
 图与机器学习的结合是下一代AI的技术基础
图与机器学习的结合是下一代AI的技术基础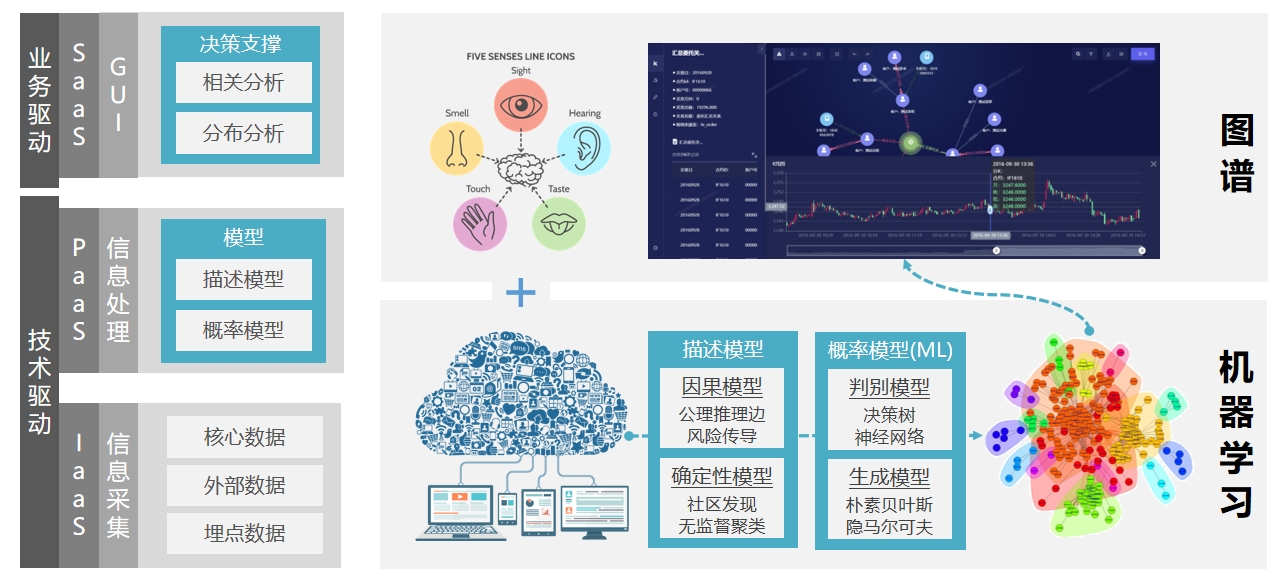 大模型与图谱
大模型与图谱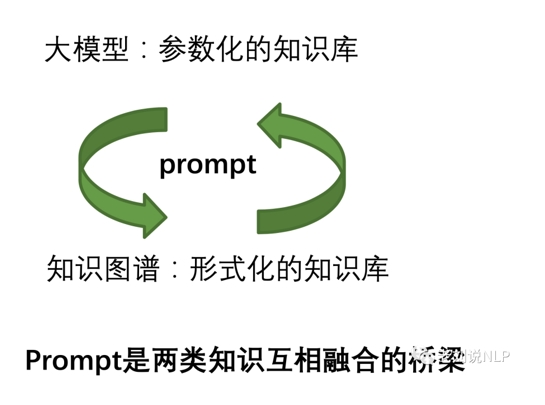 一个图与机器学习结合的应用例子
一个图与机器学习结合的应用例子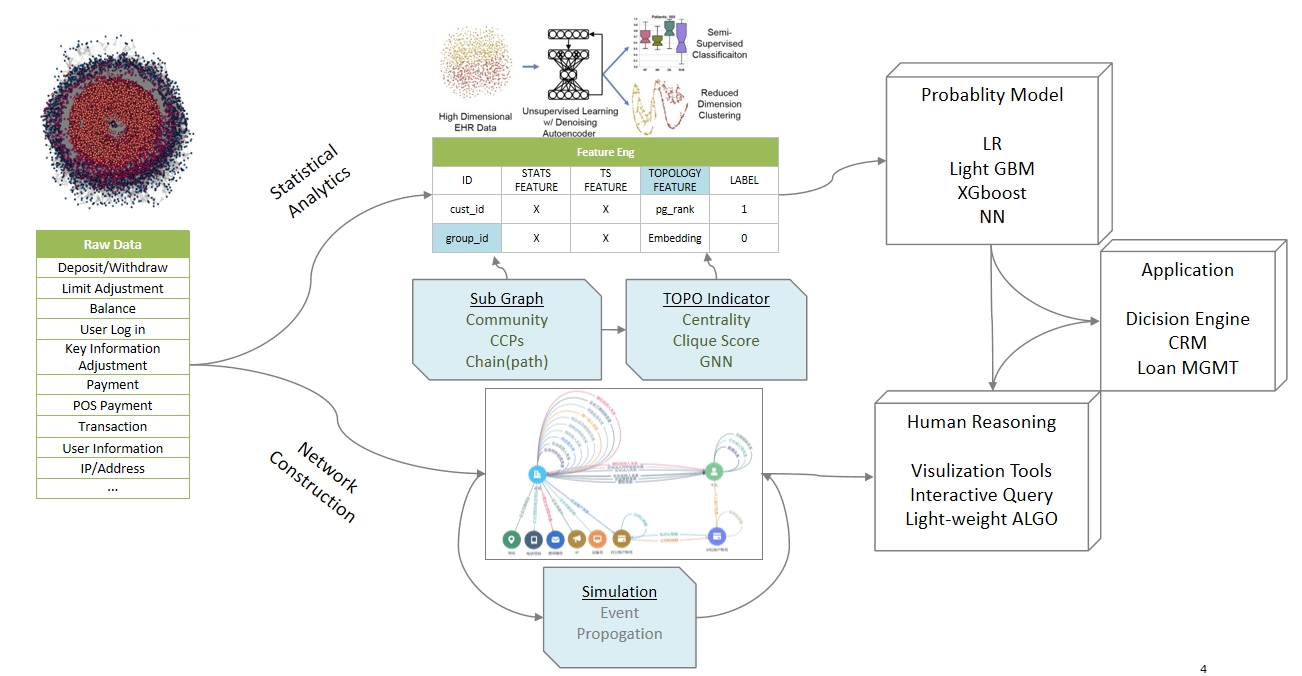 AtlasGraph高性能图数据库关键特性AtlasGraph全流程助力图业务快速落地发展AtlasGraph优势—AtlasGraph分布式架构,云原生模式、存算分离、易于扩展
AtlasGraph高性能图数据库关键特性AtlasGraph全流程助力图业务快速落地发展AtlasGraph优势—AtlasGraph分布式架构,云原生模式、存算分离、易于扩展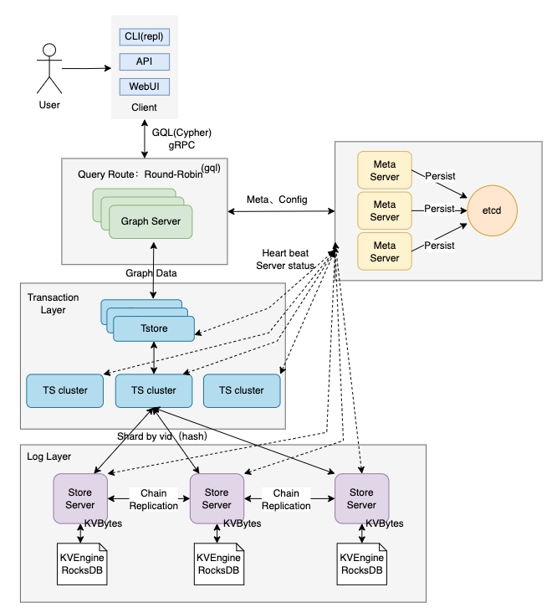 AtlasGraph优势—面向图应用特点深度优化AtlasGraph优势-易于使用,立足标准,支持多种方式灵活构建应用AtlasGraph优势:图计算算法功能丰富、性能优异Atlas图学习架构
