







腾讯云向量数据库
立即咨询
 首页
首页 向量数据库是AGI时代重要的基础设施
向量数据库是AGI时代重要的基础设施LLM推动了AI应用的发展(内容生成、效率工具、聊天伴侣…)
向量数据库是必备的基础设施
 向量数据库应用场景覆盖AI全生命周期
向量数据库应用场景覆盖AI全生命周期
 源自集团多年沉淀,产品能力领先
源自集团多年沉淀,产品能力领先源自腾讯集团自研向量检索引擎OLAMA,自2019年上线至今,经过5年打磨,集团内
部已有40+业务线上使用,覆盖搜索、推荐、AI场景,日均处理1600亿次检索请求。
 高性能、大规模、低成本:AGI时代向量数据库的必备特性
高性能、大规模、低成本:AGI时代向量数据库的必备特性面向在线业务场景设计,「首家」通过信通院标准测试和性能规模测试,性能、成本行业领先
 AI原生分布式架构:功能丰富,安全稳定
AI原生分布式架构:功能丰富,安全稳定 架构再升级:支持数据分区管理,检索速度更快
架构再升级:支持数据分区管理,检索速度更快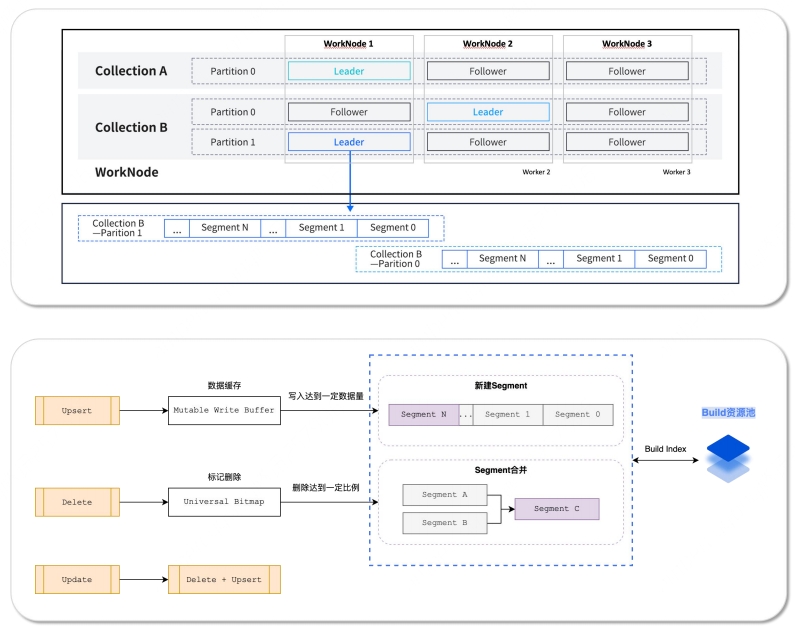 端到端AI套件:RAG知识检索方案
