







天云融创软件SkyForm任务调度系统
 首页
首页 产品概述
产品概述 北京天云融创软件技术有限公司(简称天云)是一家专注于云计算、高性能计算和智能计算领域的创新型科技企业。公司一直秉承自主研发的理念,为客户提供优质的平台化软件开发、完善的一体化解决方案以及高质量的运维服务,帮助客户突破算力瓶颈,解决繁杂的云服务管理困扰。
SkyForm任务调度系统(简称SkyForm AIP)是由天云融创软件自发研制的高性能、高可、高可扩的人工智能、高性能计算、大数据应用管理平台,具有自主可控知识产权,核心技术不依赖于国外开源社区,拥有多项发明专利,产品成熟,适配所有常用国产化硬件和操作系统,已经广泛用于规模生产环境。
SkyForm AIP 是为人工智能框架、高性能计算、大数据等应用专门设计的企业级资源和任务调度和用户访问系统,注重大规模集群高性能计算、分布式深度学习、机器学习、数据分析等任务管理,使用户在使用大集群和异构硬件的时候达到像用本地系统一样的简单和透明,同时又让系统管理员能够有效地监控和管理集群上所有的资源,使昂贵资源的利用率最大化,从而提高效能、降低成本。
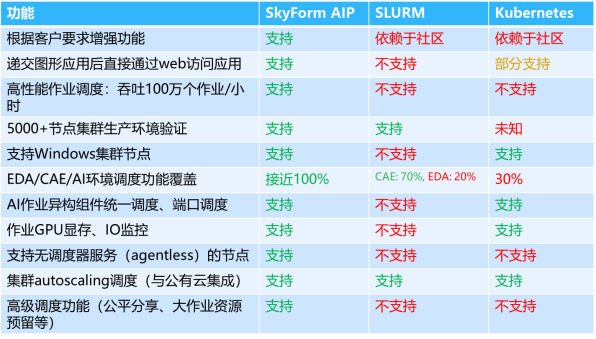
技术优势SkyForm AIP 与市场上常见的应用任务管理云平台比较对应用环境的支持有以下明显的优势和先进性。
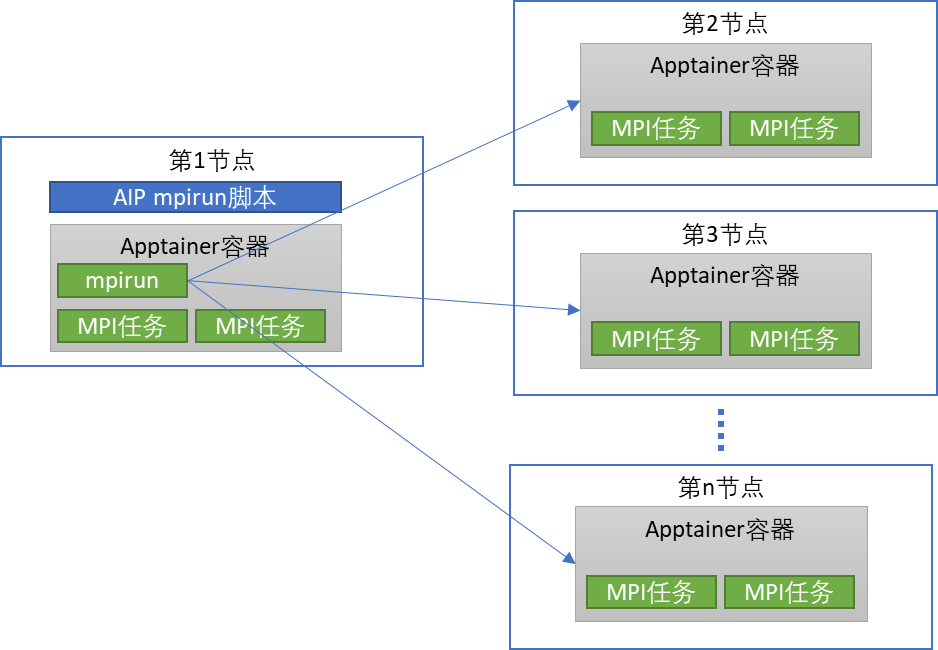
功能特色内建负载监控系统,每5秒采集一次所有集群上的负载信息(CPU指标、内存、存储 I/O、网络 I/O、GPU各项指标以及作业进程对GPU的使用等),支持监控数据存放于 Elasticsearch 或Prometheus 数据库中。
可以按需定制支持特殊类型的 CPU、GPU、FPGA、xPU 等硬件异构加速器的接口适配和资源话度。
默认情况下,禁止普通用户登录到计算节点;当计算节点承载运行普通用户的计算作业时,允许对应的用户账号ssh登录到相关的计算节点。允许专属队列的普通用户登录到专属队列对应的计算节点。
2、关键技术其它的资源调度器对多种任务的资源每次调度一种,当一种任务所需资源不足时其它作业占着资源等待,造成资源浪费。SkyForm AIP 把整个学习框架作为单一作业,直到所有任务所需资源都满足时才启动,以保证昂贵资源利用的最大化。多任务异构资源的统一调度是 SkyForm AIP 的独特调度能力,保障应用性能和资源利用最大化。
·伸缩资源主动分配
应用(作业)在一开始可以告诉调度器所需最小和最大资源的值,调度器会根据调度策略和可用资源尽量满足应用的需求。如果不能满足最大资源需求,在应用运行的过程中若有冗余资源可用,调度器会主动把这些资源分配给作业直到作业所需最大资源得到满足。这种主动分配的调度有益于提高像深度学习一类资源饥渴型应用的性能。这种调度算法也是其它资源管理软件缺乏的。
a)先进先出:根据作业递交的先后时间顺序分发作业。
b)优先级:作业根据优先级递交到不同优先级的队列中,调度系统先分发优先级高的队列中的作业,当高优先级队列中没有等待作业时,才分发下一个优先级队列中的作业。
c)轮循:当同一队列中有多个用户的作业时,调度系统为每个用户分发一个作业等队列中所有的用户的第一个作业分发后,再分发每个用户的第二个作业,每个用户的第三个作业,等等。
