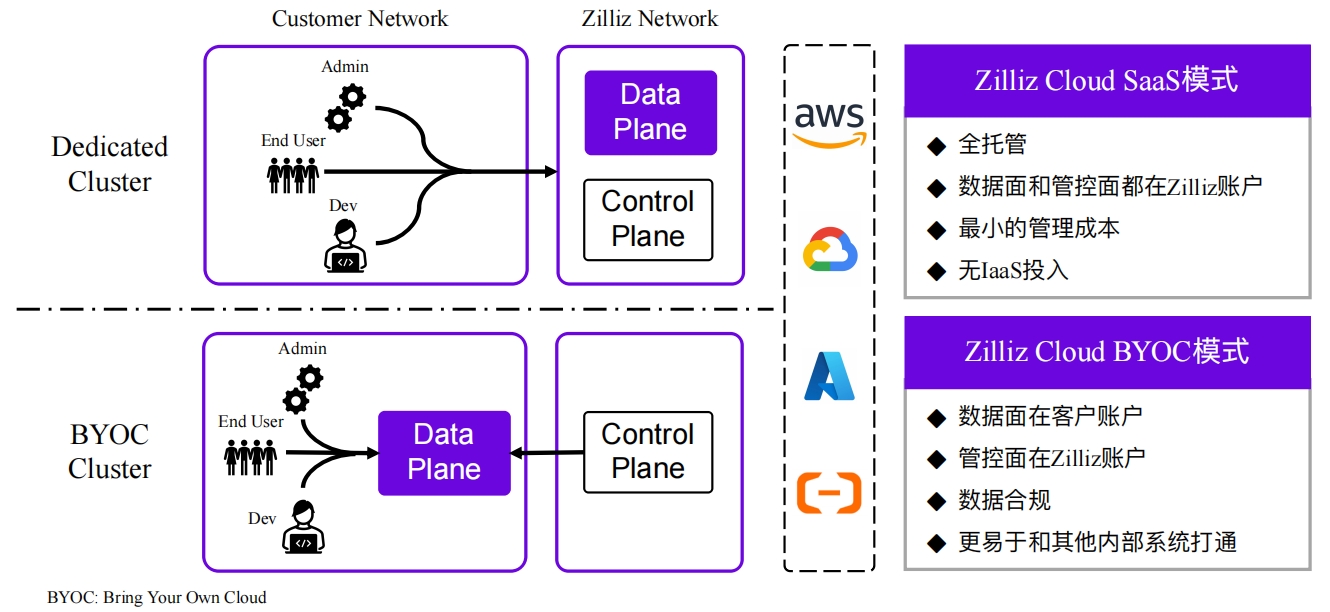
 灵活的部署方式
灵活的部署方式
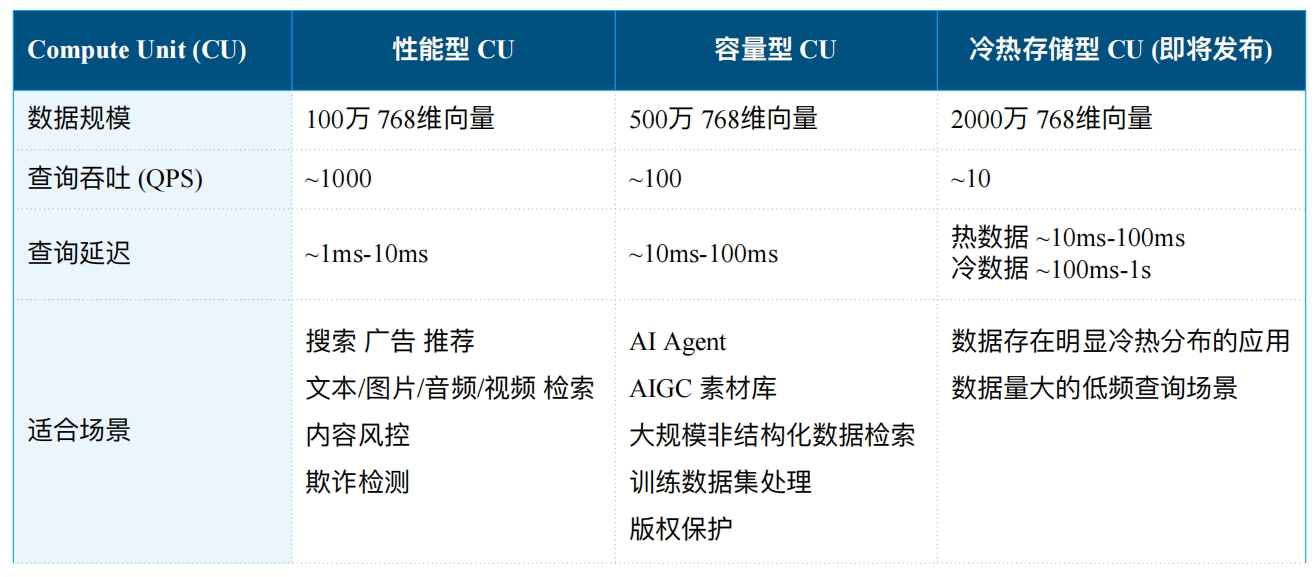
 实例类型
实例类型
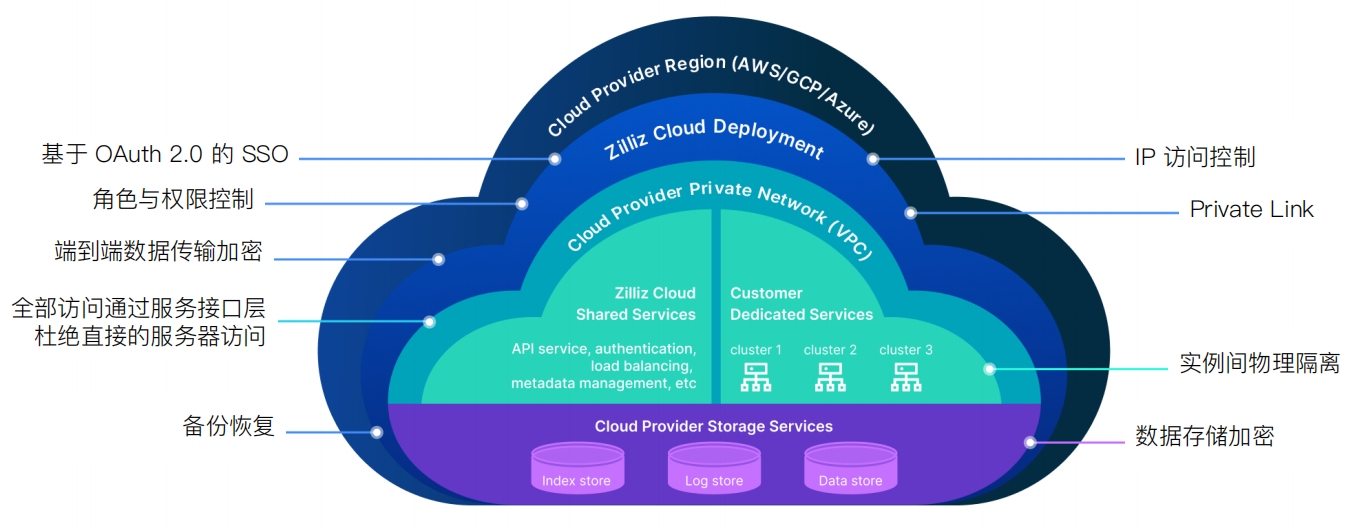
 系统安全与数据安全
系统安全与数据安全
 开源标准接口+灵活迁移部署
开源标准接口+灵活迁移部署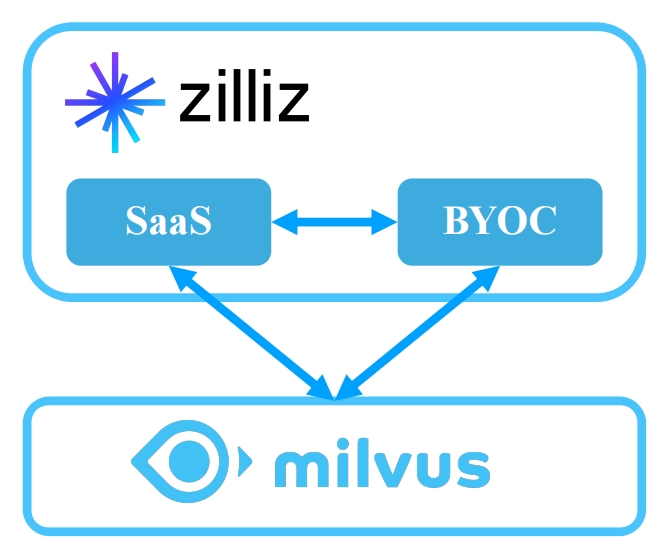 向量查询能力
向量查询能力
 数据类型
数据类型
 扩展能力
扩展能力从6500万向量水平扩展至10亿向量,系统查询延迟与查询吞吐基本保持稳定