端到端AI套件:RAG知识检索方案自动化、低代码、高质量
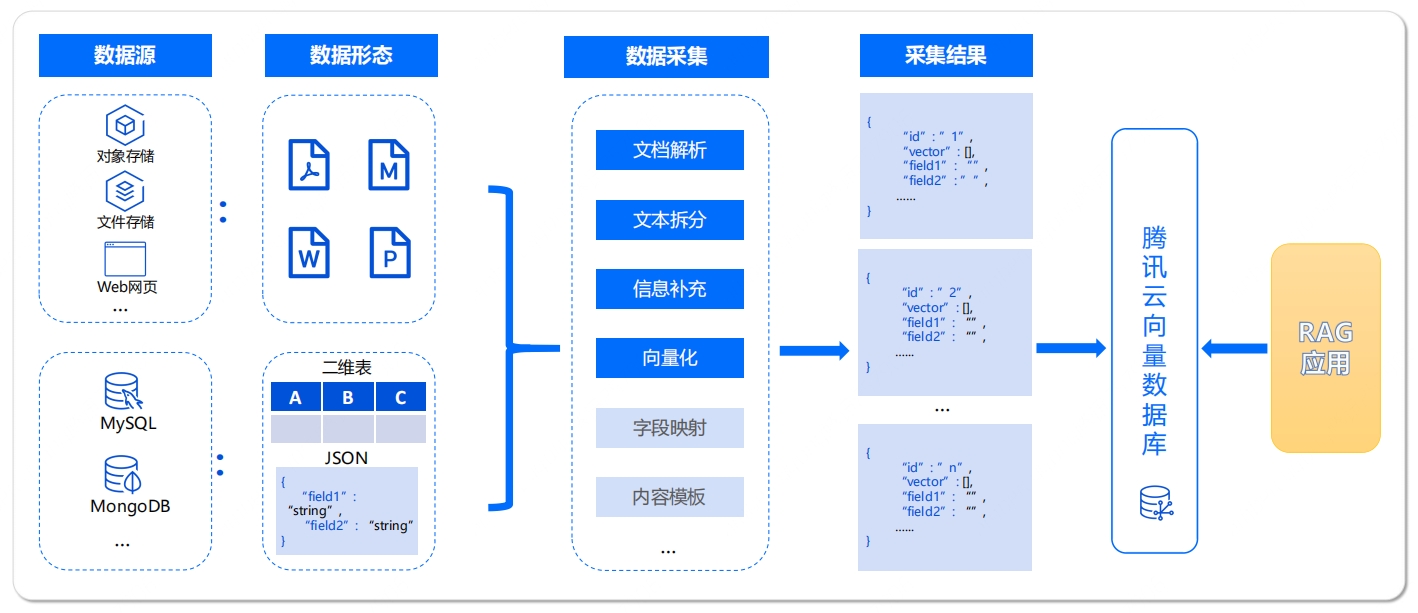
 数据采集平台:快速提取多源数据,自动构建高质量索引
数据采集平台:快速提取多源数据,自动构建高质量索引企业数据接入AI的痛点:
➢ 搜不全:知识数据分散存储,包含文件、数据库、网页等多种存储方式,无法实现全面检索,数据利用效率低
➢ 搜不准:原始数据预处理、解析等环节处理不当均会影响搜索效果,工程化细节多,质量难保障
➢ 难管理:异构数据难整合,结构化、非结构化数据难以统一存储形态,智能化数据管理难实现
多源结构化/非结构化数据自动化入库,快速搭建智能知识中台
 向量数据库可以作为RAG应用的统一数据接口
向量数据库可以作为RAG应用的统一数据接口
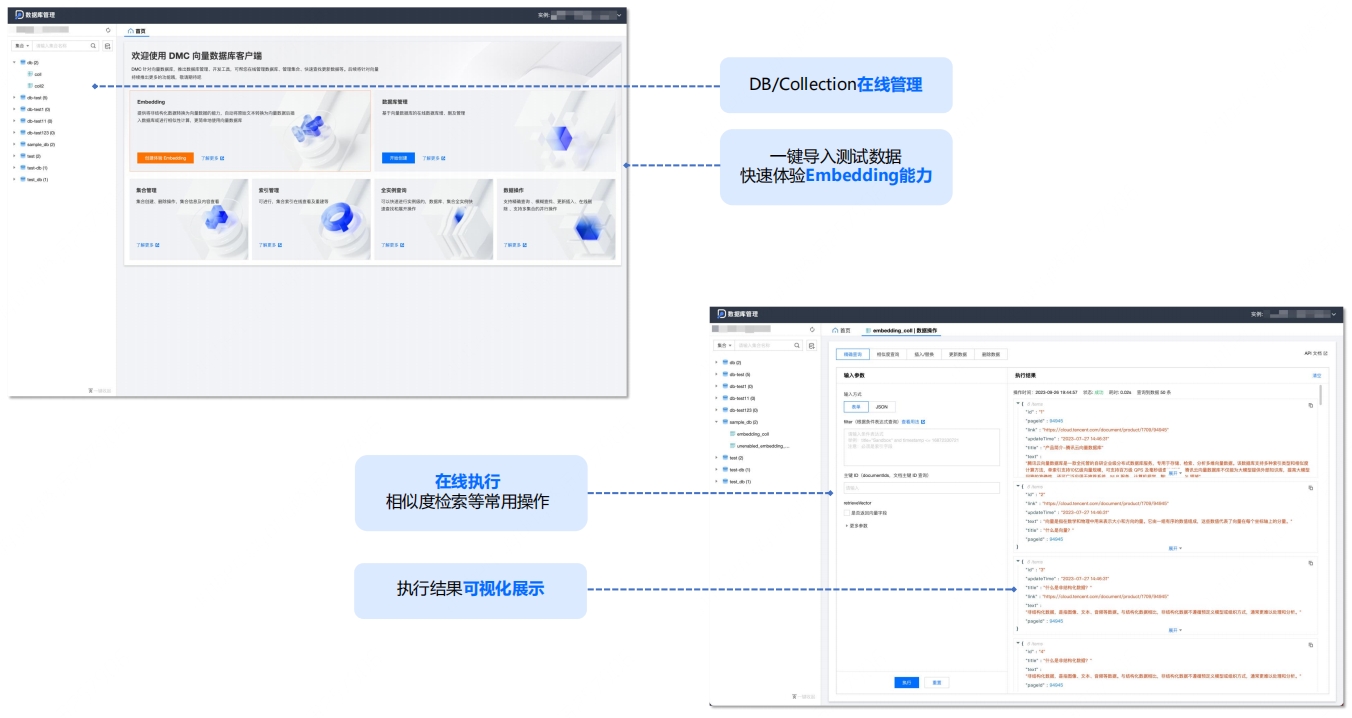
 可视化管理:数据在线预览,测试、运维更高效
可视化管理:数据在线预览,测试、运维更高效
 应用场景
应用场景腾讯云向量数据库已服务2000+客户