d)独占:用户递交作业时可指定为独占作业。独占作业是指每个主机上只能运行这一指定的作业。若有一个独占作业分发到一台主机上,主机将不接受其它普通作业。若主机上已有其他普通作业,则独占作业不会分发到该主机上。独占作业一般用于需占用大量资源的作业,以防与其他作业在同一主机上发生冲突
e)公平分享:当一个集群由多个部门和多个共享的时候。可定义各个部门、用户组、和个用户的使用份额,如下图所示部门、组和用户间的关系,数字表示相邻同级单位间的相对份额(数字大小没有实际意义,相邻单位间的数值比值决定其份额,如10:20 和 1:2 有同样的效果。下图中部门 1分配 213 的集群资源。部门2分配113)。调度系统根据这样的配置来决定作业的优先级以保证各单位间的资源分配份织。

f)抢占:高优先级作业通过抢占 CPU 核、GPU 以及其他资源使低优先级作业暂停(释放 CPU)或重调度(释放 GPU 等其他资源)的方式提前运行。高优先级作业运行结束后,低优先级作业继续或重运行。
g)并行作业资源自动预留:在繁忙的集群系统中,往往空出来的资源比较小。小作业就容易拿到资源而先走,这样即使大作业优先级高,也会因没有大块资源空出而长期等待。调度系统可以配置使高优先级并行作业自动将空出的小块资源保留一段时间不被小作业所占,等保留的资源足够时运行。
h)基于资源阀值的调度:由于作业所用资源难以实现预估,为防止资源不足,尤其是内存不足导致作业失败,可以定义资源的闹值来控制作业调度。对每一个资源可以定义两个闹值(上下水位),第一个下水位用于停止调度,第二个上水位用户停止(杀掉或挂起)已在运行的作业。资源阅值可设在主机层或/和队列层。
i)资源平衡方式:资源平衡可以有两种方式:减少资源碎片(Packing)或负载平衡(Spreading)。减少资源碎片将作业尽量往最少的主机上调度,以便留下大块资源给大作业用。负载平衡是将作业尽量分布开,以保证作业运行性能和降低主机功耗。
j)异构系统:允许将不同架构的主机、不同型号和性能的主机、不同操作系统和版本的主机放到一个集群里,通过“host type”参数进行配置。每种不同种类的主机可以定义一个CPU 的性能值。在递交作业时可以指定这些参数配合使用。
k)定时作业作业:定时作业与普通作业一样可由所有调度策略调度和作业定义(如环境变量、资源需求等)。
在作业定义中可指定运行用户名、运行时间点、作业命令行、作业最长运行时间(若超出此时间限制。作业会被自动杀掉)、启动超时(若由于在规定的时间里资源不足作业无法启动,最长等待的时间)、覆盖(下一个作业启动时上一个作业未完成是继续运行还是杀掉以前的作业)、失败重新运行最多次数等参数。
l)优先级抢占:高优先级作业可以暂停低优先级作业获得作业资源(CPU 核GPU、或其它资源)。高优先作业运行结束后,低优先级作业可以自动恢复。
用户的作业递交到队列中,系统可以设多个队列,每个队列一般可与业务挂钩合理分配资源,避免作业冲突。队列可设置以下参数:
a)指定用户:只有指定的用户或用户组可以使用此对列。
b)总作业槽限制:对业务可用资源的限制。
c)每个用户总作业槽限制:每个用户做多可用的作业数。
d)主机或主机偏爱:可以限制队列可用的主机或主机组名,也可在分发作业时优先考虑一些主机。