AtlasGraph优势—面向图应用特点深度优化AtlasGraph优势-易于使用,立足标准,支持多种方式灵活构建应用AtlasGraph优势:图计算算法功能丰富、性能优异Atlas图学习架构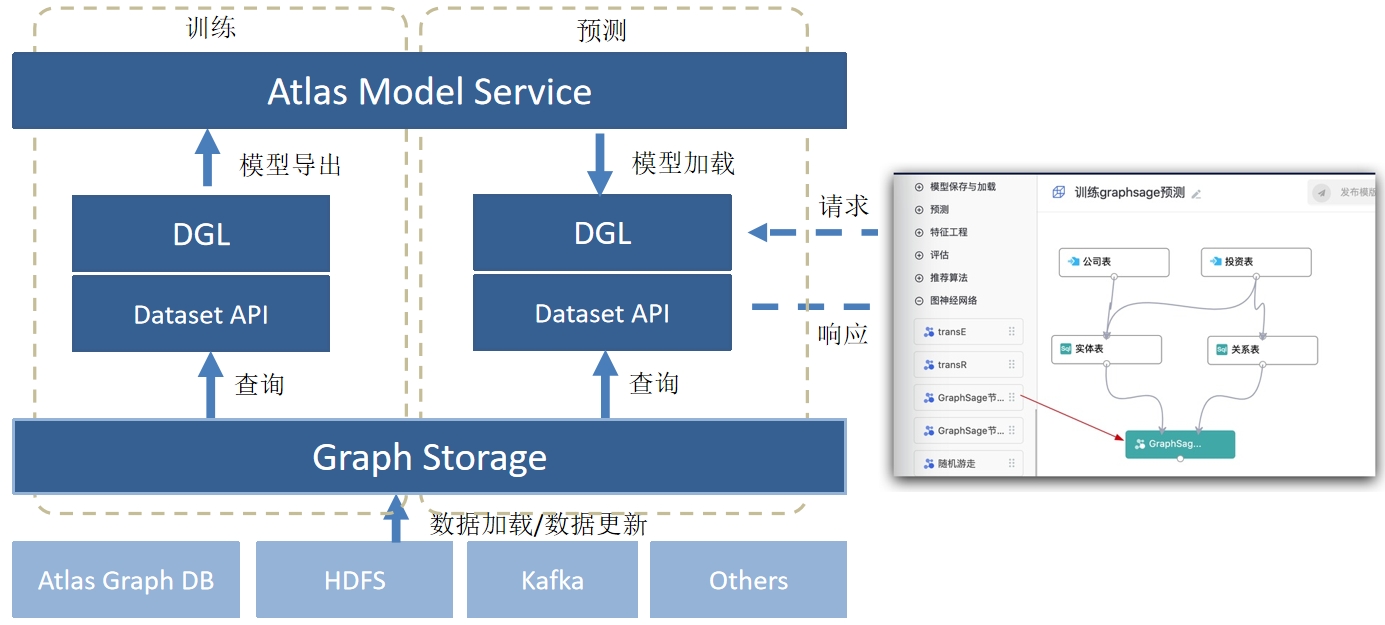 技术创新
技术创新基于图缩减的图计算方法,利用图缩略技术实现摘要图的预计算,极大降低大图上的数据交换频率,提升性能;基于图的三维划分模式,将图的节点中的属性按点划分后分布计算,极大减少集群中不同机器的通信量;图再划分技术,在计算过程中对图进行重划分,提高节点间的信息交互速度,从而显著加快算法的收敛速度、减少迭代轮数;图的磁盘IO缩减策略,最优化数据处理顺序,最大化重用内存数据,降低磁盘IO;分布式图随机游走引擎和基于采样的图随机游走高效计算方法,更准确高效地将多维数据映射成低维数据,从而实现基于交易知识图谱网络的拓扑特征及时序特征进一步挖掘客户间是否存在隐藏关系及客户账户的身份标签;图神经网络高本地性的存储格式,以及在图神经网络中以细胞为单位的请求批处理机制,将图的点边属性存在一起,将神经网络中相似的计算单元统一做批处理和执行,提高训练的效率;时序图的时态信息感知,将时间信息附加到边上,以实现传统静态和动态图的时序特征提取降维,并基于链接预测算法进行了逻辑优化,剔除实体关系冗余特征,并融合关联节点特征,实现图谱链接预测以解决断链问题
