
简单高效!快节奏时代,腾讯小样本数智人打造有温度“数智员工”
来源: 云巴巴 2024-03-27 10:31:15
品牌代言、公司宣传、产品介绍、直播带货......数智人扮演的角色正在不断增加。无论是替代真人服务、多模态AI助手、还是作为虚拟世界的第二分身,对于数智人而言都已经是触手可及的未来。
数智人作为企业的数字资产,是对员工工作的增强,可以进一步释放生产力,同时降本增效。未来数智人将根据不同行业的业务特点和应用场景进行更深度结合,孵化千行千面的数字员工,提供智能化服务。

 低成本实现高精度,是数智人产业化真谛
低成本实现高精度,是数智人产业化真谛
数智人的第一道技术门槛,就是生产制作。
制作数智人的流程,可以分为建模、驱动和渲染三个阶段,缺一不可。
建模,即搭出数智人的「基础骨架模型」,驱动则让模型「动起来像人」,渲染则负责让模型「看起来像人」。
从建模到驱动到渲染,再注入AI,让数智人真正的成为用户或行业可用的智能产品,每一个阶段都面临操作复杂、算法门槛高、开发周期长的问题,成本更是超大型企业才负担得起。而类似于银行、政务服务、直播间、景点导览等需求方,往往不具备独立开发制作人的技术能力,能承受的制作成本更是相当有限。

因此,数智人产业化发展的真谛,正是如何降低成本,实现简单高效。
对于腾讯来说,数智人不再是单一个体,他们还可以有不同职业身份和技能,并且可提供定制化角色服务。它们的背后,集成了多模态建模、语音识别、自然语言处理、知识图谱、视觉技术等综合AI能力。
2021年的腾讯数字生态大会上,腾讯首次公布了云智能的战略架构,整体面向管理者、生产者、开发者、用户四大人群,提供决策、协作、创新和服务四大核心能力。腾讯云智能通过AI与云的深度融合,大大降低AI开发和使用门槛,让客户实现高效开发、按需使用,从而满足客户在新型应用场景下,综合复杂、多层次的计算需求。
针对于低成本的开发,腾讯云小微推出的小样数智人产品,就适用于内容讲解、口播视频生产、直播带货等真人出镜场景,节约成本,全年无休。
小样本数智人
腾讯云小微小样本数智人即通过少量的小样本素材(3~5分钟),即可导入训练模型,生成与真人无异的数字人分身,五官、动作、表情完全模仿真人。
使用方式:仅需通过输入文本或音频,即可快速生成数智人分身视频,大幅节省每次拍摄的时间、空间、用人成本。
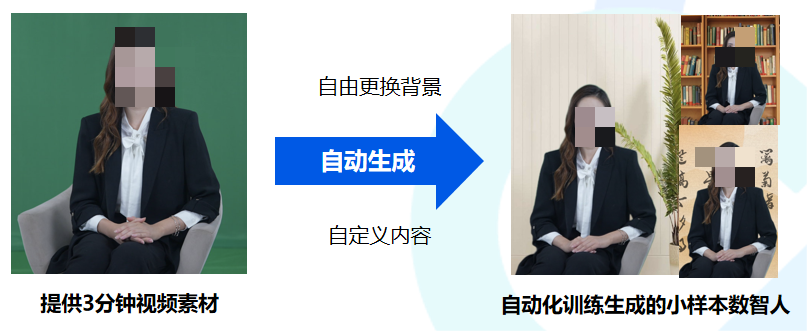
与精品形象相比,小样本数智人拍摄时间与训练时间都非常短,拍摄环境要求低,也只需要采光良好的安静环境即可,可支持文本驱动与声音驱动,提供50~100句声音素材就可以进行声音的复刻。
拍摄物料:
绿幕。(视频换背景效果顺序依次为绿幕、蓝幕、纯色幕、其它,且幕布的颜色和衣服桌子要有差异)。
拍摄设备。提词器、三脚架、摄像机或手机(拍摄)或pad(题词)。
其他设备。灯光器械、收音耳麦、场景道具、单位机、返送屏、泡沫板、监视器等。