 RAG应用需求大,搜索/推荐仍是核心场景
RAG应用需求大,搜索/推荐仍是核心场景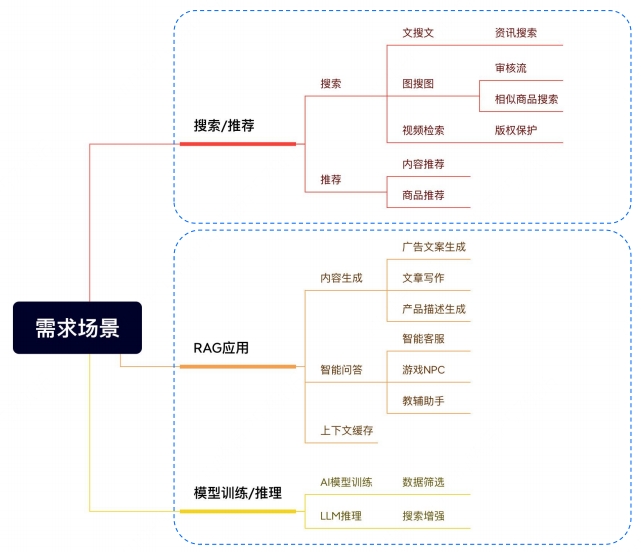 向量数据库+LLM实现RAG应用
向量数据库+LLM实现RAG应用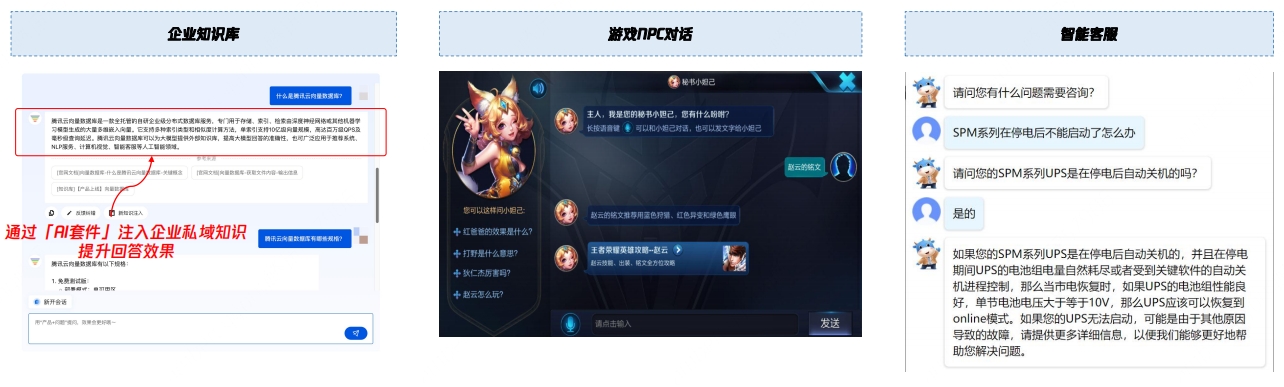 推荐/搜索场景融合向量检索进行多路召回
推荐/搜索场景融合向量检索进行多路召回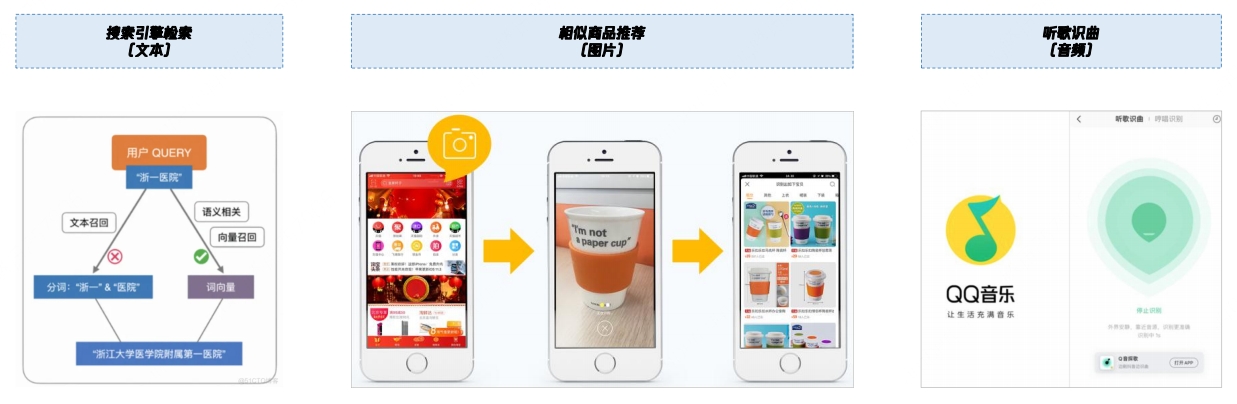 LLM借助向量数据库进行搜索增强,缓解模型幻觉
LLM借助向量数据库进行搜索增强,缓解模型幻觉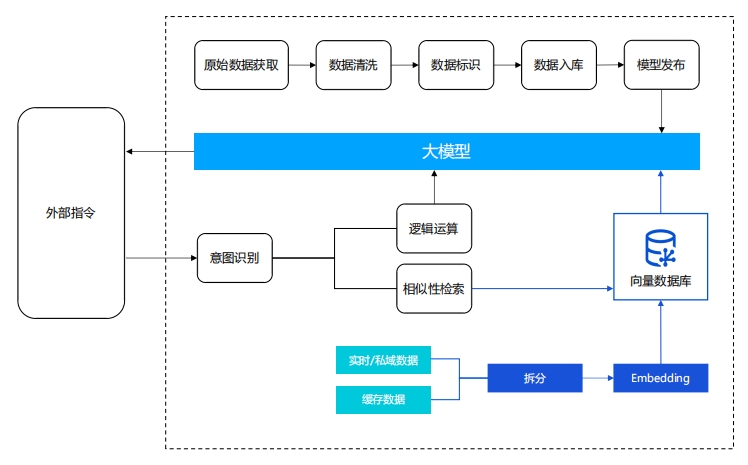 向量应用场景一览表
向量应用场景一览表
 VectorDB VS Milvus
VectorDB VS Milvus
 性能和成本对比
性能和成本对比

产品推荐

SphereEx DBPlusSuites数据安全合规解决方案支持数据自动采集识别与人工上报离线数据相结合,解决数据不外流条件敏感数据识别。支持多种数据源,包括MySQL、PostgreSQL、 Oracle、SQLServer、openGauss及其他符合上述标准及SQL92规范的数据源。支持多种数据规范的合规性识别,包括GDPR、GB35273等,并支持动态扩展。识别数据风险,给出安全规范及可行实施建议,方便落地。

数阔八爪鱼RPA软件机器人可以按照指定的流程自动操作任意计算机软件甚至硬件设备以实现流程自动化,八爪鱼也是RPA的一个分支,以往我们积累了大量未来RPA产品的潜在用户,有很好用户基础,同时多年的开发经验让我们积累了大量的Web自动化以及SaaS的相关技术沉淀。

在国家教育2.0,互联网+教育政策的推动下,腾讯乐享SAAS平台结合了腾讯多平台资源,为教育主管部门,学校、教师、学生提供智慧教学、智慧宣传、智慧师训、智慧校友等场景的解决方案,让教育实实在在的智慧化。

Talend Open Studio for Big Data通过拖放式UI和预构建的连接器和组件可帮助您更快地进行开发。利用云,Hadoop和NoSQL数据库。自定义和创建组件或利用社区组件和代码来扩展您的项目。