界面示例-本体定义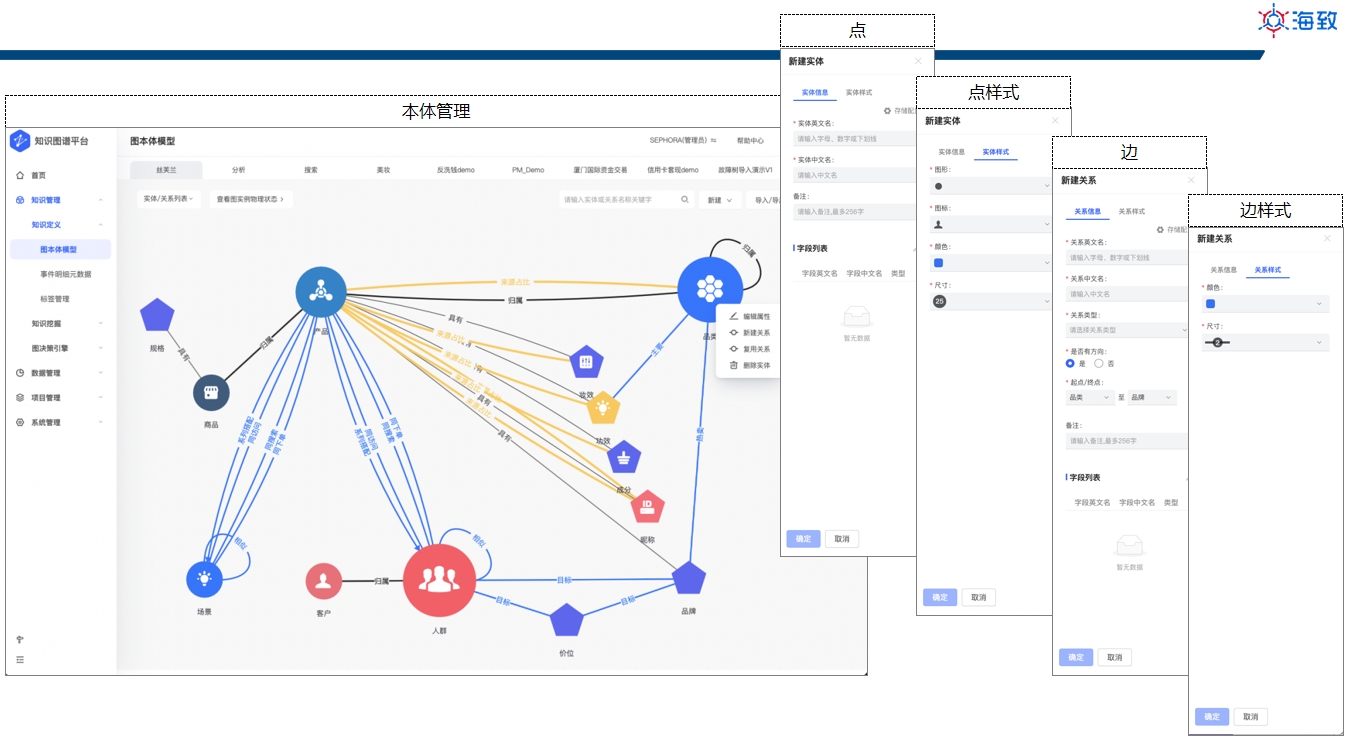 界面示例-图构建
界面示例-图构建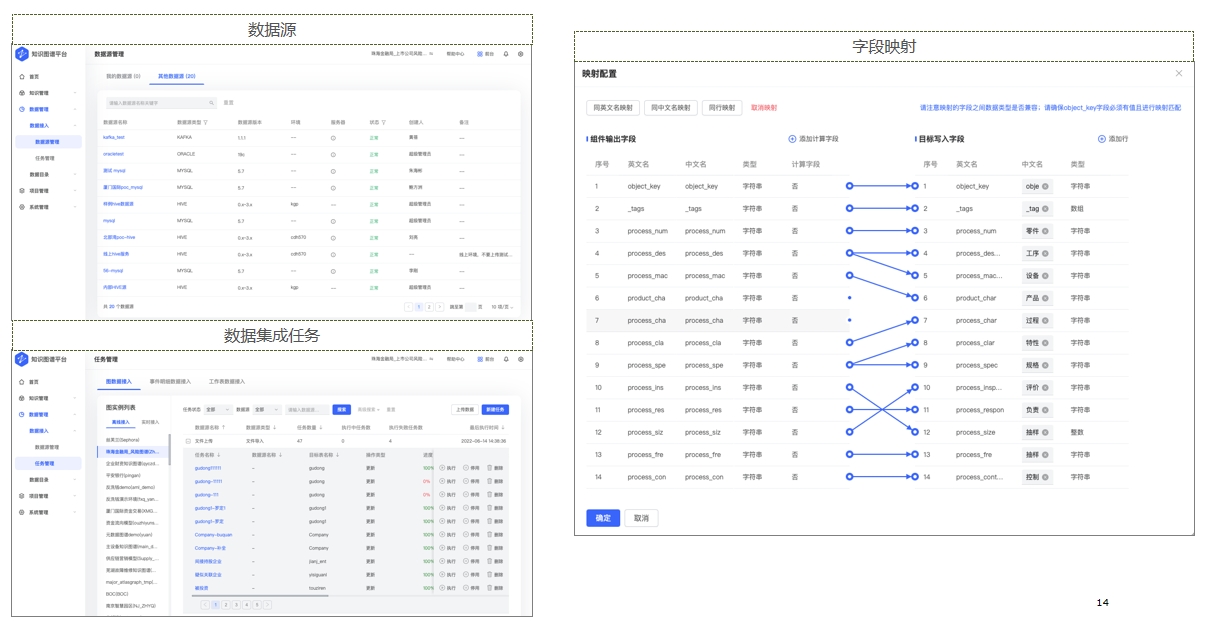 界面示例-图分析
界面示例-图分析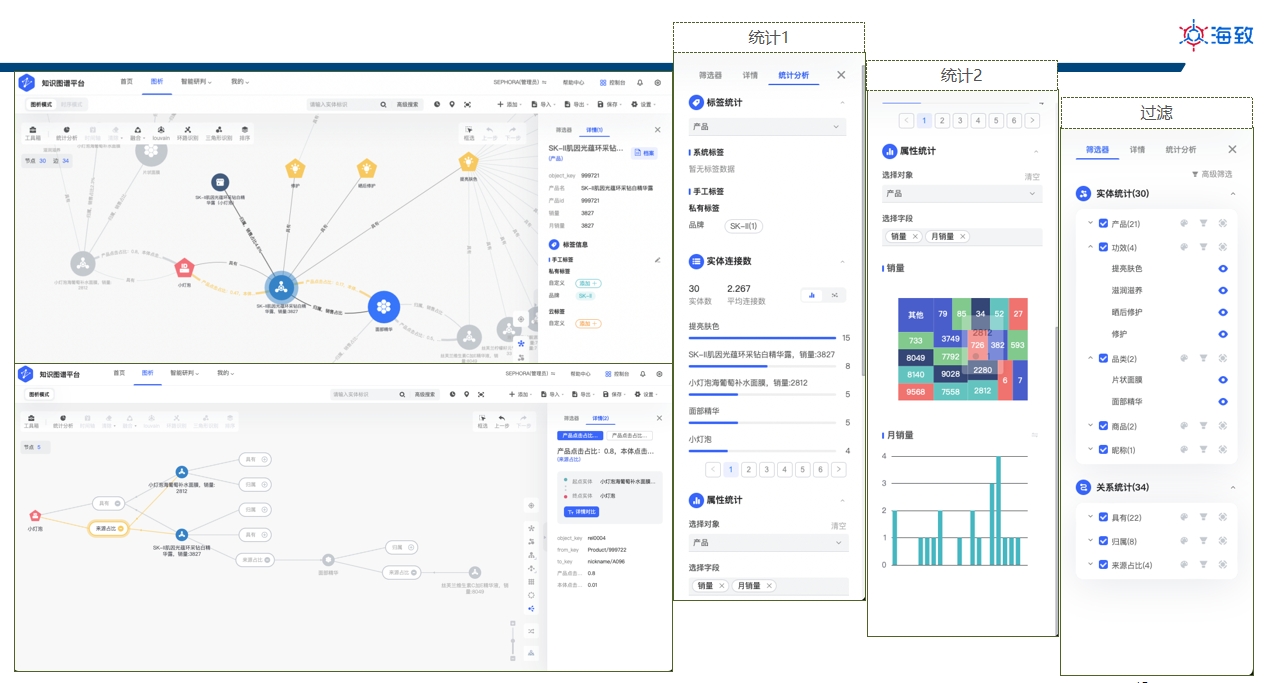 界面示例-图遍历和图排序
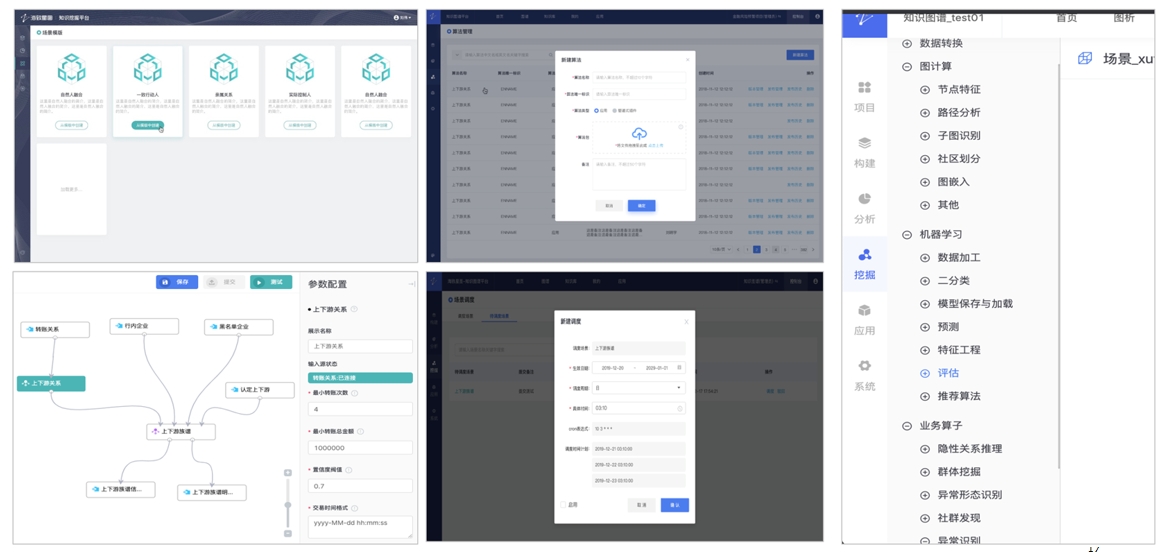
界面示例-图遍历和图排序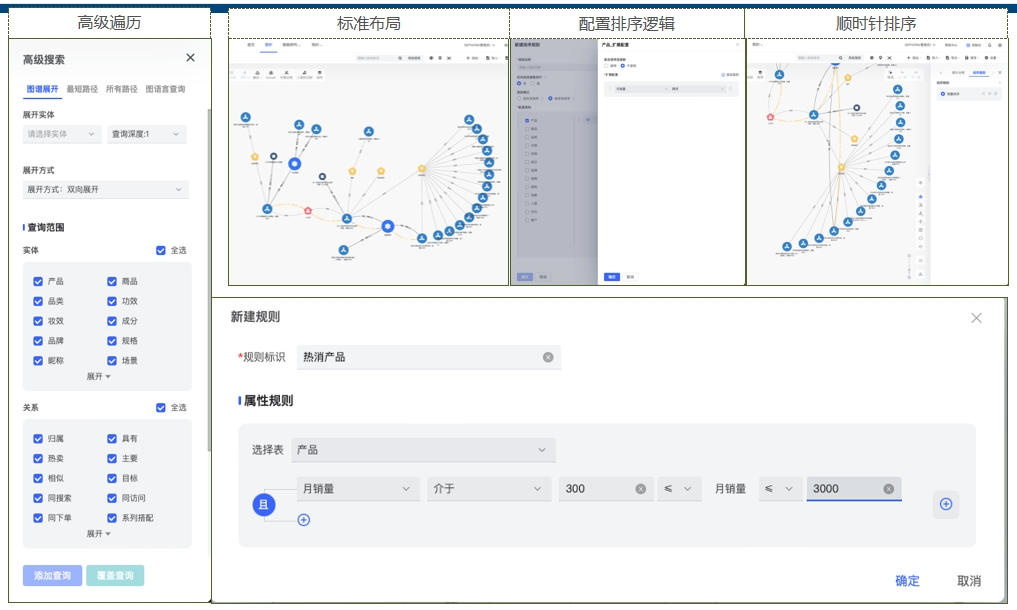 界面示例-图挖掘
界面示例-图挖掘内置丰富的场景模板与图挖掘算法;支持拖拉拽方式快速构建挖掘工作量;支持自定义算法与任务调度。
界面示例-局部图算法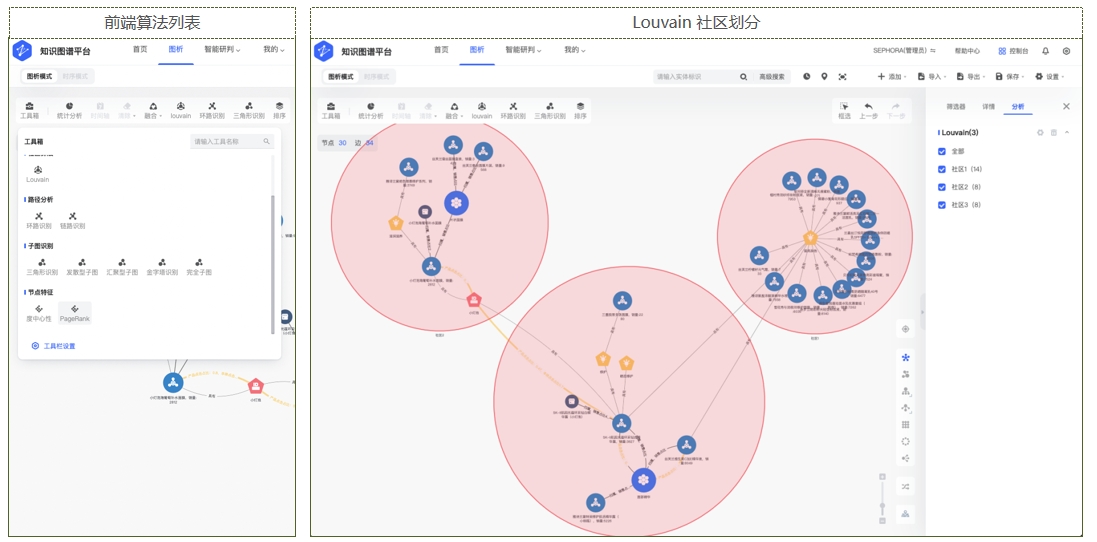 界面示例-时序模式
界面示例-时序模式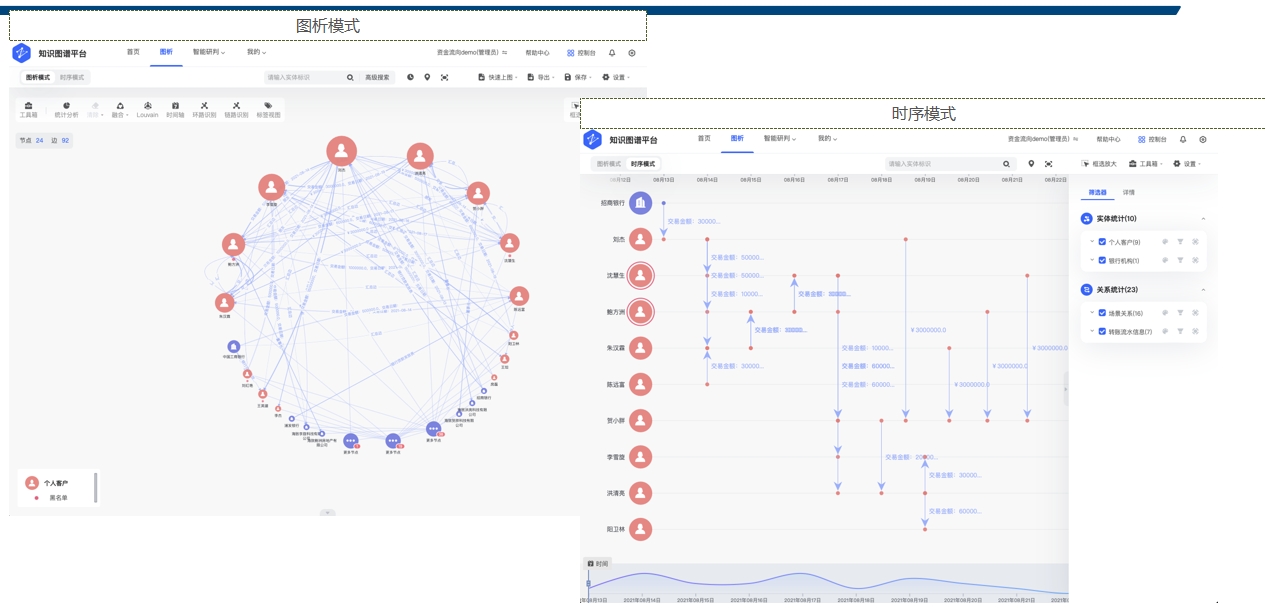 当前图的典型应用场景
当前图的典型应用场景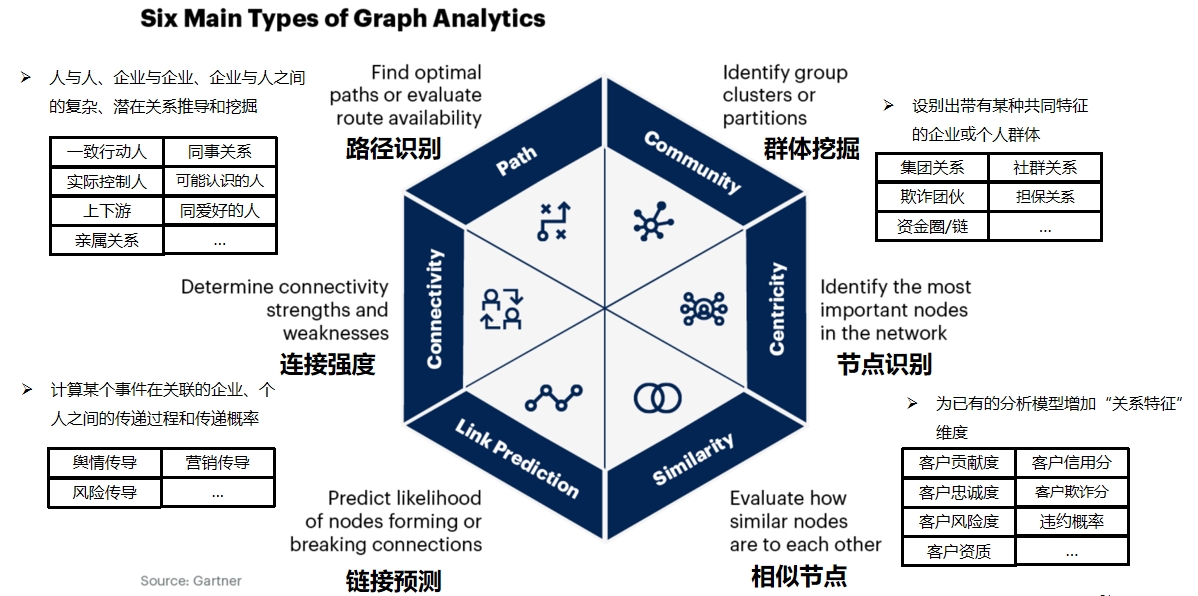 “世界是复杂关系的总和”—— 一张典型的金融知识图谱
“世界是复杂关系的总和”—— 一张典型的金融知识图谱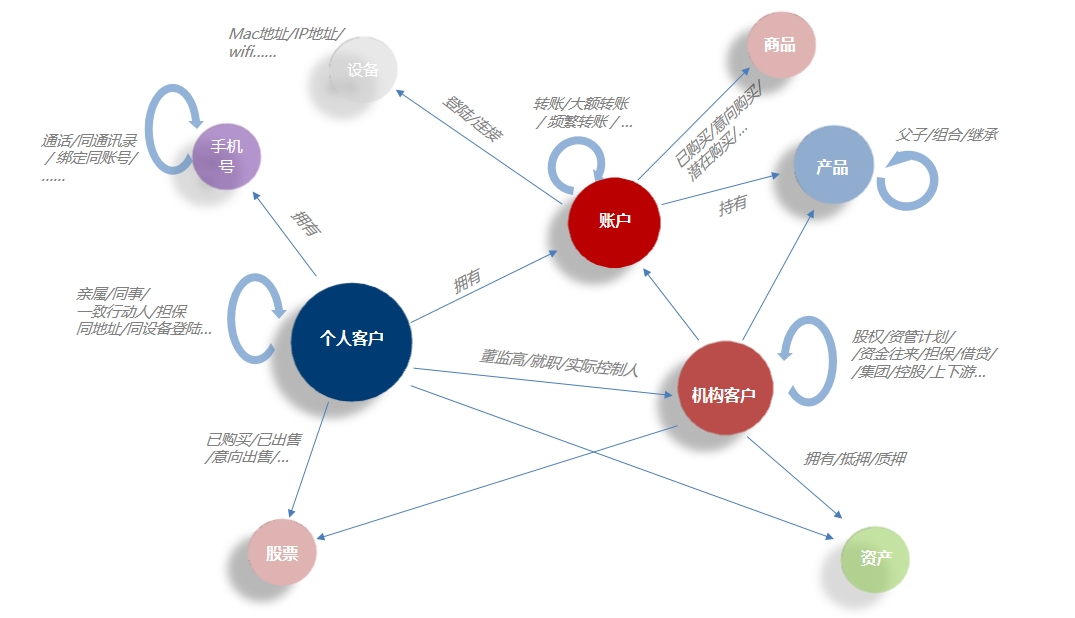 图平台是数据中台的重要组成部分
