
大模型训练,绕不开的GPU服务器
来源: 云巴巴 2024-03-27 14:46:55
2017 年,Google 提出了 Transformer 架构,随后 BERT、GPT、T5等预训练模型不断涌现,并在各项任务中都不断刷新 SOTA 纪录。去年,清华提出了 GLM 模型,不同于上述预训练模型架构,它采用了一种自回归的空白填充方法,在 NLP 领域三种主要的任务(自然语言理解、无条件生成、有条件生成)上都取得了不错的结果。
 离不开的GPU服务器
离不开的GPU服务器
大模型,又称为预训练模型、基础模型等,是“大算力+强算法”结合的产物。随着大模型不断地迭代,大模型能够达到更强的通用性以及智能程度,从而使得AI能够更广泛地赋能各行业应用。
如何训练大而深的神经网络是一个挑战,需要大量的GPU内存和很长的训练时间。这是因为在大模型的训练过程中,算力、算法、网络和数据缺一不可。随着围绕AI大模型的全球军备竞赛打响,业界对算力的需求也更加旺盛。

大模型训练场景,要求底层服务器架构对网络协议、通信策略、AI框架、模型编译进行大量系统级优化。
GPU云服务器作为云服务器的一种,是基于GPU的快速、稳定、弹性的计算服务,主要应用于深度学习训练/推理、图形图像处理以及科学计算等场景。
基于GPU的应用于视频编解码、深度学习、科学计算等多种场景的快速、稳定、弹性的计算服务。GPU加速计算可以提供非凡的应用程序性能,能将应用程序计算密集部分的工作负载转移到 GPU,同时仍由CPU 运行其序代码。从用户的角度来看,应用程序的运行速度明显加快。
相比CPU是由专为顺序串行处理而优化的几个核心组成,GPU则拥有一个由数以千计得更小、更高效的核心(专为同时处理多重任务而设计)组成的大规模并行计算架构。
如何选择GPU服务器?
要知道当前很火的chatGPT这种人工智能的ai训练就可以通过GPU服务器来实现。
用户可以使用GPU云服务器作为简单深度学习训练系统,帮助完成基本的深度学习模型。
结合云服务器 CVM 提供的计算服务、对象存储 COS 提供的云存储服务、云数据库 MySQL 提供的在线数据库服务、云监控和大禹提供的安全监控服务,可搭建一个功能完备的深度学习离线训练系统,帮助高效、安全地完成各种离线训练任务。

选择GPU云服务器必须考虑五大原则
- 考虑业务应用先选择GPU型号、内存
- 考虑服务器的使用场景及数量(边缘/中心)
- 考虑客户自身的目标使用人群及IT运维能力
- 考虑服务器配套软件的价值以及服务的价值
- 考虑整体GPU集群系统的成熟度及工程效率
对比传统的自建GPU服务器,云端GPU服务器有什么优点?
1、高弹性
传统自建GPU服务器:机器配置固定,难以满足变化的需求
云端GPU服务器:可以灵活定制配置,一键按需提升更高性能和扩增容量
2、高性能
传统自建GPU服务器:用户手工容灾,依赖于硬件寿命。数据物理单点存在,数据安全不可控。
云端GPU服务器:单机峰值计算能力突破 125.6T Flops 单精度浮点运算,62.4T Flops 双精度浮点运算。数据安全有保障,异地灾备,数据快照。
3、易上手
传统自建GPU服务器:购买装机管理,自行实现硬件扩展、驱动安装。需跳板机登录,操作复杂。
云端GPU服务器:与云服务器 CVM、负载均衡 CLB 等多种云产品无缝接入,内网流量免费。和云服务器 CVM 采用一致的管理方式,无需跳板机登录,简单易用。有清晰的 GPU 驱动的安装、部署指引,免去高学习成本。
4、高安全
传统自建GPU服务器:不同用户共享资源,数据不隔离。需额外购买安全防护服务。
云端GPU服务器:不同用户间资源全面隔离,数据安全有保障。完善的安全组和网络 ACL 设置让您能控制进出实例和子网的网络入出站流量并进行安全过滤。与云安全无缝对接,享有云服务器同等的基础云安全基础防护和高防服务。
5、低成本
传统自建GPU服务器:高服务器投资运营成本。设备高功耗,需硬件改造适配。为保障服务稳定需高额的运维 IT 成本。
云端GPU服务器:提供包月购买方式,无需大量资金投资购置物理服务器。硬件跟随主流 GPU 更新步伐,免除硬件更新带来的置换烦恼。服务器运维成本低,无需预先采购、准备硬件资源,有效降低基础设施建设投入。
腾讯云GPU算力平台
通用计算发展后期将进入后摩尔定律时代,异构计算越来越受到关注。腾讯云GPU算力平台是用不同制程架构、不同指令集、不同功能的硬件组合起来解决问题的计算架构。它是性能、成本和功耗均衡的技术,如密集计算或外设管理等,从而达到性能和成本的最优化。
1、高性能计算平台 THPC,提供云上超强算力
腾讯量子实验室利用腾讯云黑石超算实例,共建弹性第一性原理计算平台。黑石超高算力与低延迟高速网络,为计算平台提供坚实的底层算力支撑与保障。
通过自研的弹性第一性原理计算平台服务,可为物理学和材料科学工作者提供强大的材料仿真、设计和筛选的科研能力,完成传统计算资源无法处理的超大体系的材料计算,高度匹配了科研工作者日益增长的高精度高效率算力需求。