(当前线上版本相比图中2023年初测试结果有2-5倍性能提升)
 组织与成员管理
组织与成员管理
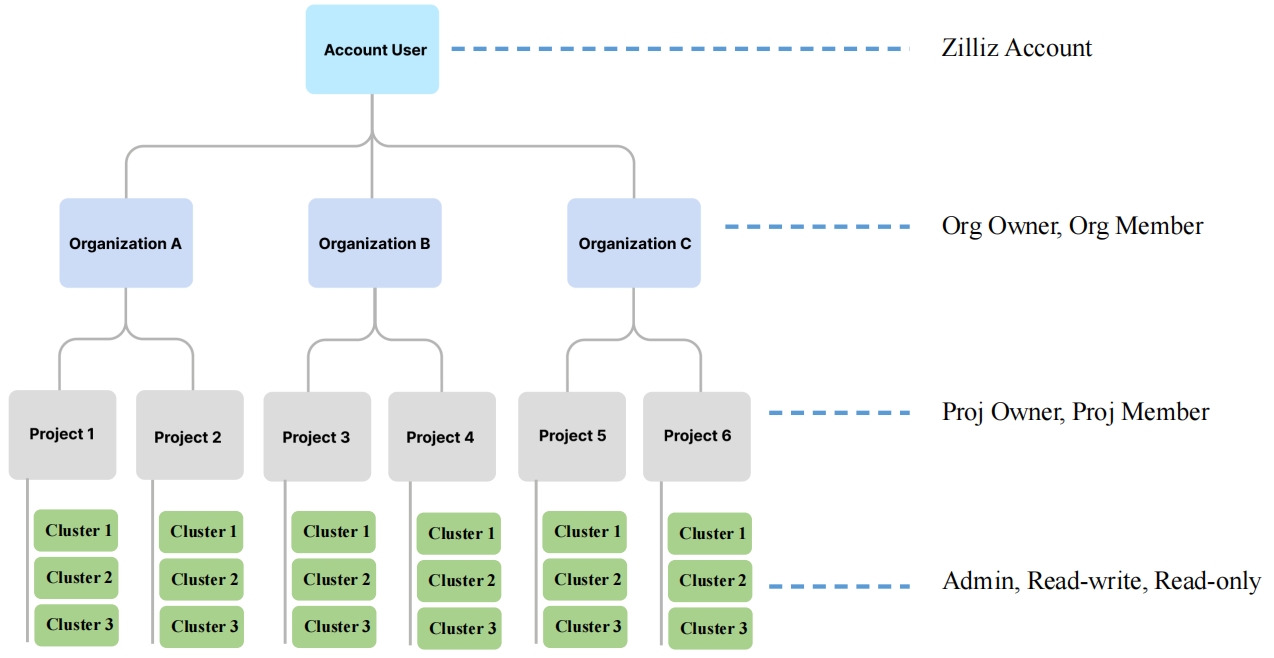 多租支持
多租支持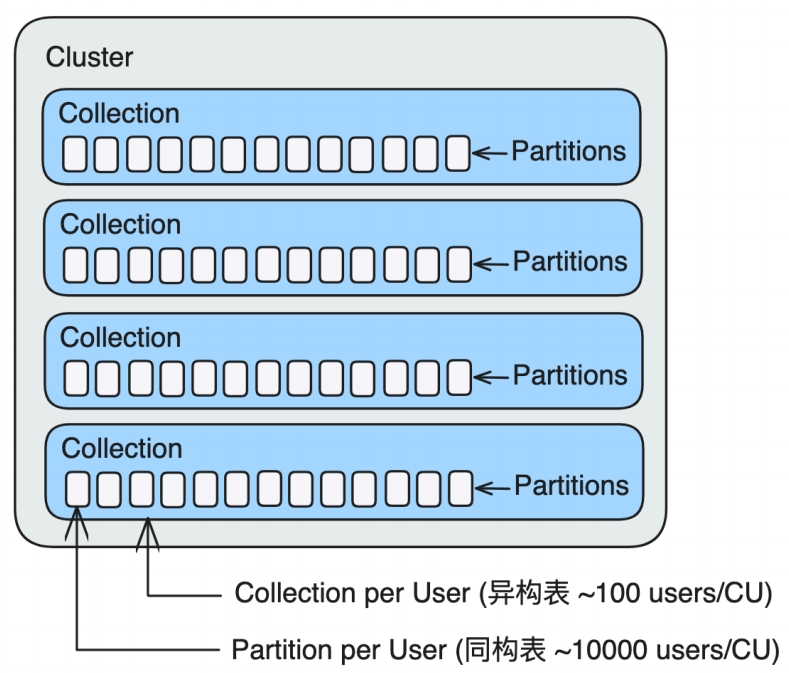 Zilliz RAG Total Solution
Zilliz RAG Total Solution
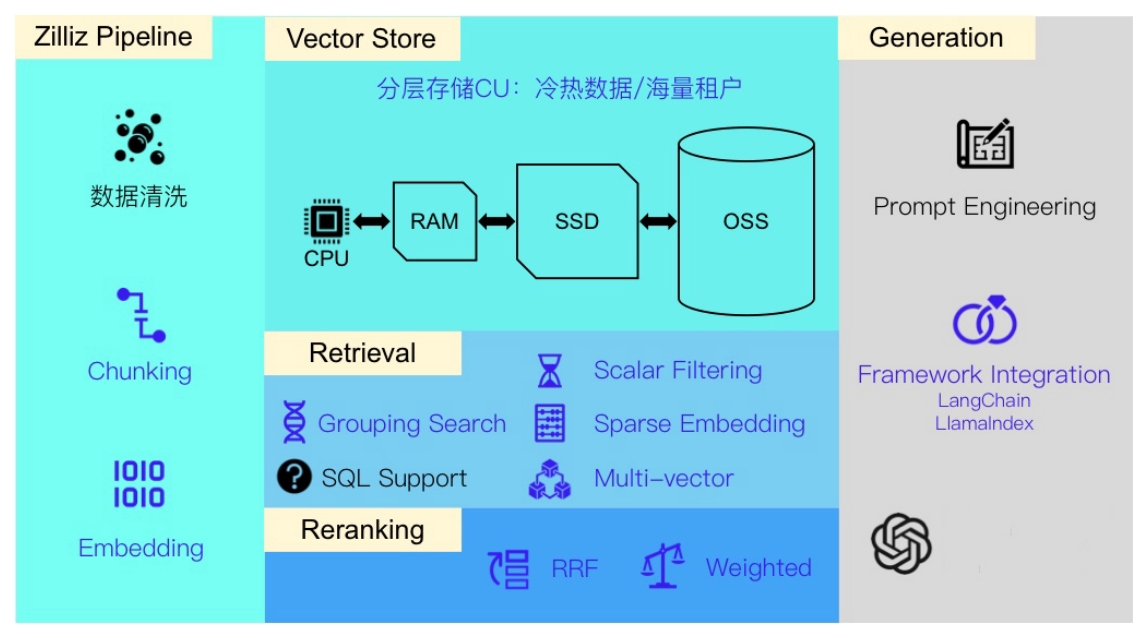 从向量检索到非结构化数据检索:Ingestion和Search流水线
