







阿里云Databricks数据洞察
立即咨询
 首页
首页 阿里云Databricks数据洞察
阿里云Databricks数据洞察 产品优势功能特性
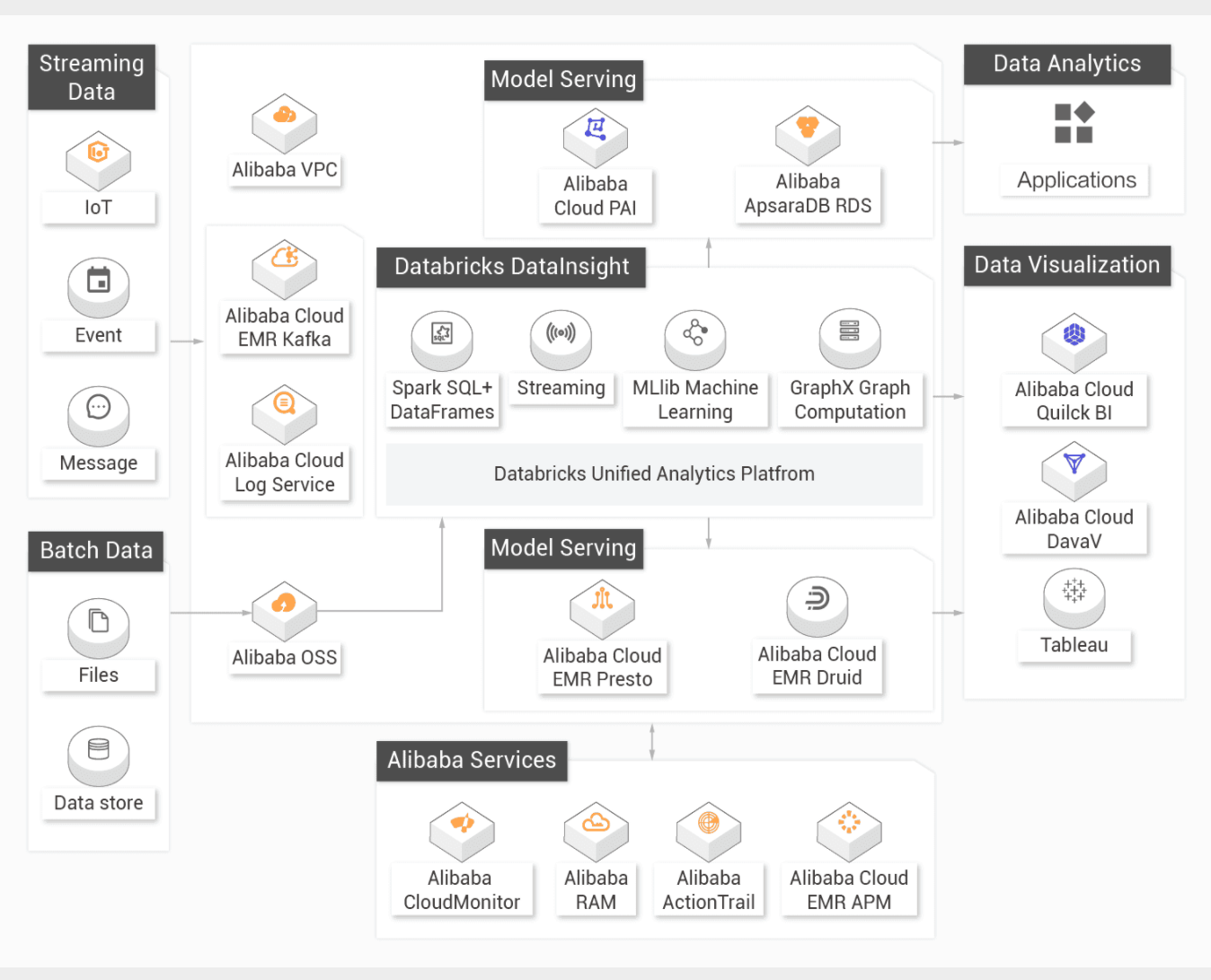
产品优势功能特性Databricks数据洞察包含了完整的社区版Spark的功能和特性,全面兼容Apache Spark。 Databricks数据洞察包含以下组件:
产品架构Databricks数据洞察构建在ECS之上,使用阿里云对象存储服务(OSS)为核心存储。本文介绍Databricks数据洞察的产品架构。 存储访问加速层方便您可以像操作HDFS上的数据一样访问OSS上的数据。 目前,Databricks数据洞察提供了两种执行Spark作业的方式,包括通过Notebook或者在项目空间里新建Spark作业。同时,Databricks数据洞察还提供了监控告警、元数据管理、权限管理等功能,方便您对集群资源进行管理。

产品功能应用场景—流批一体数据仓库统一的大数据管理平台,从上游数据抽取到下游数据分析,贯穿整个数据分析工作流。自动扩缩容,免运维,降低运维成本。
应用场景—机器学习简化机器学习生命周期,快速进行模型测试、实验、以及生产部署,并可视化结果。

产品推荐

云硬盘(Elastic Volume Service)是一种为ECS、BMS等计算服务提供持久性块存储的服务,通过数据冗余和缓存加速等多项技术,提供高可用性和持久性,以及稳定的低时延性能。您可以对云硬盘做格式化、创建文件系统等操作,并对数据做持久化存储

有赞新零售母婴集合店解决方案,“流量”变“留量” ,高效沉淀私域客户池,线上线下一体化经营,支持统计整体加客户情况、单个员工添加情况,通过数据发现问题、调整策略,避免盲目行动。一键布局渠道活码,高效引流获客,覆盖各种经营场景。

京东云安全托管运营解决方案,针对日常运营潜在风险(漏洞&基线),具备安全工单自动化流转能力。面向混合多云场景,具备快速对接第三方资产平台的能力。提高日常运营人员效率:打造典型安全运营治理流程,实现场景化安全运营降低使用门槛。




