







腾讯云qGPU容器
立即咨询
 首页
首页 GPU当前现状
GPU当前现状 GPU 共享方案拦截分析
GPU 共享方案拦截分析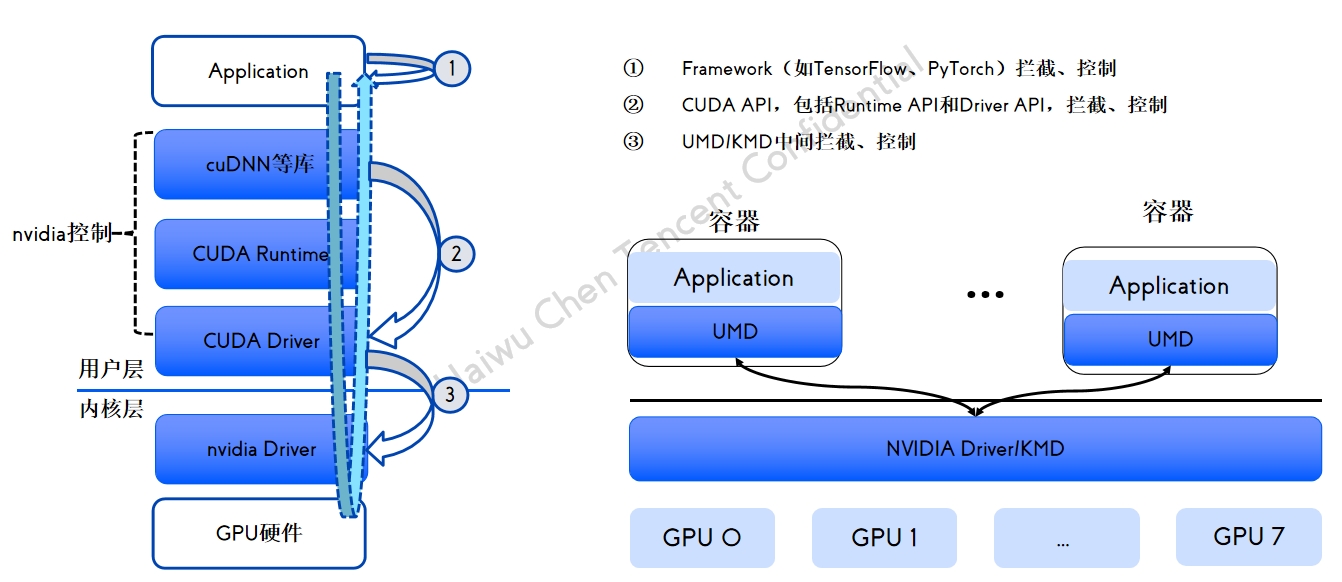 qGPU 容器产品介绍
qGPU 容器产品介绍 qGPU调度策略
qGPU调度策略
 qGPU 单卡调度policy
qGPU 单卡调度policy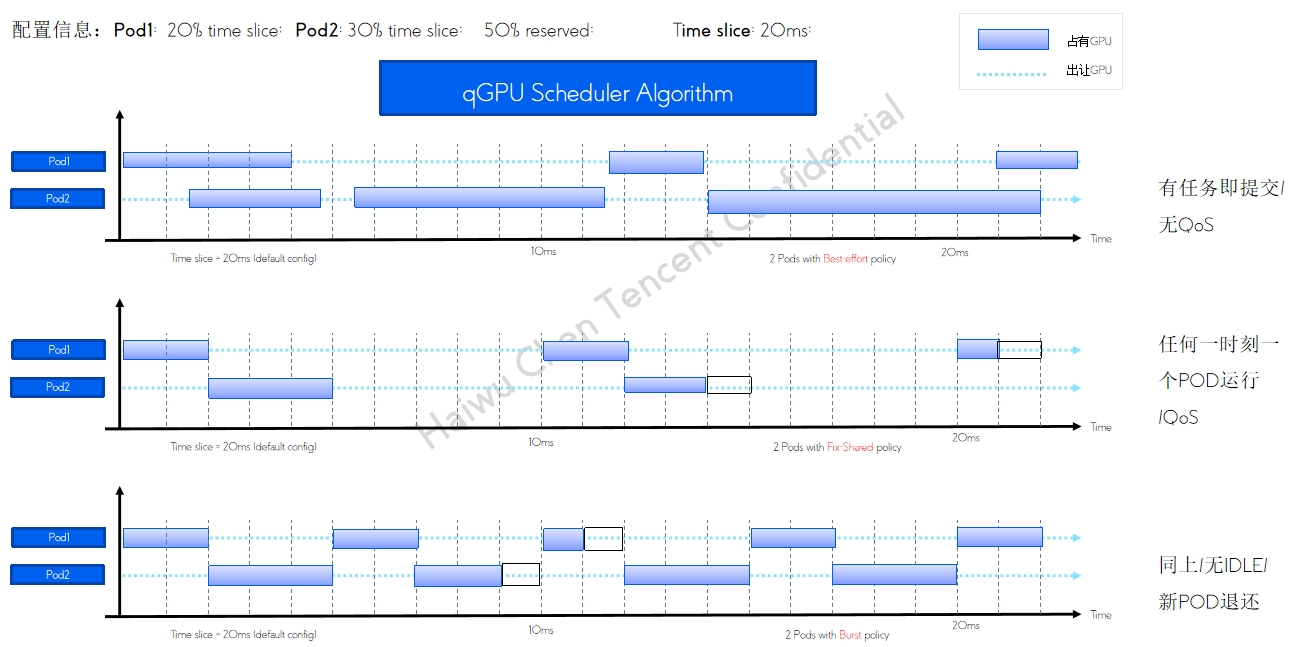 qGPU 在离线混部及调度方式
qGPU 在离线混部及调度方式高优任务 平均分配 保证负载均衡 低优任务 尽量填满 保证资源利用率 支持在线 100% 抢占 GPU利用率的极致提高 业内唯一GPU在离线混部技术