从向量检索到非结构化数据检索:Ingestion和Search流水线
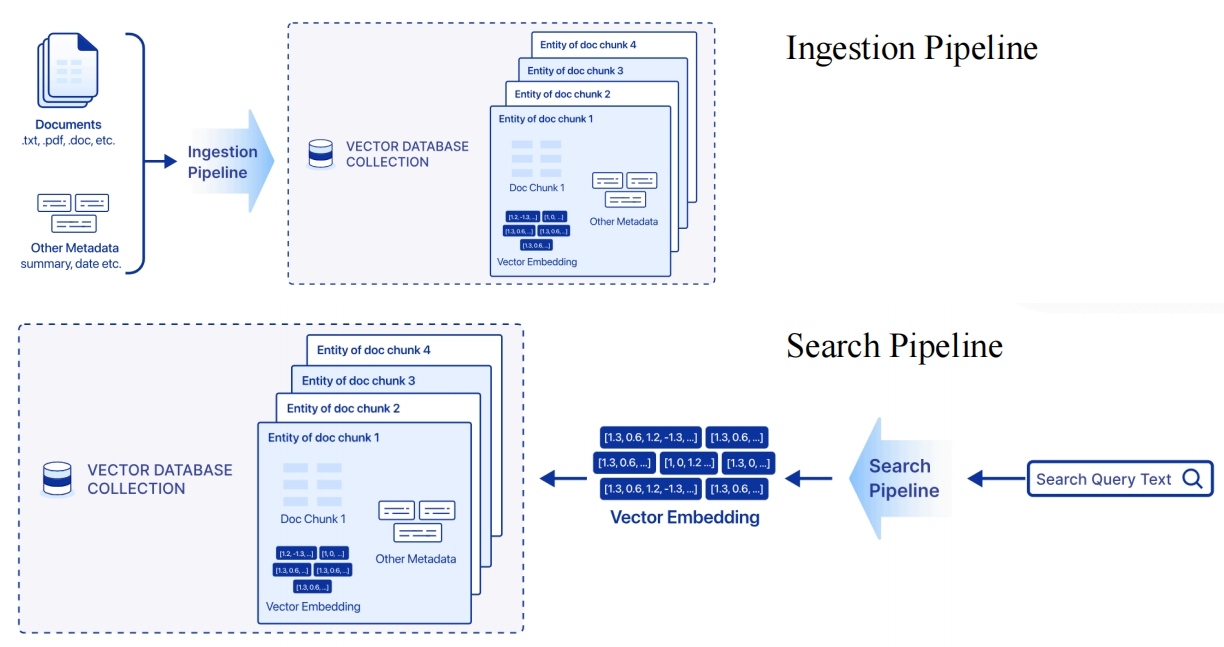 全文检索+多向量支持+多路召回+排序
全文检索+多向量支持+多路召回+排序(即将发布,敬请期待)
 一图看懂向量数据库之间的区别
一图看懂向量数据库之间的区别
 全球市场主流VDB产品
全球市场主流VDB产品
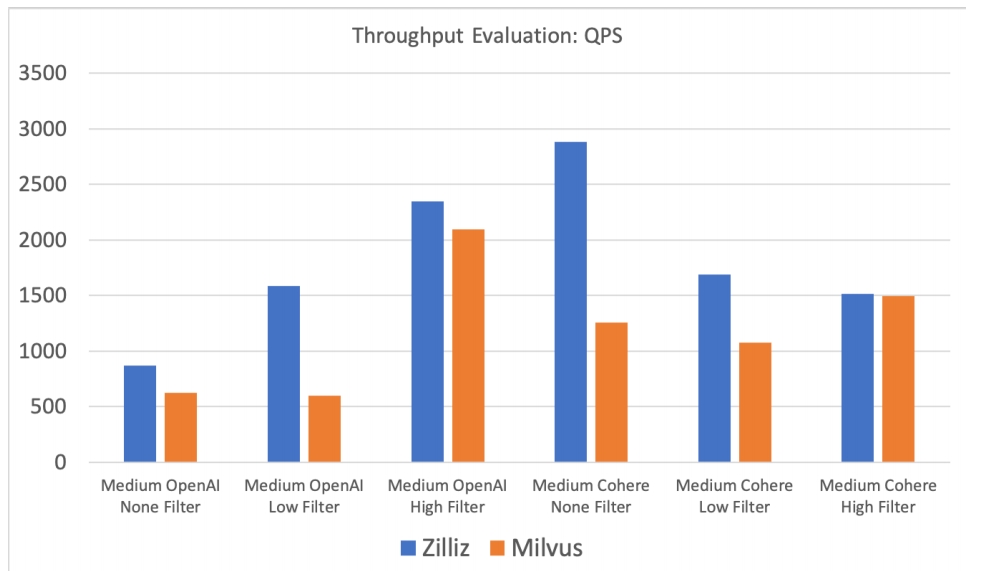
 商业版引擎与开源版引擎的性能差异
商业版引擎与开源版引擎的性能差异Zilliz Cloud 相比 Milvus,平均QPs1.67x,最高2.64x
 Zilliz Cloud带来用户综合成本下降
