






 首页
首页浅谈机器学习是怎样去工作的?
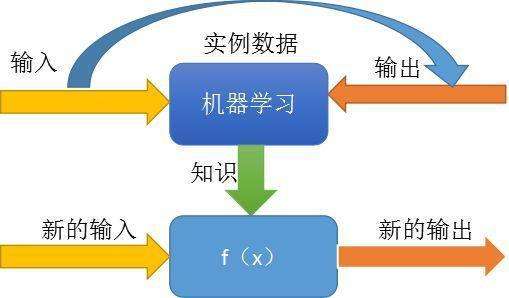
一些人想要去了解机器学习是如何工作的,我很遗憾地告诉所有的读者,如果你对数学恐惧那么想要完全理解大多数机器学习算法,就需要对一些重要的数学概念有一个基本的理解。 但不要害怕! 你需要理解的概念很简单,你也可以从你可能学到的教训中吸取教训。
机器学习主要用到的数学知识有线性代数,微积分,概率和统计。
Top 3线性代数概念:1.特征值/特征向量;2.向量空间和范数3.矩阵运算;
Top 3统计概念:1.Bayes定理;2.组合学;3.抽样方法
Top 3微积分概念:1.向量-值函数;2.偏导数;3.方向梯度

其实,只要你对数学有了基本的理解,就可以开始发展思考整个机器学习的学习活动过程了。
主要有五个主要步骤:
让我们回顾一下算法的一些常见分组:
回归算法
机器学习要用到Logistic回归设计来预测离散值。有两种,以及企业所有其他回归分析算法,都以它们的速度而闻名,它们一直是最快速的机器进行学习相关算法之一。 也是最流行的机器学习算法。 线性回归算法是一种基于连续变量的监督学习算法。
决策树算法
机器学习要用到决策树算法一组“弱”学习在一起,形成一个强大的算法,在树结构,学习组织,每个分支。一种社会流行的决策树学习算法是随机森林算法。在该算法中,弱学习是随机选择的,这往往是一个强有力的预测。在下面的例子中,我们教师可以通过发现存在许多企业共同的特征,它们之间都不足以单独识别动物。当然,我们把所有这些观察到的可以结合生活在一起时,我们就能形成自己一个更完整的画面,并做出更准确的预测。
贝叶斯算法
机器学习要用到,不用奇怪,这些算法是基于贝叶斯理论,最流行的贝叶斯算法很简单,它通常用于文本分析。大多数生活垃圾邮件可以通过滤器可以使用贝叶斯算法,它们之间使用网络用户信息输入的类标记数据,去用来来比较新数据并对其进行选择适当分类。
聚类算法
机器学习要用到键聚类算法是找到它们和相应的分组之间的共同元件,聚类算法用于K均值聚类算法。在k-means中,分析研究人员进行选择簇数,以变量k表示,并根据学生物理安全距离将元素通过分组为适当的聚类。
基于实例的算法
机器学习要用到基于实例的分析使用提供数据的特定实例来预测结果。该算法的最有名的实例是基于K-近邻法,也叫KNN。KNN用于进行分类,比较数据点的距离,并将我们每个点分配可以给它一个最接近的组。
深度学习和神经网络算法
机器学习要用到基于生物神经网络的结构,人工神经网络算法,深学用神经网络模型,并对其进行更新。它们是大、且极其复杂的神经系统网络,使用以及少量的标记进行数据和更多的未标记信息数据。 这些被连接以形成一特定的周期,以模仿人脑的处理信息,并建立了逻辑连接模式。此外,随着网络算法的运行,隐藏层往往可以变得具有更小、更细微。
一旦你选择并运行了你的算法,还有非常具有重要的步骤:可视化和交流学习结果。 如果没有人能理解,如此惊人的洞察的用途是什么呢?所以更要了解机器学习。
 更多产品了解
更多产品了解
欢迎扫码加入云巴巴企业数字化交流服务群
产品交流、问题咨询、专业测评
都在这里!


热门数字化产品






1月16日,2025腾讯产业合作伙伴大会在三亚召开。云巴巴,荣膺“2024腾讯云卓越合作伙伴奖—星云奖”和“2024腾讯云AI产品突出贡献奖”双项大奖

腾讯TAPD作为国内领先的敏捷研发管理平台,可以说是最早拥抱MCP的研发管理工具之一,凭借其全生命周期的研发管理能力,成为AI代码助手的“最强外挂”,其创新功能直击开发痛点。

基于预设规则和对象特征,让消息推送更智能更精准,帮助企业打通内外部系统的数据系统,实现更多灵活、更个性化的营销和服务能力开发。

海纳嗨数凭借其专业的数据分析能力,为企业提供从数据采集到深度洞察的一站式解决方案,助力活动策划与执行实现质的飞跃。

网宿科技全站加速产品以弱网优化与源站灾备技术矩阵,构建全链路加速体系,通过核心技术为多场景提供端到端保障,实现弱网效率跃升、源站切换无感,助企业突破网络桎梏。