图平台是数据中台的重要组成部分 构建企业级图数据资产标准
构建企业级图数据资产标准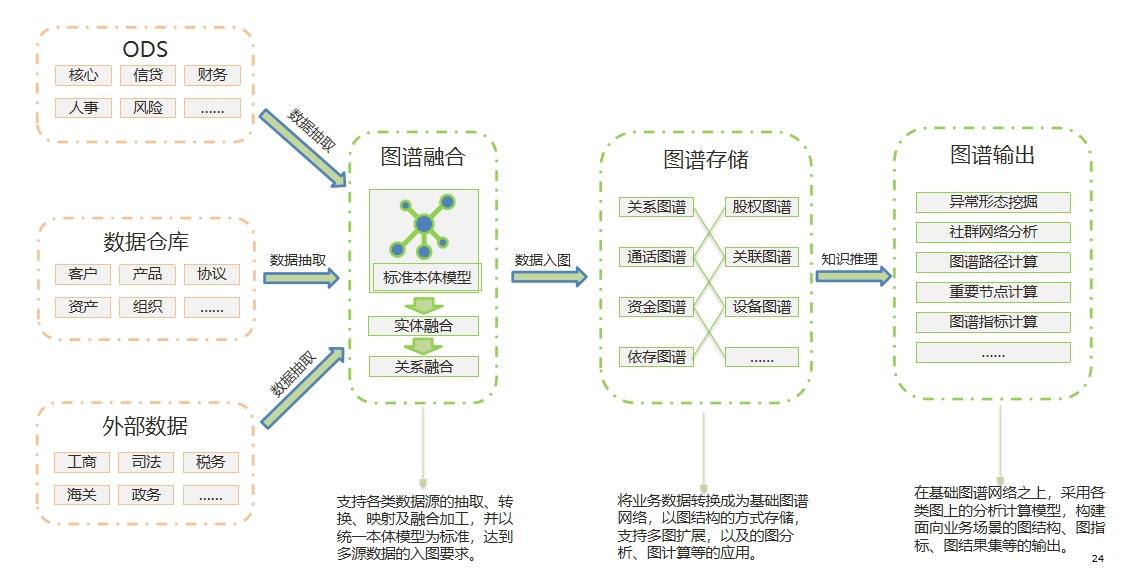 应用场景示例
应用场景示例 应用示例:对公营销
应用示例:对公营销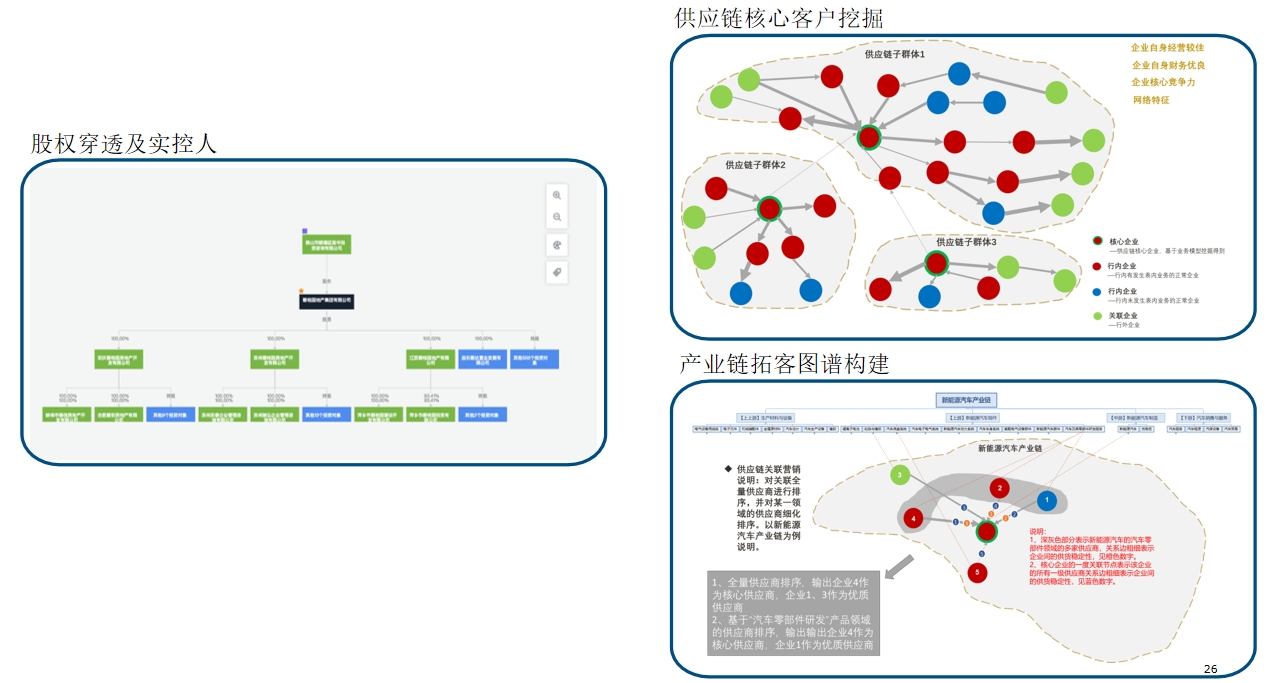 应用示例:对公风控
应用示例:对公风控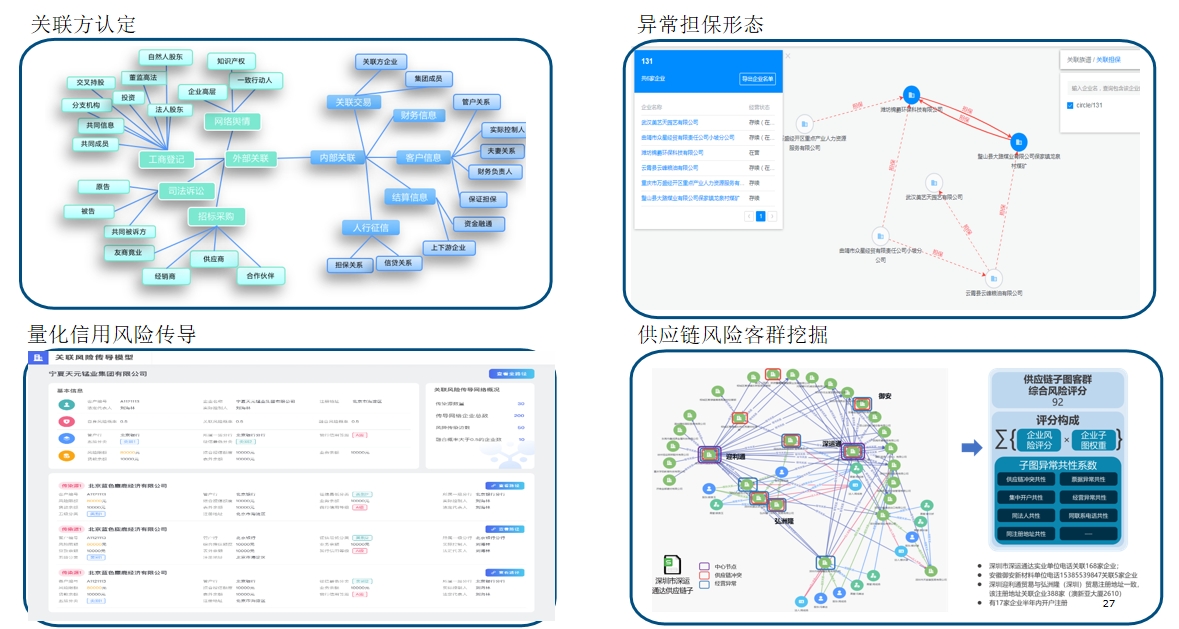 应用示例:零售风控
应用示例:零售风控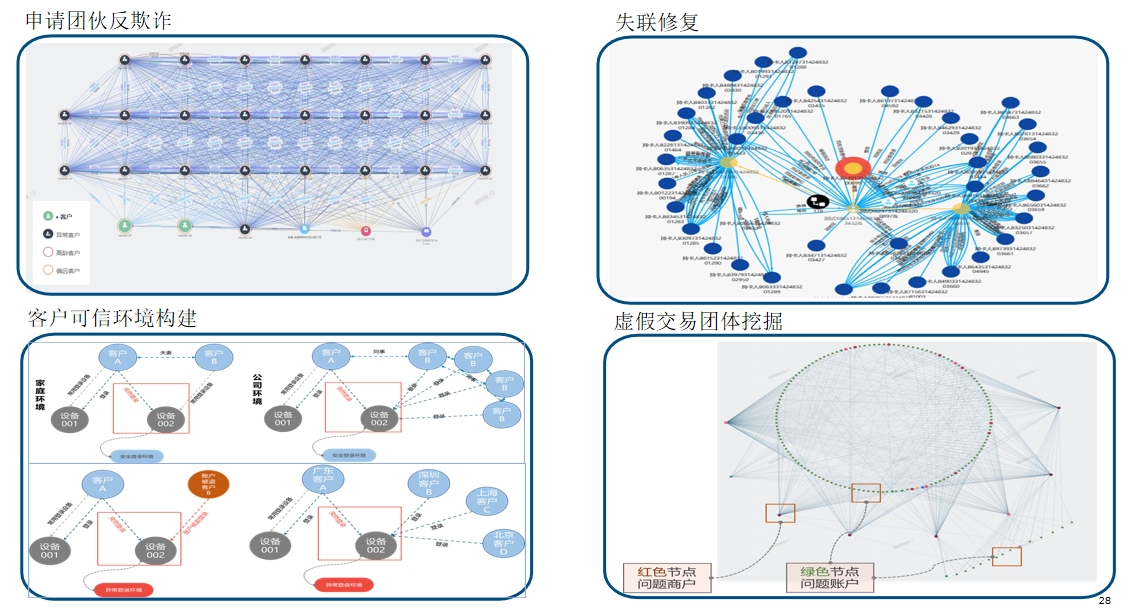 应用示例:运营管控
应用示例:运营管控 应用示例:审计
应用示例:审计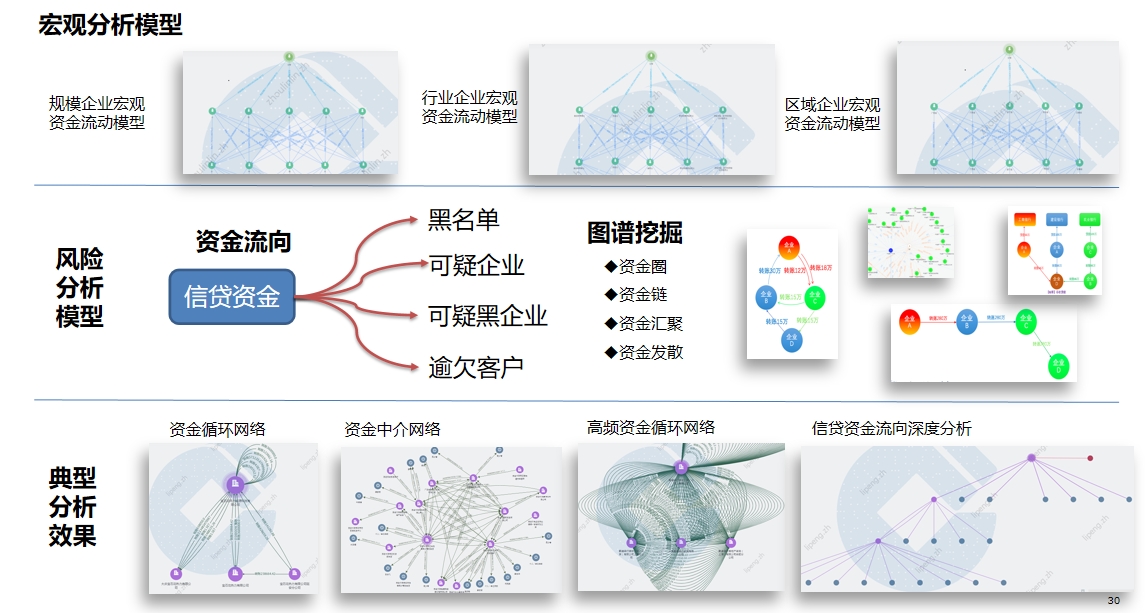 应用示例:产业链事理图谱
应用示例:产业链事理图谱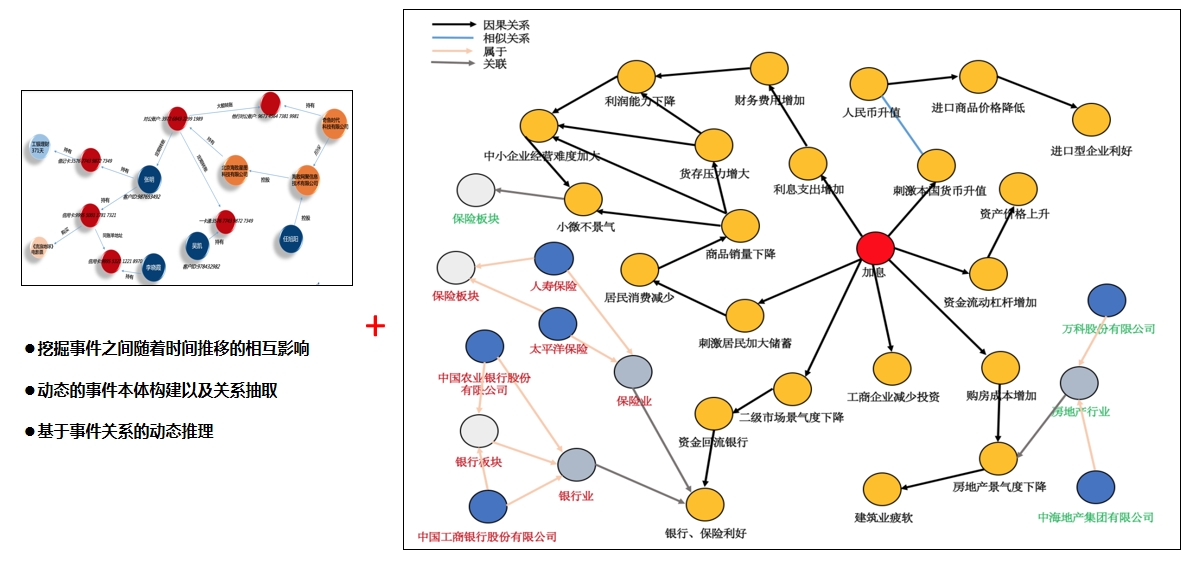 应用示例:基于图的指标多维分析
应用示例:基于图的指标多维分析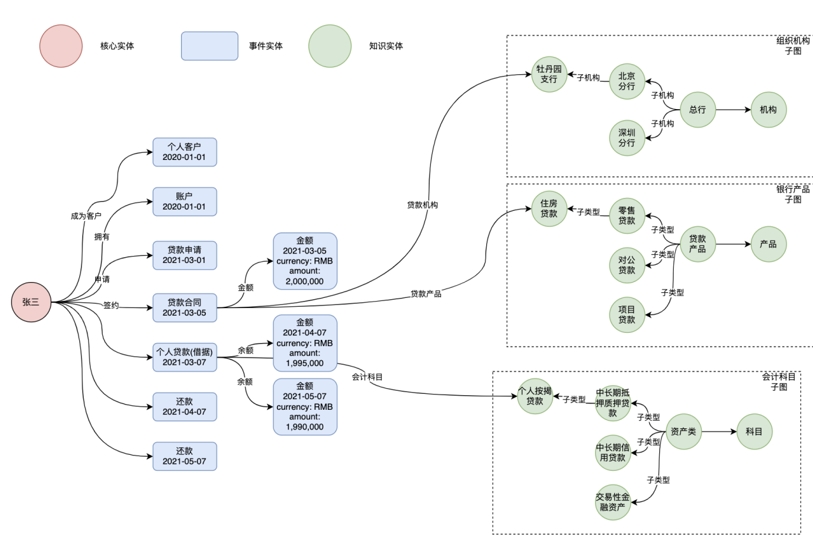 基于图的指标多维分析(续)
基于图的指标多维分析(续)可视化构建,图形化表示指标语义,这些表示可以存到知识层,支持复用和程序化执行,支持自动预汇总。支持从不同视角分析,无需提前创建宽表,综合计算效率高,一次扫描计算多个指标,没有递归SQL的复杂性。