Zilliz Cloud带来用户综合成本下降
 开发成本降低索引智能调优
开发成本降低索引智能调优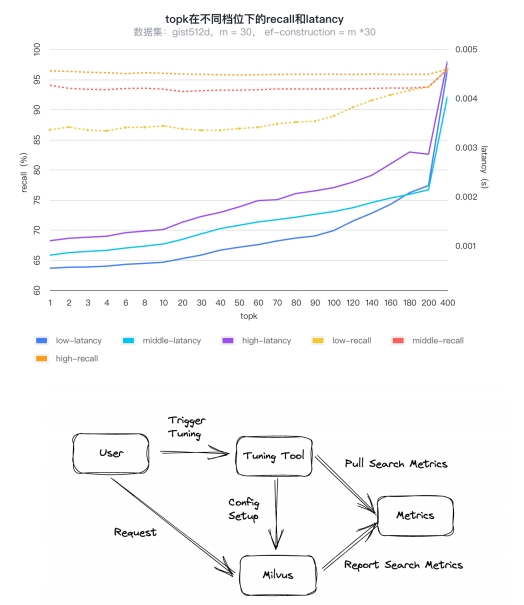 性能优化 - 自研Cardinal向量检索
性能优化 - 自研Cardinal向量检索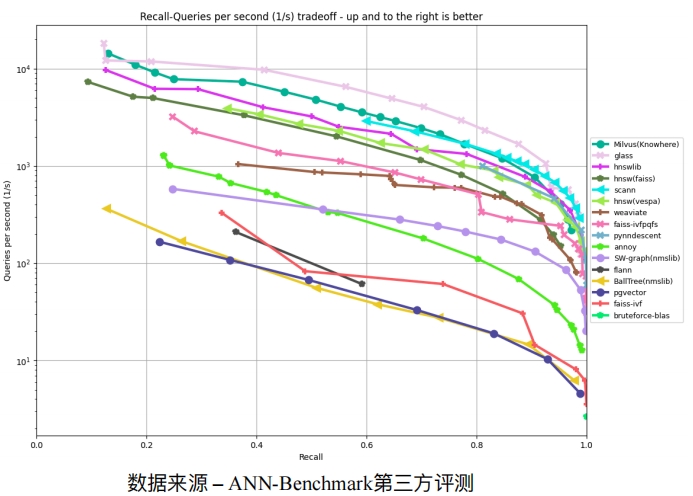 性能优化 - 混合查询
性能优化 - 混合查询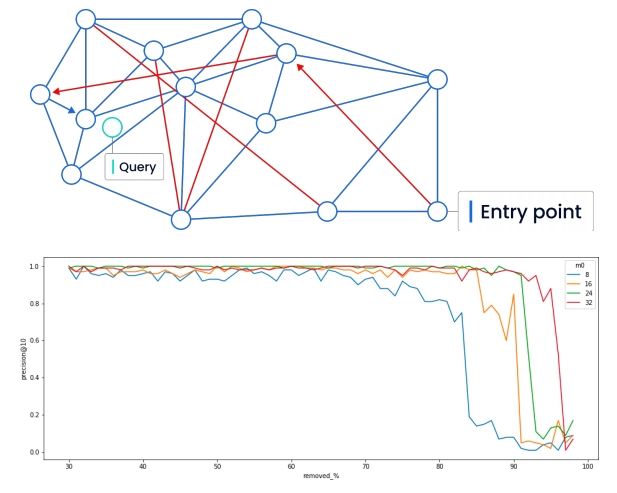 向量数据库评测:VectorDBBench
向量数据库评测:VectorDBBench