支持主流OS版本 qGPU交付方式
qGPU交付方式 qGPU IDC交付件
qGPU IDC交付件 公有云使用qGPU
公有云使用qGPU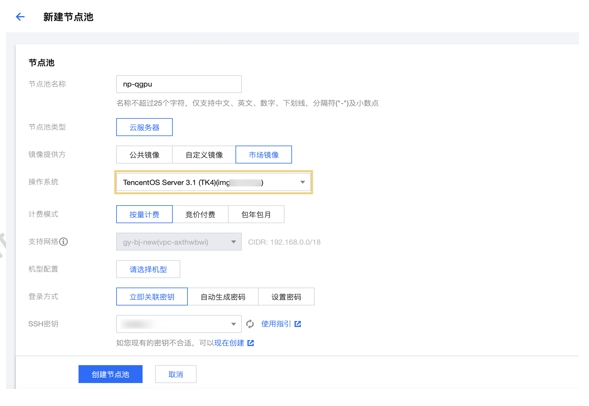 qGPU监控组件elastic-gpu-exporter
qGPU监控组件elastic-gpu-exporter 使用限制案例一:某头部互联网企业OCR场景
使用限制案例一:某头部互联网企业OCR场景 案例二:某在线教育AI推理业务
案例二:某在线教育AI推理业务
产品推荐

道一云CRM-营销获客与客户分析微信互通,打通外部客户资源,营销利器群发助手,多种线索分配方式,按需选择,微信、电话、上门拜访与客户联系,跟进线索。线索转换分析,挖掘高回报渠道。

百炼智能知了标讯医疗器械解决方案,垂直于医疗设备细分行业招投标数据分析,提供专业全面的有效信息,为企业扩展渠道商机赋能。行业领先的识别颗粒度、高效信息获取,可视化分析报表、直观看数据。

亿美软通短信服务系统,短信验证码、会员营销、通知提醒,99%到达率、优质通道、极速稳定,帮助企业营销、业务处理、客户服务等环节快速建立场景化Al语音机器人,实现智能B2C沟通。提供服务菜单配置,打造企业品牌传播及获客、转化新入口。