便利的公有云弹性能力为合作项目快速交付资源,自动化初始应用环境,减少自建 HPC 的巨额投资和建设时间成本。为客户提供了安全、可靠、易用的超算平台。
2、AI加速引擎,提升训练和推理性能
TACO是基于腾讯云 IaaS 资源推出的自研 AI 加速引擎,为用户提供开箱即用的 AI 加速工具,用于分场景支持高性能分布式训练及推理。
支持主流深度学习框架,API兼容,即插即用,业务无感知;刷新了128卡V100训练ImageNet的业界记录;社区首个支持推荐特征动态增删的Embedding方案,TB级超大模型训练效率提升40%以上。
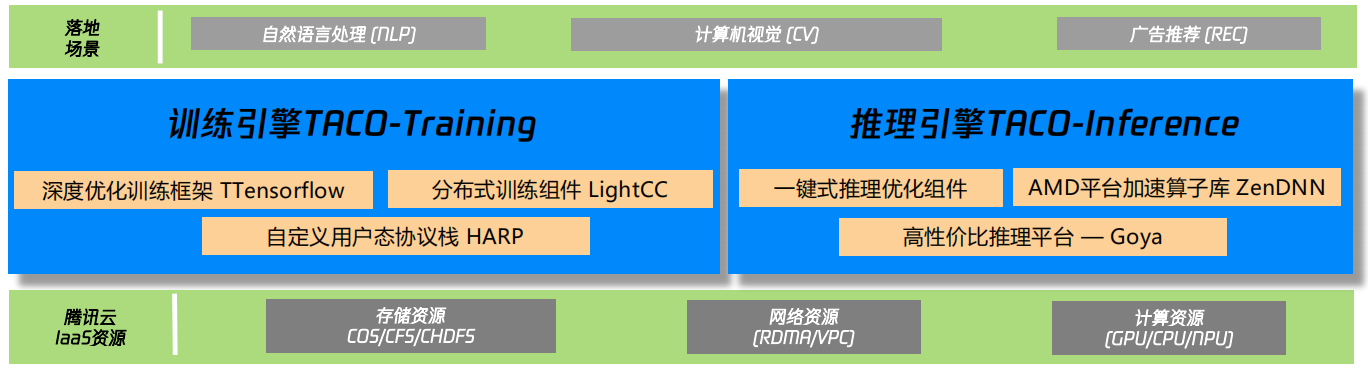
自定义网络协议栈,VPC环境下达到接近RDMA的分布式训练性能;AMD独家算子加速库,推荐模型性能提升6倍;Goya相比主流推理芯片,性能提升近3倍;注:以上性能数据基于企业内部测试得出,因环境不同将有所差异。
3、容器GPU共享技术,降低用户资源成本
QoS GPU (qGPU):基于nvidia docker实现多POD共享,依托TKE,兼容K8S;资源(显存/算力)灵活切分,构建简单;用户AI应用无需任何改动/重编,cuda库无需替换,部署无缝迁移;显存、算力可实现精准隔离;提升 GPU 的算力、显存利用率,推荐在线推理 + 离线训练场景。
云巴巴作为腾讯的重要合作伙伴,也一直在和腾讯GPU服务器携手共同为企业用户提供更多优质的产品与服务,如果您有任何感兴趣的产品,可以扫描下方二维码联系我们!
 更多产品了解
更多产品了解
欢迎扫码加入云巴巴企业数字化交流服务群
产品交流、问题咨询、专业测评
都在这里!

为你推荐


2021年腾讯云618云服务器特惠采购攻略
腾讯云618云服务器应该怎么买?在这个618特惠中云服务器怎么选更划算?盘点腾讯云618特惠云服务器和618代金券,上云攻略来了!2022-11-24 14:03:26

云服务器中的弹性伸缩功能,存储信息的新方式
云服务器的空间是我们选择购买一台云服务器时经常会考虑到的一个问题,如果云服务器中的空间不能满足我们日常使用则会导致云服务器中没有更多地方来对我们的信息进程存储,导致我们只有删除掉一些之前存储到云服务器中的数据之后才能继续使用。然而每一份数据对于用户而言都是2022-11-24 10:18:56

华为云的弹性云服务器的优势是什么
我们知道阿里云,腾讯云,金山云,有孚云都出了云服务器的相关产品,那么在这之中,在本文章,小编想谈论下华为云的弹性云服务器的优势是什么。 想知道华为云的弹性云服务器的优势是什么,就不得不提起华为云的弹性云服务器的产品优势了。其最为明显的优势之一,便是网络稳2022-11-22 16:30:55

本次腾讯云618,腾讯云轻量应用服务器最低仅需312元/年!
腾讯云618活动再次来袭!更有腾讯云618代金券等超多腾讯云618优惠活动,在腾讯云618主会场发现超值好物!2022-11-24 13:58:14

云服务器与轻量应用服务器有什么共同点和不同点?
他们都属于互联网上的服务器产品,都拥有部署互联网业务或者应用的能力,这也是目前人们会将他们混为一谈的主要原因,毕竟都可以部署网站、应用,或者存储数据,用户能够通过公网来进行访问。2022-11-23 15:31:53
严选云产品









领先的企业数字化服务平台
客服电话:400-0972-788


评论列表