 Vector DB性能实测
Vector DB性能实测 成本优化 - 基于磁盘的混合索引
成本优化 - 基于磁盘的混合索引 运维成本降低安全合规Zilliz专家服务
运维成本降低安全合规Zilliz专家服务• 安全可靠,99.9 SLA保证
• 大量生产验证的部署方式和运行参数,大幅提升性能和故障恢复速度
• 7*24支持,重大问题快速响应兜底
 Zilliz Cloud适用业务场景向量数据库场景探索
Zilliz Cloud适用业务场景向量数据库场景探索
 使用向量数据库典型流程剖析
使用向量数据库典型流程剖析
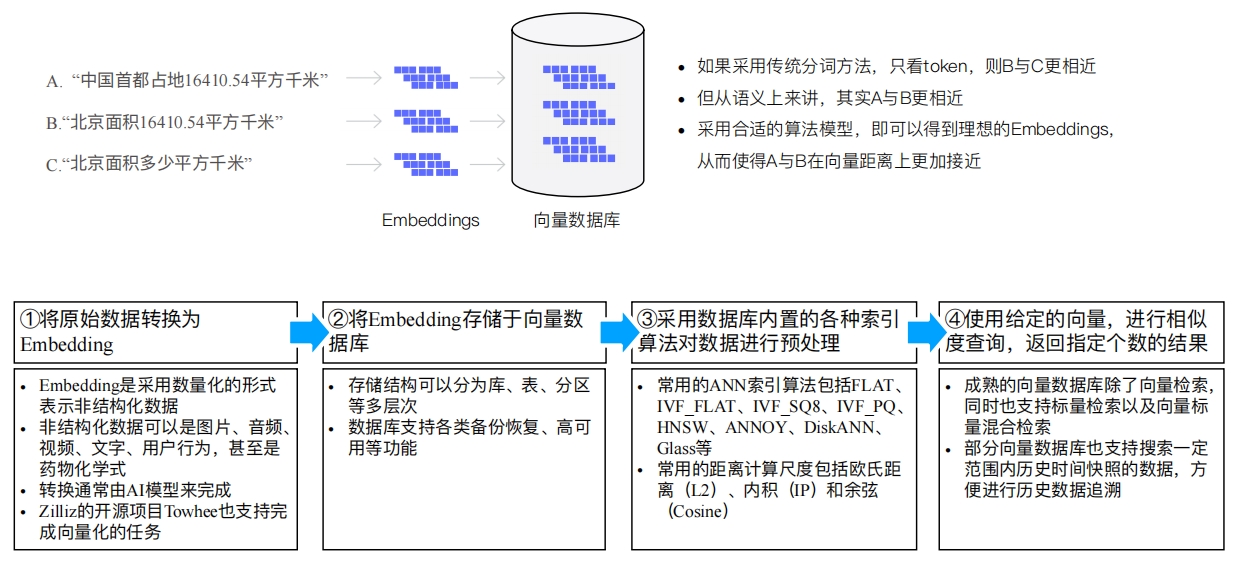 典型应用场景解析