e)作业预处理/后处理:定制的作业前后处理程序,以便为作业运行做准备,检查作业运行必备条件,和在作业完成后做清理工作。
f)作业操作定制(暂停、恢复、结束):对作业的操作在队列层做统一的定制化。如暂停作业默认的操作是暂停作业所有进程,可以定制成暂停作业时叫作业杀掉,然后重新放入队列中。
h)作业资源限制,可以根据主机、项目、用户的任意组合指定作业的限制。
i)CPU 绑定:将作业绑定到 CPU 的核以优化运行性能。
j)GPU 使用检测:若作业使用未经分配的 GPU,使用GPU的进程将会被强行终止。
k)允许1禁止交互作业:交互作业可以让用户在终端上看到应用的屏幕输出,队列可以根据需要允许或禁止用户递交交互作业。
l)作业自动运行:当作业运行的主机故障时,系统会自动在其它符合条件的主机上自动重启作业。
m)作业运行时间窗:有些业务只需要在一定的时间窗里运行,如regression 优先级低。一般可利用晚间和周末的时间运行,则可定义晚间和周末运行的时间窗。
多个团队把各自的主机放到一个池子里共享,但需要保证自己的池子里的机器自己有优先级。即自己不用是可以给别人用,自己需要时随时可以用(抢占别人使用自己池子里的资源)。

如上图所示,组1和组2都有自己拥有的资源池,中间有共享的资源池,
b)每个组里的资源池中若自己组的人不用,可共享给其他组的人用。
c)自己组里的任务在自己的资源池中可以抢占其他组里任务的资源,抢占只限于自己的组的资源池中。
这种场景叫做“拥有抢占”,目前已知的调度器只有优先级抢占,大多数无法实现同优先级下两个组在自己的资源池中抢占他人借用的资源,AIP 提供此调度功能和调度策略。
2.2 资源和任务监控a)主机系统负载和状态
b)通过资源传感器 RESS 监控的特殊资源
c)作业1任务状态
监控数据载入 Elasticsearch 或 Prometheus 数据库里,可以通过像 Kibana、Grafana这类标准图形监控分析软件产生图标和进行数据分析。
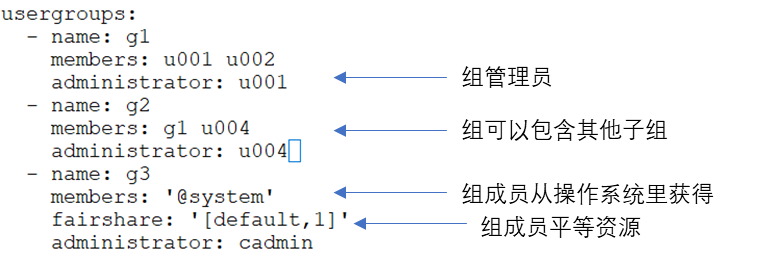
2.3 用户权限管理SkyFom AIP 使用操作系统中的用户管理系统(LDAP,AD,NIS 等),自动同步用户信息和用户组信息,使用换作系统里的用户名和密码对用户进行认证。每个用户组可以指定一个组管理员,组管理员可以访问组内用户的任务。
SkyFom AIP 用户组定义的例子:
2.4 多集群和混合云资源调度SkyFom AIP 支持将多套高性能计算集群连接起来,通过单一入口实现统一管理和调度,有效整合资源,简化资源使用方式,提升高性能计算集群的利用率。
运行 SkyForm AIP 调度系统的某一套计算集群作为主集群系统(Master Cluster),其主要功能包括:获取所有计算集群的状态和资源使用情况,获取所有计算集群的作业以及运行状态,调度和分发作业到特定的计算集群,代理用户访问特定资源等。
高性能计算集群既包括已有的或新建的传统计算集群系统,也包括基于公有云资源组建的远端计算集群系统。不同的从集群系统(Slave Cluster)所采用的负载调度系统可以各有不同,包括 AIP、LSF、PBS、SLURM 调度系统等。各计算集群加入多集群管理系统后,接受 AIP 主集群系统(Master Cluster)的管理,就可以作为多集群系统的一部分运行。主集群系统会根据客户端提交的作业请求,将计算任务转发给指定的从集群系统。同时各计算集群的负载情况以及作业运行状态的信息也会周期性的传送到主集群系统。加入多集群系统并接受主集群系统管理的各计算集群,集群已有的功能不受影响,即集群原来提供的功能可以并行继续使用。