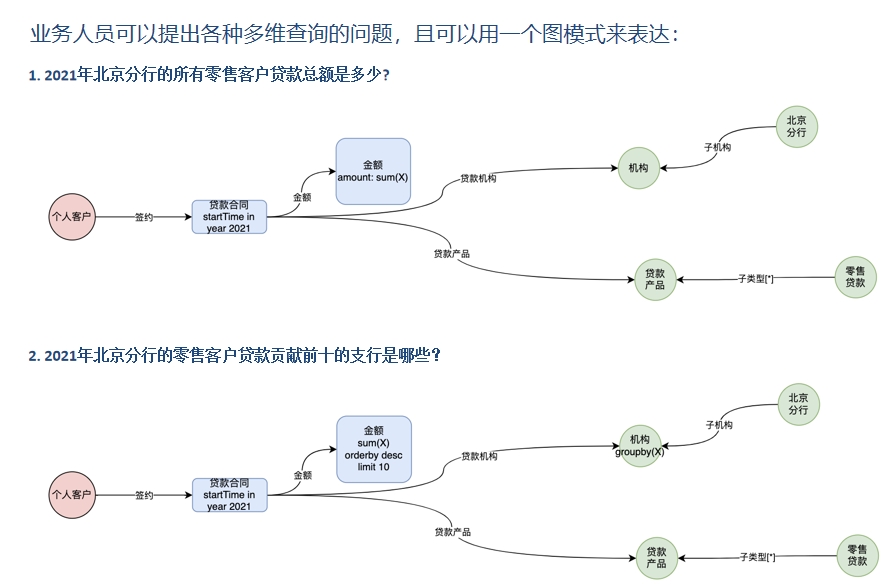
基于图的多维指标分析应用效果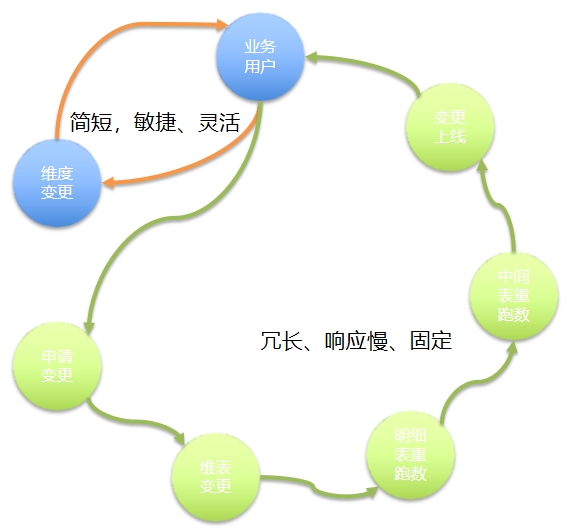 应用示例:数据血缘分析
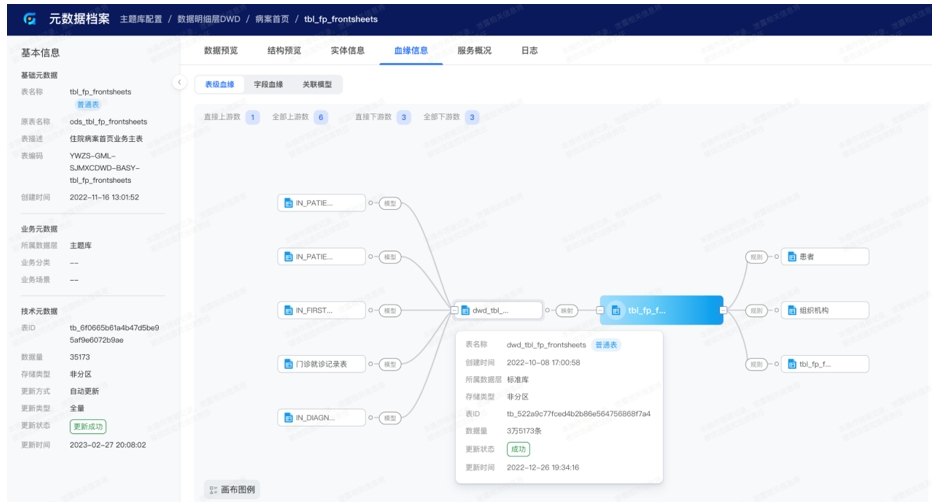
应用示例:数据血缘分析在元数据档案中,可以查看每个数据资产的血缘信息,包含表级血缘、字段血缘、关联模型等。实现数据资产从数据源端到用户端全链路血缘查看和分析,例如数据主人分析、数据来源分析、数据层次分析、数据价值评估、数据消费分析、数据溯源等。
元数据影响分析在元数据图谱基础上,可以进行数据资产的影响性分析。针对当前分析对象,通过知识图谱的路径扩展能力,评估数据变更对数据应用的影响。影响性分析能帮助用户迅速了解分析当前元数据对象的下游数据信息,快速识别元数据的价值,掌握元数据变更可能造成的影响,以便更有效的评估变化带来的风险。

元数据图谱分析在元数据图谱基础上,针对特定的数据资产,通过知识图谱分析能力,进行数据资产的图分析、图查询,以可视化交互的方式,方便数据管理运营人员进行数据资产链路及血缘的拓展及推演。