典型应用场景解析
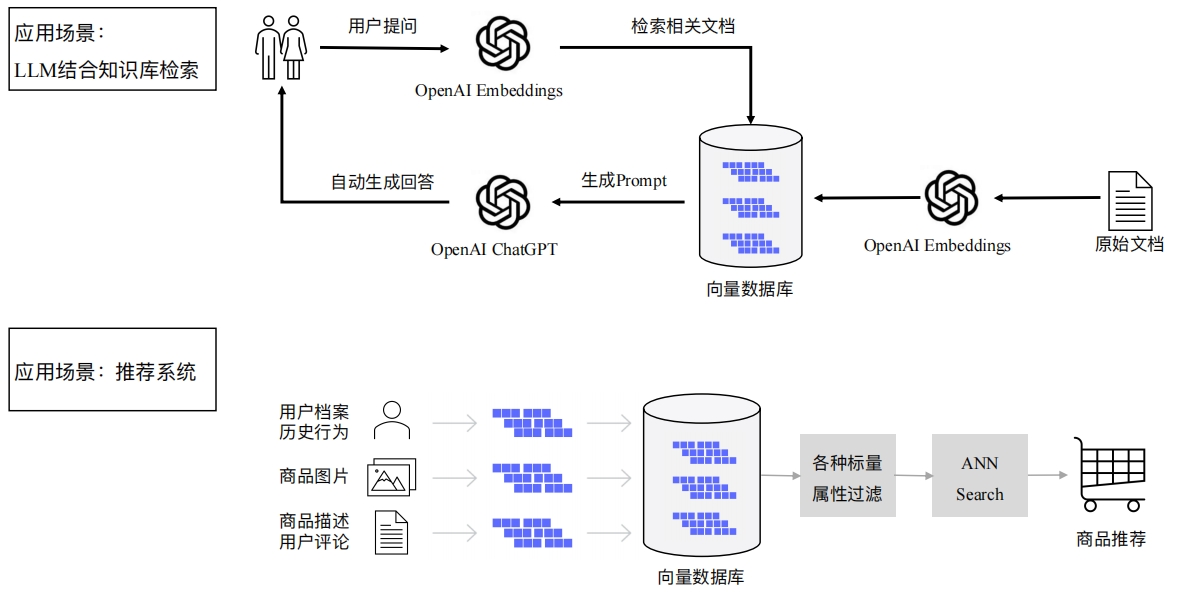 典型案例1 - 某综合性AI企业
典型案例1 - 某综合性AI企业
 典型案例2 - 某车企自动驾驶研发
典型案例2 - 某车企自动驾驶研发
 典型案例3 - 某制造业企业
典型案例3 - 某制造业企业
 Milvus客户生态
Milvus客户生态● Milvus 被全球超过 1000家企业用户所信赖,超过860万次下载和安装,最大库规模超过20亿条向量
● Milvus Github Star数目超过2.4万,贡献者人数超过 200