主集群系统(Master Cluster)为用户提供统一的访问入口,资源申请方式和使用流程与单套主集群系统完全相同。系统支持多种计算任务/作业提交方式,支持基于B/S WEB 界面提供计算服务,支持通过 Shell 命令行/脚本方式提交计算任务。并可以根据用户使用习惯,进行灵活定制。
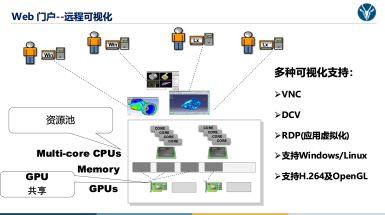
2.5 交互式图形任务做为 SkyForm 任务调度系统的图形任务管理模块。SKyForm CRV 云远视提供了
一个面向交互式图形任务的话度和管理框架。远程交互式图形任务支持多种 2D或 3D 远程可视化技术,包括VNC,NiceDCV,微软RDP/RemoteFX等。SkyForm AIP 任务调度系统根据实际用户需求或业务需要。调度、启动、监控和管理交互式图形任务。SkyFom CRV云远视模块将可视化任务的连接信息和视频流,通过WEB 界面方式进行展现,或转发给相应的用户客户端。

如果打开的应用在服务节点/计算节点上以Web 网页方式提供服务,SKyForm CRV 云远视框架(模块)亦可对此类应用集成,例如JupyterLab,TensorBoard RStudio 等等。调度系统将自动分配Web服务的网络端口,启动对应的后台服务SKyForm CRV 云远视将Web 页面 URL 推送给最终用户,用户打开应用的效果就是以浏览器直接访问应用提供的Web URL。
SKyFomm CRV远程可视化框架使用 GPU 资源的技术主要有三种:
·GPU 透传:通过设备透传的方式,虚拟机的用户可以独享一个显卡,无法6实现显卡共享
·GPU 共享:通过物理机多个应用直接访问 GPU,显卡灵活共享
·GPU:通过虚拟 GPU 技术,实现显卡 1:2,1:4,1:8 等固定模式共享
2.6 网络代理服务SkyFom 任务调度系统 TCP/IP 网络代理服务针是4层网络通讯的转发和代理;7层网络(如 http)转发可以通过 Nginx来支持代理,不在 AIP 服务代理范围内。
通过 TCP/IP 代理服务。用户客户端可以访问集群系统内部的没有直通外网的计算节点上的图形交互式任务,或者命令行交互式任务。
2.7 命令和 API接口SkyForm 任务调度系统提供C/C++、Python、CLI(易读和JSON)、REST 开发接口,提供业界常用话度器 PBS、LSF、SLURM兼容的命令行接口。
Python SDK是SkyForm任务调度系统提供的PythonSDK,提供了更易用的HighLevel API,支持机罪学习工程师简单地使用 Python在 AIP 完成模型训练和部署,串联机罪学习的流程。
Python SDK提供以下功能:
·支持多种主流机器学习训练框架
·标准化模型服务定义,模型转化为生产就绪服务非常简单
·强大的资源管理能力,让用户在无需关注物理资源的情况下托管训练任务应用服务
