







袋鼠云离线开发BatchWorks
立即咨询
 首页
首页 当前背景环境数仓转型所面临的挑战
当前背景环境数仓转型所面临的挑战
数仓转型目标
构建离线数仓的方法论拆解
业务调研业务调研目标:对于核心业务流程,梳理参与角色、主要环节、关键动作及结果,明确每个业务节点参与角色的关注重点和数据来源。
 数仓主题域与主题划分
数仓主题域与主题划分
 逻辑建模
逻辑建模
 物理建模
物理建模数据开发简介:通过业务需求分析进行数据模型设计-开发-测试-上线,涉及多角色跨团队协作。
 离线开发如何参与构建该体系
离线开发如何参与构建该体系
产品定位 产品架构
产品架构
 产品特点
产品特点
利用离线开发BatchWorks进行数据开发
第一步 集群与项目配置
 第二步 数据集成(采用自研同步工具ChunJun)
第二步 数据集成(采用自研同步工具ChunJun)
 第二步 数据集成(功能特点)
第二步 数据集成(功能特点)
第三步 数据开发• 支持20多种周期/手动任务和临时查询,满足大多数数据开发场景,插件化设计模式,可按需求灵活拓展。
• 全Web化开发平台,团队协同高效流畅。
 第三步 数据开发(功能特点)
第三步 数据开发(功能特点)
第四步 调度配置Taier:袋鼠云数栈自研大数据分布式可视化的DAG任务调度系统