数据核心资产及链路查询在元数据图谱基础上,开展核心资产识别及数据链路查询。通过知识图谱的路径分析能力,进行数据资产全链路查询分析,并通过例如中心点分析、PageRank、社群分析等图算法能力,从元数据定义、应用情况、价值密度、数据质量等维度,进行核心数据资产识别以及重复数据资产识别治理等工作。
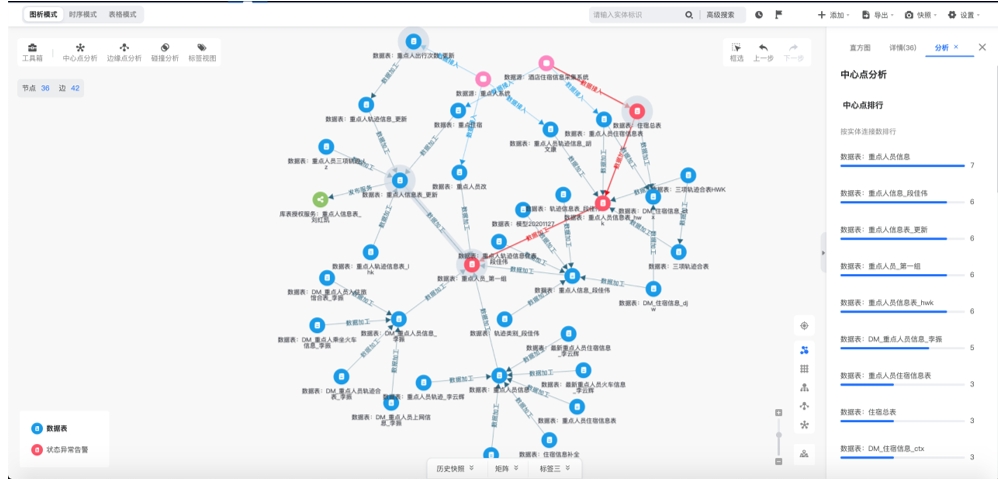
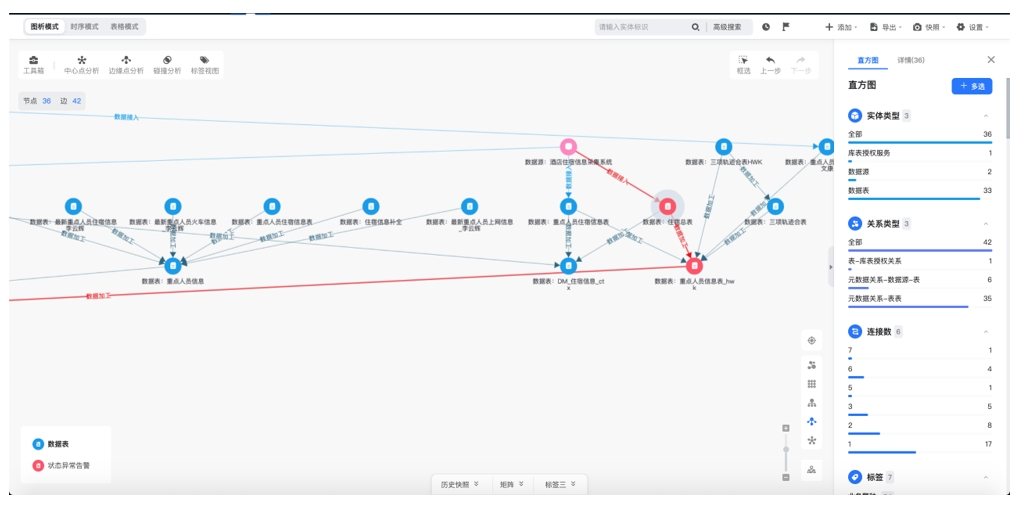
数据链路监测质控在元数据图谱基础上,进行核心业务数据链路提取、数据加工任务监控等建设内容,实现应用链路监控、状态异常告警、错误定位分析等,从而辅助数据运营管理人员快速发现和定位数据问题及根因,提高数据运营能力。
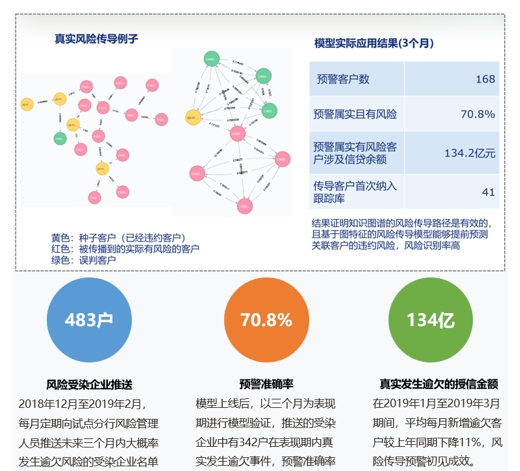
案例:建设银行全行级图平台建设2017年底,建行先以图数据库的图存储及GRAPHX的图计算能力做信用风险传导图场景的应用实现。基于特定风险事件与关系网络形成的特定传导路径,构建企业风险传导模型,输出企业的整体风险、传染源头及传染路径,为业务风险管理提供业务支撑。
2018年中,建行厦开领了大数据云平台的建设规划任务把知识图谱组件当做了数据挖掘层的核心组件,因而产生了图数据分析挖掘和应用隔离的图分析平台的设计逻辑;随着图分析平台架构的完善以及作用放大,经过与整体大数据云平台对接融合,形成现在的全行级架构,并全面赋能知识图谱应用落地。