·高效的模型开发能力,提供模型仓库集装式版本管理,各类模型可以按版本6快速部署
·可视化训练管理,支持实时训练日志以及 GPU等资源实时监控
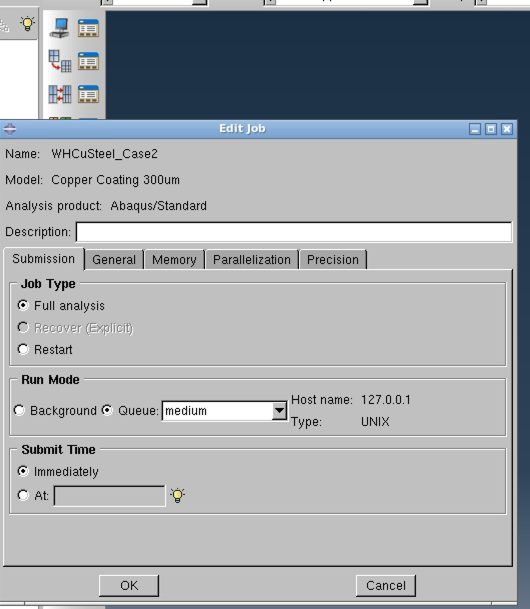
3.典型应用场景SKyForm AIP 与 CAE 仿真软件和 EDA仿真软件的集,成有三种方式:
·通过SkyForm AIP 门户或者AppSpace 应用平台的WEB服务界面,可以填写应用参数后直接递交 CAE/EDA仿真应用作业。SkyForm AIP的门户里已有的作业递交页面包括:ANSYS、FLUENT、ABAQUS、NASTRAN、LS-DYNA、 STAR-CCM+ 、OpiStmd、SIMPACK、JupyterLab等等。
·用户在厂商的图形应用里(如ANSYS WorkBench、Ansys HFSS、FLUENT Launcher等)里直接递交仿真作业。由于SkyForm AIP提供与LSF兼容的部分命令,用户选择LSF作为后台任务管理,即可将作业直接递交给 SkyFom AIP。
·通过命令行递交作业,或在有集成的应用命令行里直接话用AIP命令递交作业如 Synopsys Siliconsmar (通过Synposys CDPL)。

3.2 集成深度学习框架TensorFlow
TensorFlow是 Google 开源的机器学习和深度神经网络库,执行和伸缩性好。灵活的架构能够运行在个人电脑,服务器集群和移动设备上的单个或多个CPU,GPU 或TPU上。TensorFlow社区活跃开放,追随者众多,是GitHub关注度最高的深度学习项目。TensorFlow 能够支持广泛的应用,比如 Google搜索,Android 应用商店推荐,语音处理,图像识别,机器翻译,视频目标检测,增强学习等。TensorFlow开发了可视化工具TensorBoard,既可以显示神经网络结构,又可以显示训练和测试过程中各层参数的变化情况,用于更好地理解,调试和优化网络。
TensorFlow 还开发了机器学习模型 serving的高性能开源库,可以将训练好的模型快速部署服务上线,并支持模型热更新和自动模型版本管理。TensorFlow 的不足之处主要有速度比其他框架慢,内存资源占用多,静态图框架调试困难,版本更新快、兼容性问题多,很多的接口更新或者丢弃等
Caffe
Caffe是一款出现时间较早十分知名的深度学习框架,由伯克利 AI 研究所和社区贡献者开发。Caffe 的使用比较简单,无需编写代码即可进行模型训练,运行速度快同时还有十分成熟的社区。Caffe维护了一个Model Zoo,许多论文作者会将最前沿的模型发布到这里,模型与相应优化都是以文本形式而非代码形式给出,其他用户可以轻松稳定复现前沿模型。Caffe广泛应用于机器视觉,但不适用于文本,声音和时间序列数据等其他类型的深度学习应用。Caffe 原生支持 CPU/GPU 的单机和分布式模式不支持多机分布式模式,依赖第三方开发的版本(比如英特尔开发的基于MPI的多机版本)。Caffe的不足之处还包括更新放缓,框架设计带来的灵活性缺失和扩展困难不提供商业支持等。
PyTorch