 第五步 任务发布
第五步 任务发布
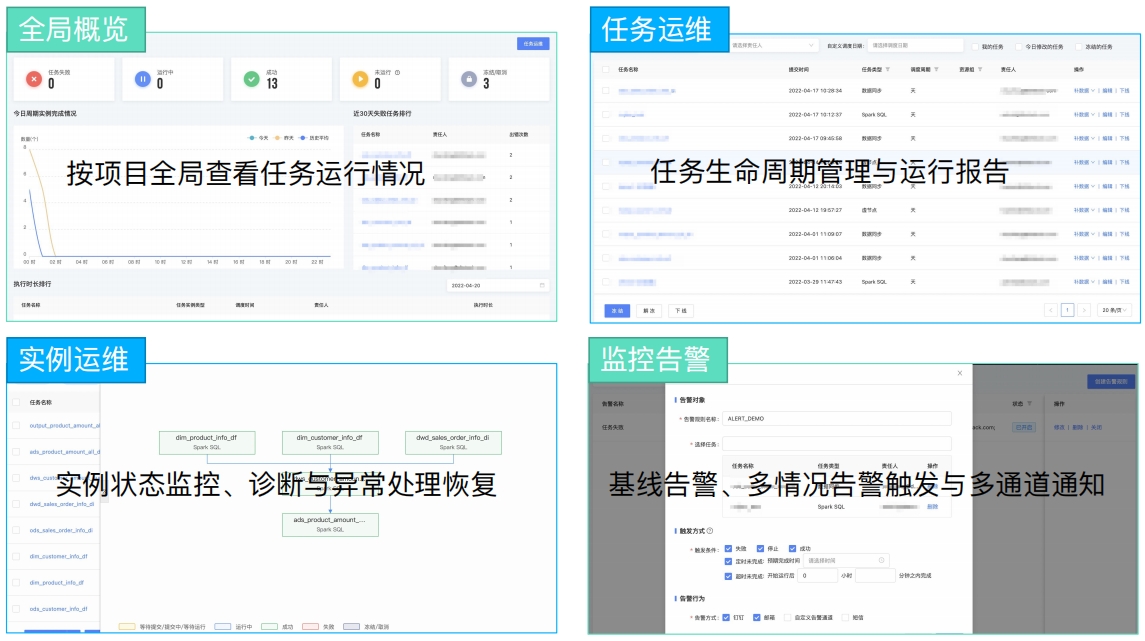
 第六步 任务运维
第六步 任务运维
 产品价值
产品价值
某银行客户
 某大型国有集团客户
某大型国有集团客户
 某高校客户
某高校客户
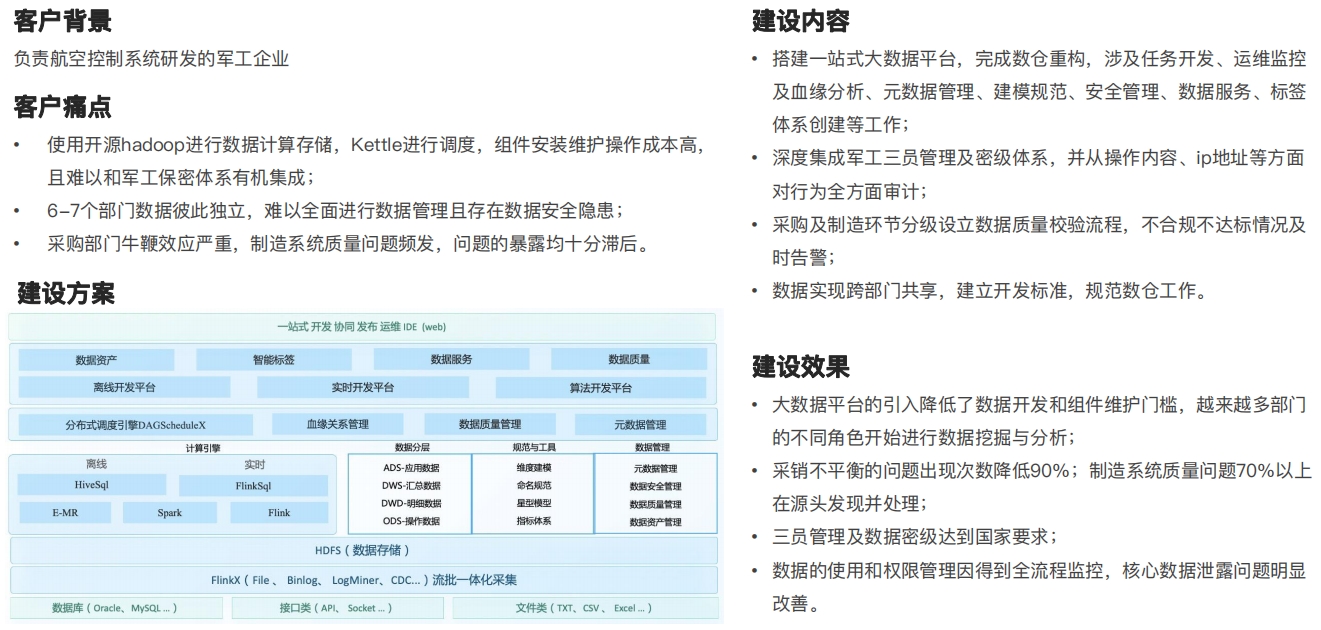
 某军工客户
某军工客户
产品推荐

中服云物联网平台V4.0,网络延迟小,更加稳定可靠,可深度定制系统功能,投入成本高。提供实时数据、实时报警、历史数据、元数据等接口,用于第三方应用或者组件使用。图形化界面编排物联数据流处理业务,快速完成数据处理需求。


喔趣科技智能薪酬绩效管理系统,覆盖客户业务需求场景,快速高效精准地完成大中型企业薪资计算与发放的全流程管理。规范的薪酬体系便于集团化管理,灵活的算薪公式满足各种业务需求。薪资计算发放流程线上化处理,多维度可视化人力成本看板。

市域社会治理现代化解决方案全面融合腾讯优势,围绕市域社会治理现代化试点建设内容,充分借助微信触达能力实现政企民的无缝连接,探索“互联网 + 社会治理”创新模式,助力打造共建共治共享的标杆,实现面向“中国之治” 的未来智慧社会目标。



