






 首页
首页2020年,大数据时代怎么抓住机遇并与之对抗
大数据是收集,组织,处理和收集大型企业数据集洞察所需的非传统安全策略和技术的总称。虽然可以处理超过计算机的计算思维能力或存储的数据的问题研究并不新鲜,但近年来通过这种不同类型的计算的普遍性,规模和价值体系已经大大扩展。
2010年,《经济学人》发表了一篇长达14页的关于大数据应用的前瞻性研究。被称为“大数据时代的先知””维克托·迈尔·舍恩伯格,指出大数据带来的信息风暴正在改变我们的生活,工作和思维。并将迎来一次思想变革,商业变革和管理变革的时代转型, 作为一名材料研究者,如何在大数据时代抓住机遇,迎接挑战?? 也许我们可以在新兴,迅速发展的材料信息学中找到答案。
01
数据标准
统一的数据标准是数据库之间数据共享的基础,国际标准化组织(IS O)制定了一系列“产品模型数据交互规范”(STEP,产品模型数据交换标准。ISO10303)标准来描述整个产品生命周期的产品信息,旨在实现产品数据交换和共享, 美国国家标准和技术研究院(NIST)基于XML开发的MatML是专门为材料数据信息管理和交换的可扩展标识语言。
02
材料信息数据库
材料信息包括:分类(大、小类)、结构(晶体结构、化学成分、相图、相结构),外观(形状、尺寸、光泽、颜色)。性能(物理、力学和使用性能),加工(制备方法、加工工艺),使用(使用条件、变形、断裂、失效和破坏形式),文献(图书、期刊、专利、论文等),行业(专家、设备、产品、机构)和实验信息(实验模型、测试信息、实验装置、
结果)。
根据信息内容可分为材料基本性能数据和材料信息数,;其中,材料基本性能数据主要包括材料的力学性能。晶体结构,热力学动态数据和物理性质,为材料设计提供基础数据。材料信息数据库利用先进的信息技术,从文献,互联网等多种渠道提取和管理材料数据。包括材料生产工艺数据,性能数据和服务性能等。
Granta开发的CMS和ASM开发的Mat.DB是离散数值型数据库,随着Web技术的发展。美国的MatWeb和日本的MatNavi都是著名的在线材料数据库。
MatWeb拥有一个超过115000种材料的性能进行数据,涵盖金属,塑料,陶瓷和化合物,数据分析主要问题源自制造商企业产品检验。其余来源于网络数据技术手册或专业协会,还具备ANSYS,Solid Works等CAD / CAM软件的数据可以输出的功能。MatNavi由日本国立材料科学发展研究院(NIMS) 组建,拥有9个基础工作性能研究数据库( 计算相图,计算得到电子产业结构。中子嬗变,扩散数据库等) 5个结构设计材料作为数据库( 蠕变、疲劳、腐蚀等) 。4个工程实际应用数据库( 金属材料、CCT曲线,材料市场风险信息服务平台) 和5个数据生态应用系统。目前我国已经有超过149个国家的11万用户需要注册资金使用。
目前,我国系统的在线数据库是以北京科技大学,汇集了全国30多个科研单位的数据。整合了60多万条各类材料科学数据。
随着信息技术的发展,新的材料信息数据库将涵盖基本的材料性能数据库,并整合工艺数据,文献专利,各国标准。专业图书和行业信息统一管理,利用数据挖掘技术对材料数据库中的大量数据进行分析和预测。快速发现新的知识和规律,是未来数据驱动材料研发的主要研究领域。
03
集成材料设计平台
材料进行集成设计一个平台是以MGI为指导,集成材料数据库,高通量材料计算,材料数据管理和分析系统为一体的现代材料研发设计平台。
目前正在建设的材料一体化设计平台有美国的Automatic Flow(AFLOW)和中国科学院计算机网络信息中心组建的Mat-cloud。