PyTorch是 Facebook开源的深度学习框架,能够在强大的 GPU 加速基础上实现张量和动态神经网络。PyTorch 与机器学习第一大语言 Python深度结合,平滑地与Python数据科学堆栈结合,接口易于使用。PyTorch不需要预定义神经网络图,而是提供了一个框架,可以自由地定义和更改神经网络的结构,甚至在运行时动态修正模型结构而不影响其他计算,降低了调试的难度。PyTorch易于构建新颖甚至复杂的神经网络,支持动态图的灵活性非常适合学术研究开发新模型。PyTorch 支持多机分布式模式,但是没有采用TensorFlow和MXNet的PS-Worker模式,依赖于TCP 或MPI或Facebook孵化项目 gloo,只有gloo支持GPU。PyTorch的不足之处主要有框架比较新,2017 年1月才开源,现在最新版本发布为0.4.1,使用者较少,强大的社区有待形成。
MXNet
MXNet是灵活且高效的深度学习库,Apache 孵化器项目,中立,完全靠社区推动,也被 Amazon选为AWS 主要支持的深度学习平台。MXNet 平台特性与TensorFlow 最相近,有完整的多语言前端,应用场景从分布式训练到移动端部署都覆盖,整个系统全部模块化,适合快速开发,同时又具有轻量级,速度快,内存占用小的优势。MXNet的不足之处主要有缺乏完善高质量的文档,版本更新快、兼容性问题,社区规模较小且松散(主要开发者背景不同,由“民间”开发维护),缺乏商业应用等。
3.3 集成机器学习开发环境Jupyter Lab
JupyterLab 是数据科学/机器学习社区内一款非常流行的开源 web 编辑器,适用于Python 程序的开发, 调试及运行。
它提供了一个环境,用户无需离开这个环境,就可以在其中编写代码、运行代码、查看输出、可视化数据并查看结果。因此,这是一款可执行端到端的数据科学工作流程的便捷工具,其中包括数据清理、统计建模、构建和训练机器学习模型、可视化数据等等。
以下常用的 python 算法库可以通过 Jutyper notebooks 来调用和运行:
Scikit-learn(通用算法库)
Scikit-learn 是开源的 Python机器学习库,是一个完整的机器学习流程框架,提供了大量用于数据挖掘和分析的工具,包括数据预处理、交叉验证、算法与可视化算法等一系列接口。Scikit-learn的基本功能主要被分为六个部分:分类,回归,聚类,数据降维,模型选择和数据预处理。Scikit-learn定位于通用传统机器学习库,几乎覆盖了机器学习所有的主流算法,有很多高质量模型易于复用,但相对保守,只做机器学习领域的扩展,只采用经过广泛验证的经典算法。Scikit-learn 倾向于使用者自行对数据处理,而以TensorFlow 为代表的深度学习库会自动从数据中抽取有效特征。Scikit-learn 的模块高度抽象化,例如一个分类算法可以用几行代码完成,这种抽象化限制了使用者的自由度,但是大大降低了机器学习的使用门槛。Scikit-learn 主要适合中小型的实用机器学习项目,数据量不大且需要使用者手动对数据进行处理,这类项目通常只需单机环境,在 CPU 上就可以完成,对硬件要求低。
Keras