● Milvus DB-Engine引擎排名171,并且在SIGMOD和VLDB等数据库顶会上发表了论文,奠定了向量数据库的基础

产品推荐

DataPipeline批流一体数据融合平台采用基于日志的增量数据获取技术(Log-based change data capture),为主数据管理、数据仓库、大数据平台提供实时、准确的数据变化,从而使得客户可以根据最新数据进行运营管理与决策制定。

随锐科技KRD-I110变电站智能巡检机器人,专为变电站环境设计,具备超强防护能力。 超强的灵活性及路面适应性; 同时具有自主导航、自动避障、自动充电、仪表读数自动识别、状态指示识别、热红外测温、环境监测等功能,支持多种巡检模式、智能告警、历史数据分析, 可代替人 工巡视,实现对变电站的全天候、全方位、全自动智能巡检。

埃文科技IP定位数据电商平台应用方案,通过IP的地理位置信息与GPS信息交叉验证,识别判断用户本次操作行为的风险程度,以保证用户账号及交易安全。IP定位不需要用户授权,只需要对用户IP地址进行解析,就可以得到用户的地理位置信息。同时可以根据用户的位置分布,为线下门店的选址提供数据支撑。

威胁建模分析系统专注解决软件开发流程(SDL)中需求与设计阶段的安全问题。分析项目场景与软件架构,自动化识别可能存在的威胁,提出安全需求。在设计之初就考虑安全问题,以最小成本解决安全风险,为软件植入“先天的”安全基因。