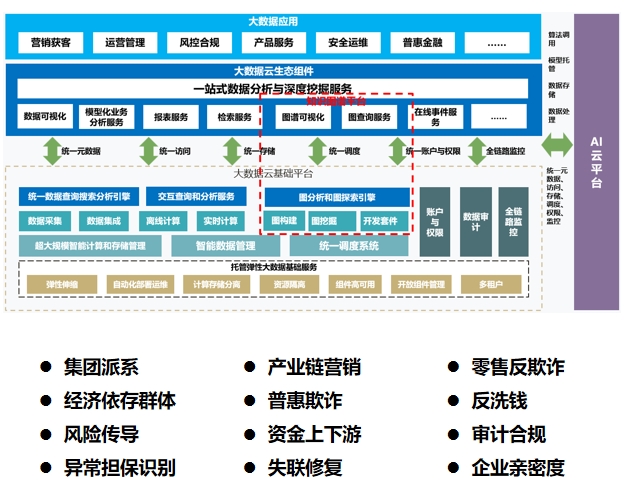
随着多个图谱项目的实际落地应用,也暴露出各项目独立开发建设过程中,存在图数据标准体系建设、图计算资源整合应用、图平台运维标准化、图数据权限控制体系、图知识服务输出标准等诸多方面的重复投入和各自为战的不足。能否构建一个完备且体系化的数据管理体系是支撑行内图谱长远化、稳定化、多元化发展的前提条件,所以需要从一个大且全面的视角构建和完备全行图数据体系的建设。
建设银行图数据资产盘点建设银行内部分为金融知识图谱、通用知识图谱、其他知识图谱三大部分,2023年将逐步对其他知识图谱进行统一上收。目前行内图数据库集群规模达到30+节点,经过图仓的本体合并、明细汇总等操作,总体图数据量大约在700亿,其中实体大约在50亿+关系大约在600亿+。

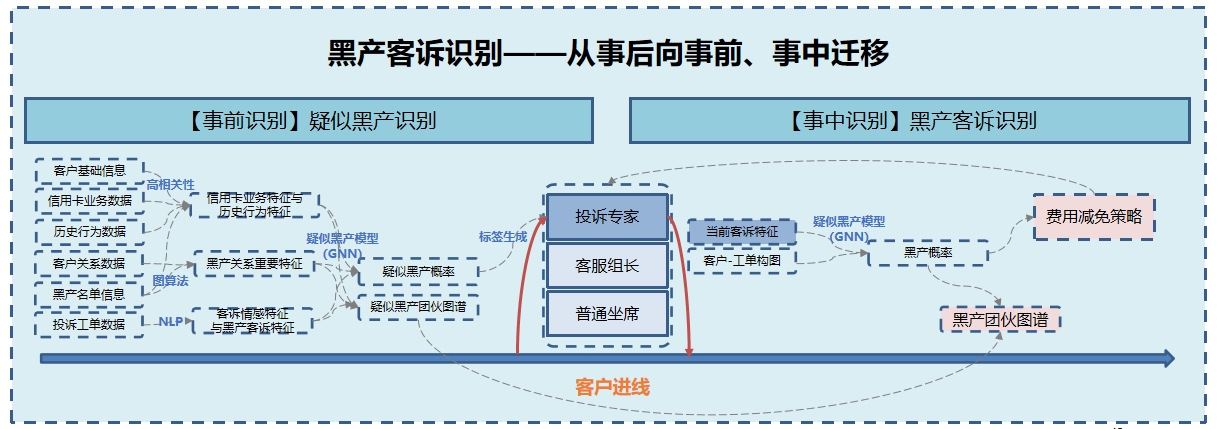
案例:图神经网络赋能平安银行黑产客诉识别近年来银行各业务条线的不良率上升,其中零售、信用卡等借贷不良业务增量突出,继各大银行对息费调减尺度开放之后,涌现出大量攻略(代办,非代办)客户,客户投诉案件呈现迅猛攀升的趋势。为了打击黑产攻略客户投诉带来的业务冲击,某股份制银行信用卡中心基于客户基础属性、全量历史交互轨迹、全量录音文本及客户知识图谱关系网络等信息搭建智能黑产识别模型,帮助客户团队在接线时识别对攻略客户作出概率预判,有效应对。