Keras 是用Python编写的高级神经网络API,能够以TensorFlow,CNTK,或者Theano作为后端运行,可以说是站在巨人肩膀上的设计。Keras 把用户体验放在首位,提供一致且简单的API,易学好懂,可以实现简单而快速的模型设计,用户友好,高度模块化,易扩展,同时支持卷积神经网络和循环神经网络,可以在CPU和GPU上无缝运行。Keras 由 Google软件工程师开发,作为高层神经网络 API而不是单独的深度学习框架,Keras 发展迅速,有可能成为用于开发神经网络的标准PythonAPI。Keras 的不足之处主要有速度慢,作为中间层比单独使用TensorFlow,CNTK或者Theano 要慢;为了扩展性好,大多数用Python 实现,在性能和内存管理方面缺乏效率。
MLlib(分布式算法库)
MLlib 是 Spark对常用机器学习算法的开源分布式实现库,目标是使实用的机器学习算法可扩展并容易使用。Spark是一个专门针对大量数据处理的通用的快速引擎其基于内存的计算模型天生擅长机器学习算法的选代计算,所以Spark是在大数据训练样本下的分布式机器学习理想平台,适用于工程化的实践项目。MLib 是Spark 的可以扩展的机器学习库,包括分类,回归,聚类,协同过滤,降维和关联分析等算法MLib 提供多种语言支持(Python,R,Scala,Java),对于处理大规模数据速度快。但是 MLib 每个类别的算法不够丰富,实现的都是些基本算法,如果要把基本算
法改进为想要的模式,学习门槛高,需要花费大量时间和精力。机器学习算法的单机和并行化版本的实现是完全不同的,Scikit-learn的单机算法并不能简单的移植到Spark MLlib.
RapidMiner Studio
RapidMiner Studio 是一款世界领先的数据挖掘图形化工具,免费提供数据挖掘技术和库。在一个非常大的程度上有着先进技术,特点是图形用户界面的互动原型。
RapidMiner Studio 是可以进行机器学习、数据挖掘、文本挖掘、预测性分析和商业分析的、具有拖拽功能的图形化工具。可以让分析师可以轻松地设计从混合到建模到部署的预测性分析流程,也可以让企业机构通过使用预测性分析来优化业务,从而获取竞争优势。提供了企业所需的高级分析功能,它可以用于提高市场回应率、降低客户流失、检测机械故障、计划预测性维护以及检测错误等。
3.4 集成大数据处理框架Spark
Spark 是一种快速、通用、可扩展的大数据处理引擎,继承了MapReduce 分布式计算的优点并改进了 MapReduce 明显的缺点。Spark的中间输出结果可以保存在内存中,因此能更好地适用于数据挖掘与机器学习中迭代次数较多的算法。
MapReduce
MapReduce 作为计算模型,用以进行大数据量的计算。其中Map 对数据集上的独立元素进行指定的操作,生成键-值对形式中间结果。Reduce则对中间结果中相同“键”的所有“值”进行规约,以得到最终结果。MapReduce 这样的功能划分,非常适合在大量计算机组成的分布式并行环境里进行数据处理。
Apache Airfow
成功案例国家超级计算无锡中心“工业仿真云平台”

云平台以国家超级计算无锡中心“神威·太湖之光”超级计算机、通用 X86 高性能集群为基础,提供“X86 架构+SW64 架构”的海量计算资源。以丰富的图形 GPU 资源为支撑,可保障大规模 CAE 仿真模块的图形化前后处理程序流畅运行。
产品推荐