04
材料和数据挖掘技术的应用内容
(1)材料数据可视化
可视化是将数据和信息技术通过我们一定的方法转化为大脑易于分析和理解的视觉表现形式,基于材料以及数据的可视化信息的构建企业可以发展助力研究工作人员从从不同视觉维度进行分析和解释材料性能和材料结构之间的关系。
2)材料数据挖掘
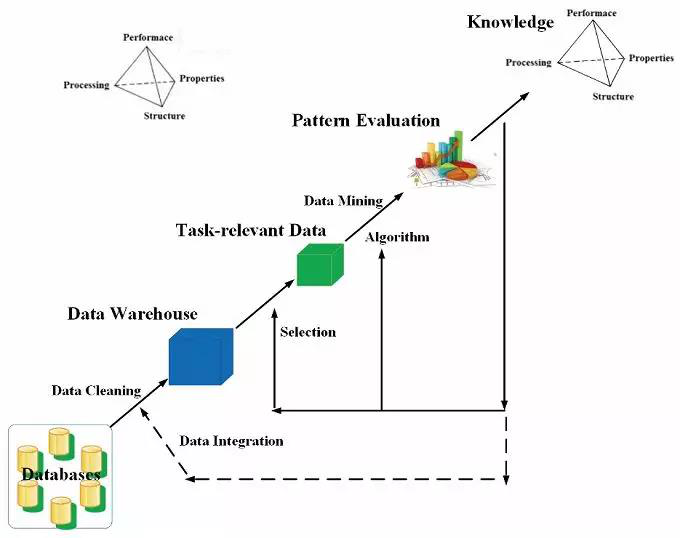
数据挖掘(Knowledge-Discovery in Databases,KDD)是利用特定算法搜索大数据集并从数据库中提取知识的过程, 该过程主要包括数据输入,数据预处理(数据汇合、数据清洗、特征选择等)。 数据挖掘和后处理(模式过滤、可视化等 ),并最终获得有用的信息(知识)。
传统的数据挖掘技术主要是线性和非线性分析,回归分析,因素分析,聚类分析。数据挖掘,随着数据挖掘技术的飞速发展,决策树理论(Decision Trees),人工神经网络(Artificial Neural Network,ANN)等新的技术不断应用于材料研究中。
决策树是通过概率论的直观运用建立的树形结构,其中我们每个公司内部控制节点代表一个属性上的测试。每个分支代表作为一中类型,每个叶节点代表一种类别。决策树是分类模型的非参数方法,不需要昂贵的计。,非常容易理解。
人工神经网络(ANN)是模拟生物神经系统, 每个节点表示特定的输出函数,即激励函数(激活函数)。每两个节点间的连接代表一个对于通过该连接信号的加权值(权重)。,人工神经网络(ANN)的特点是,可以用来接近任何目标函数。但需要选择合适的拓扑来防止模型的过度拟合,可以处理冗余特征,冗余权值很小;对训练数集的噪声非常敏感。当隐藏节点数大时,ANN的训练相当耗时,但测试分类非常快。
数据挖掘方法以数据输入并分析预测产生模型输出,可以利用其对材料大数据分析建模发现潜在的组织性能影响规律。特别是在分析建模的晶体结构的研究,由于该离散非连续的的晶体结构。因此,使用的数据挖掘方法来分析和预测会很方便。
05
原子分辨成像的未来机遇
近年来,R. Melko、Carrasquila等人在理论领域已经证明了物体提取的可行性。同时,机器学习技术在相变检测等方面取得了巨大的突,。例如,人工神经网络已成功应用于2D Ising、Potts模型、3D Hubbard Fermi模型,晶格规范理论和Chern绝缘体等经典和量子系统中的相位和相变检测。在不明确标记和配置的情况下,使用成像数据作为输入,通过混淆学习进行故意错误标记数据来“学习”相变,这种方法已证明了Kitaev链中的拓扑相变和经典Ising模型中的热相变。同时扩展到使用一对判别合作网络从完全未标记的数据中检测相变,例如超流体等多体相的相变。
我们发现,综合利用数据挖掘和机器学习可以从介观和原子解析的定量测量数据中提取出物理信息,但同时也存在一些问题。例如,STEM实际上限于3D原子序列的2D投影,而这可能影响的机器学习方法的适用性;用于扫描探针显微镜。亚表面层对表面原子行为的影响是不确定的,对于分层材料,虽然通常所有原子单元都是可见的。但有一些数据点也可能丢失,并且来自局部倾斜的信息可能也会丢失。
对于一些宏观有序参数的未知,受强相互作用的缺陷所约束,或存在分层排序,竞争基态和相关无序等情。人们仍必须通过进一步研究学习是否能提供必要的工具来提取相关的物理信息。
在大数据时代,抓住机遇并且应对的方法就是如此。
 更多产品了解
更多产品了解
欢迎扫码加入云巴巴企业数字化交流服务群
产品交流、问题咨询、专业测评
都在这里!


热门数字化产品






1月16日,2025腾讯产业合作伙伴大会在三亚召开。云巴巴,荣膺“2024腾讯云卓越合作伙伴奖—星云奖”和“2024腾讯云AI产品突出贡献奖”双项大奖

腾讯TAPD作为国内领先的敏捷研发管理平台,可以说是最早拥抱MCP的研发管理工具之一,凭借其全生命周期的研发管理能力,成为AI代码助手的“最强外挂”,其创新功能直击开发痛点。

基于预设规则和对象特征,让消息推送更智能更精准,帮助企业打通内外部系统的数据系统,实现更多灵活、更个性化的营销和服务能力开发。

海纳嗨数凭借其专业的数据分析能力,为企业提供从数据采集到深度洞察的一站式解决方案,助力活动策划与执行实现质的飞跃。

网宿科技全站加速产品以弱网优化与源站灾备技术矩阵,构建全链路加速体系,通过核心技术为多场景提供端到端保障,实现弱网效率跃升、源站切换无感,助企业突破网络桎梏。