拍摄环境:
环境
需要寻找一个安静尽量没有噪声和混响的录制环境。
光线尽量充足,灯光均匀,脸部无阴影。
根据景别调整相机和人之间位置。
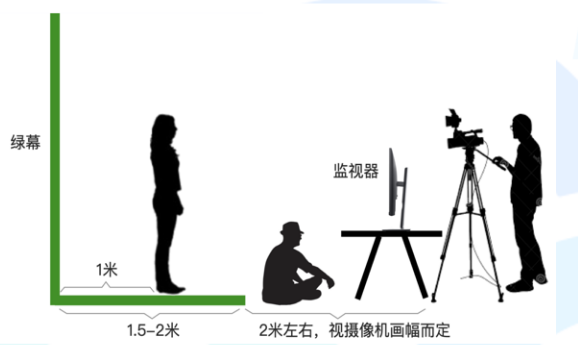
摄像机
摄像头要固定,无抖动。
帧率:25帧率或50帧率。
分辨率:1080P到4K,分辨率越高越好。
压缩码率crf=6;参考ffmpeg里面的参数。
录制过程:
方式一:一镜到底
拍摄整体相关
整个过程一录到底,相机不中断;不出现视频拼接的情况;
拍摄后的视频不做额外的压缩转码;
开始和结尾处人物进出摄像头的数据不保留,需要裁剪掉。
模特发型和服装
发型尽量简单,不要太多毛边或缝隙不利于抠图;脸部要全部露出;
服装颜色要和幕布颜色有差异和区分度;
不建议佩戴长款耳坠。脖子不要有遮挡。
模特动作相关
模特头要正对镜头,不要俯视或仰视;
动作自然,可加上自然的点头、微笑,眨眼,动作尽量可复用;
动作不要出框,不要挡住脸部;
不要有大幅的转头动作。
模特口型相关
朗读的文本可自行选择,可以朗读一段与实际业务场景相关的文本;
说话吐字清晰,嘴巴张开,口型不宜过小;
说话过程中不要吐舌头;
语速适中,不要过快或过慢。
方式二:分段拍摄
每段视频时长:每段在1分钟以上,几段视频加起来要5分钟或以上即可;(单段视频不能出现剪辑拼接的情况);
拍摄环境:每段视频的相机位置、曝光参数、背景、灯光、模特服饰、发型等要保持稳定;
模特位置:每段视频模特头部位置相对固定(参考点:所有视频人脸鼻尖位置不能超出第一段视频首帧头部区域);
拍摄结束:提交多段无压缩转码等处理的高清原视频。
云巴巴作为腾讯云小微的重要合作伙伴,也一直在和腾讯携手共同为企业用户提供更多优质的产品与服务,如果您对小样本数智人的使用更感兴趣,可以扫描下方二维码联系我们!
 更多产品了解
更多产品了解
欢迎扫码加入云巴巴企业数字化交流服务群
产品交流、问题咨询、专业测评
都在这里!

为你推荐


如何去实现人工智能与云深度融合
企业管理软件系列统称归类为某一特定行业或方法,在神奇象限,腾讯是国内唯一的人工智能提供商。或技术栈中的一个特定的服务提供商的完美结合彰显实力。2022-11-21 15:59:09

云巴巴案例秀 ‖ 纺织原料行业变身数字工厂,博致云让数据驱动创造
围绕车间的人、机、料、法、环管理,博致云从原料入厂、生产计划、生产执行、成品产出、成品入库、成品出厂等有效关联,在实现车间作业透明化、规范化基础上,实现产品的可追溯性、生产资源计划协同与优化,持续提升生产效率。2024-03-27 09:52:58

眼神科技生物识别技术银行综合布控优势
为什么眼神科技生物识别技术的投入高度重视银行方面的综合布控?在当前错综复杂的国际形势及新兴产业时代大背景下,作为金融机构重要组成部分的银行,在安全保卫方面的工作落实,在一定程度上影响着国家及社会的稳定性。2022-11-23 16:44:17

虹膜识别技术,安全不仅在我们的心中也在我们的眼中
虹膜识别技术的出现让我们在利用生物识别的方式进行身份认证的同时有了一个新的选择,作为生物识别技术中较为安全的一种身份认证方式,虹膜识别从出现在我们生活中的那一刻起便和“安全”二字有了紧密的联系。而且利用生物识别技术进行身份认证核验的同时因为是用我们的身体器2022-11-23 17:08:50

第三代人工智能发展的趋势,常识往往不在数据里
近日,AI2000人工智能全球2000位最具影响力学者榜单在清华大学发布,中国学者规模位列世界第二,但高水平学者集中的研究机构匮乏,人工智能领域的人才队伍亟待加强。 AI2000榜单由清华-中国工程院知识智能联合研究中心和清华大学人工智能研究院发布。2020-03-16 15:43:01
严选云产品









领先的企业数字化服务平台
客服电话:400-0972-788


评论列表