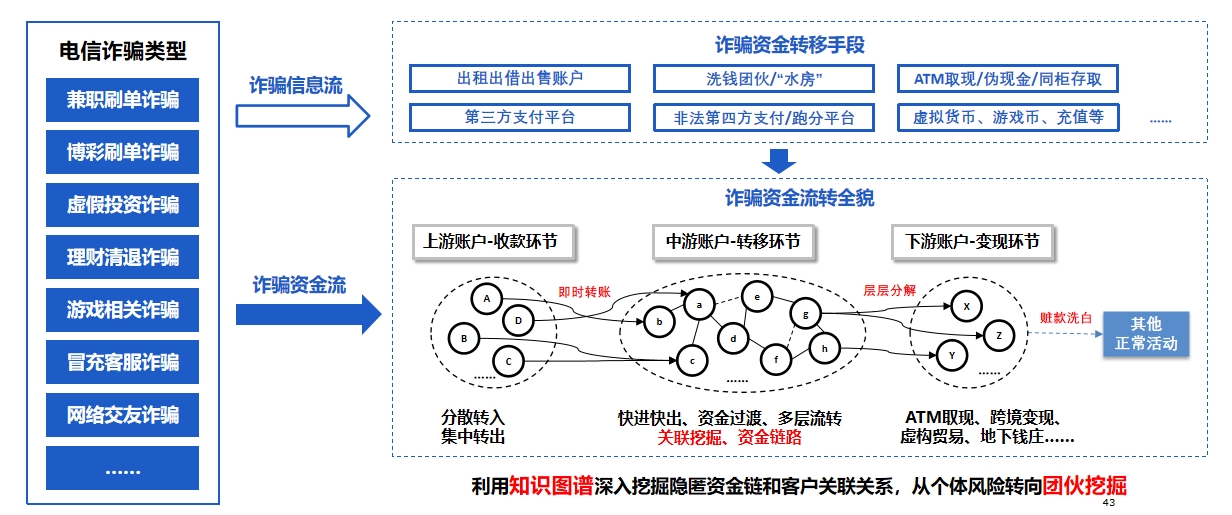
案例:图计算赋能反电诈公安部门总结10大类、48子类常见的电信网络诈骗,各种诈骗模式在信息流中各有差异、在资金流特征存在共性特征,基于不同诈骗类型的共性和个性特征,建立以专家规则、机器学习与图算法结合的可疑行为与交易监测模型。
反电诈模型体系建设 疑似电诈团伙识别
疑似电诈团伙识别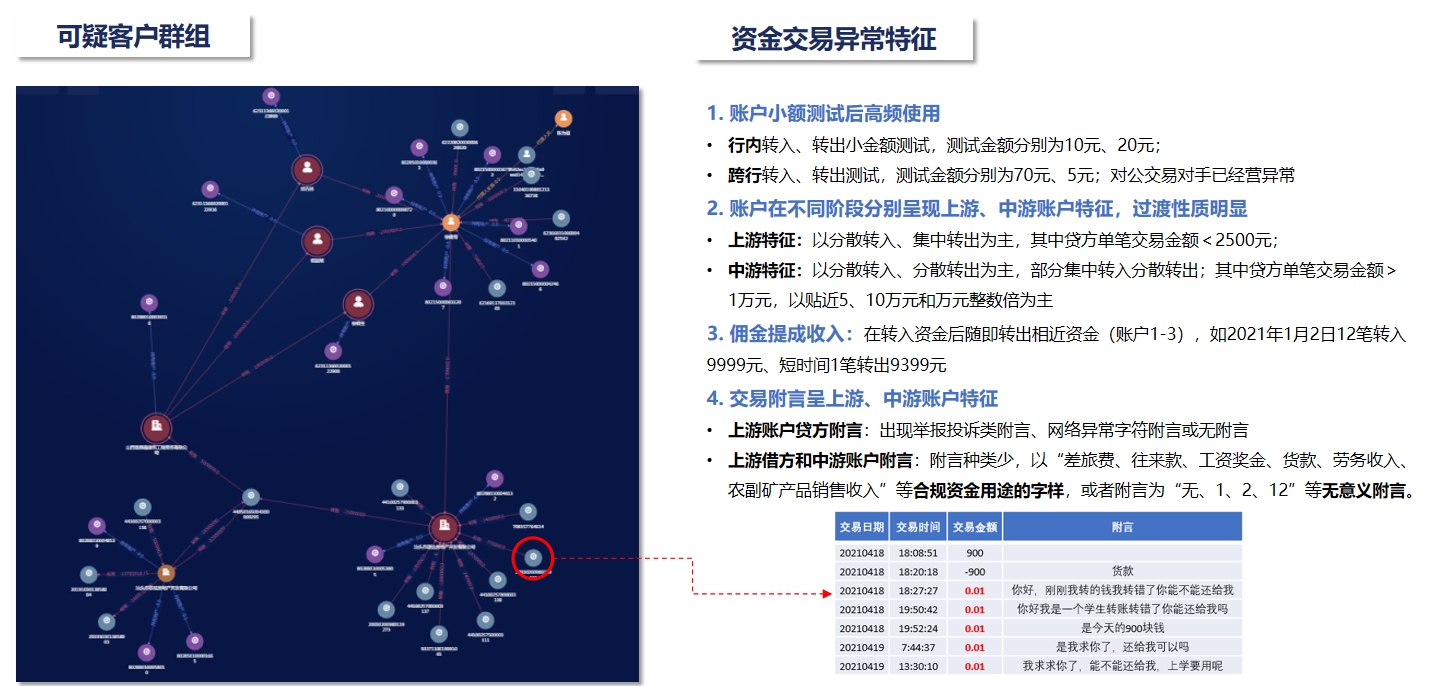
TDSQL-C 是腾讯云自主研发的云原生分布式数据库。融合了传统数据库、云计算与新硬件技术的优势,100%兼容 MySQL 和 PostgreSQL, 实现超百万级 QPS 的高吞吐,128TB 海量分布式智能存储,保障数据安全可靠。
100%兼容开源数据库引擎MySQL5.7 和 PostgreSQL10
具有商用数据库的强劲性能,最高性能是MySQL数据库的八倍
计算节点实现无状态,支持本地和跨设备的秒级故障切换和恢复
集群支持安全组和VPC 网络隔离















领先的企业数字化服务平台
客服电话:400-0972-788

