
 服务系统 在分析层面的局限
服务系统 在分析层面的局限 实时获取数据分析见解
实时获取数据分析见解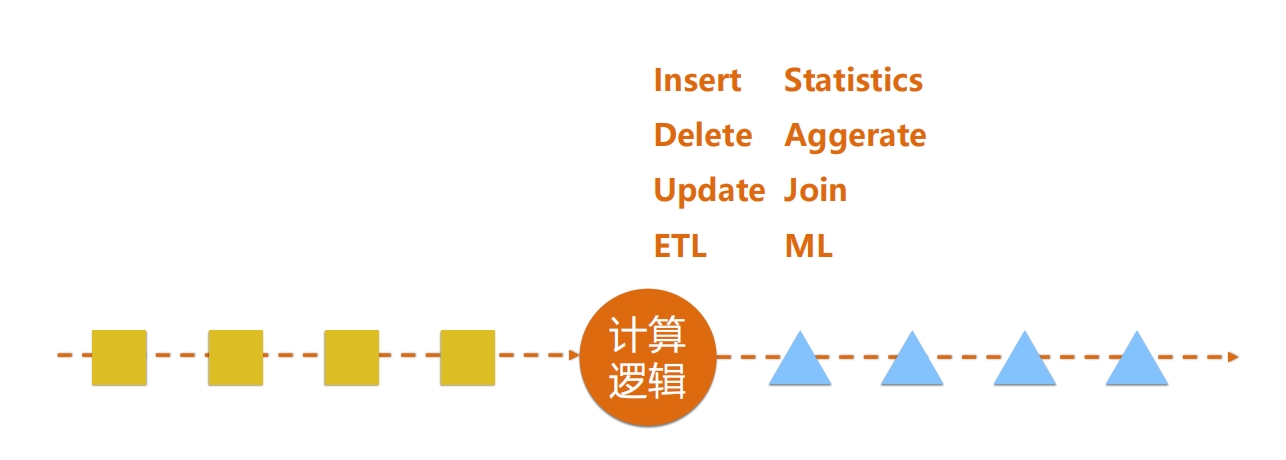 批处理和流处理的区别?
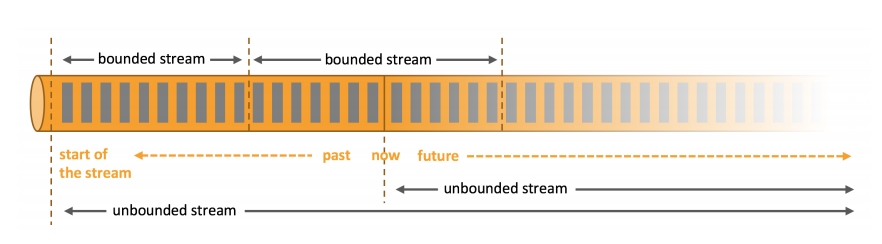
批处理和流处理的区别? 什么是实时数据处理?
什么是实时数据处理?计算结果要低延时,处理无序、无边界的数据,强一致性,保证业务场景可用,支持时间属性的处理
流计算的三种语义at-most once语义,实现起来最简单,只要把数据低延时的deliver下去,就可以了。at-least once语义,允许数据重复计算,但不可以丢数据。几乎所有系统都能够做到这一点。exactly once语义,业务通常对数据准确性有严格要求,实现起来最复杂,各种系统的实现也不太相同。

如何开发流计算?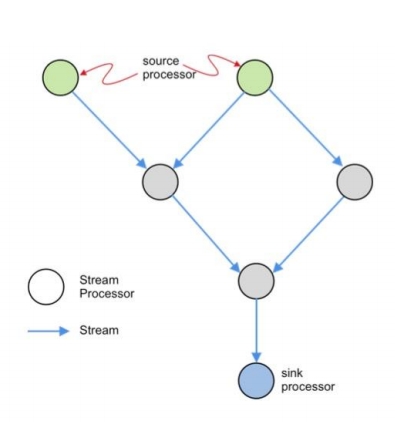 处理延迟数据
处理延迟数据举个例子,假设定义一个跨度为5分钟的sliding window,触发时间为5s,假设在1小时以后,有一条数据来晚了,是需要assign到1小时以前的某些window中,而之前的window已经完成计算,这条数据该如何处理?如果丢弃掉,那么计算结果的一致性无法保障,如果要计算,那必然要把1小时以前的多个sliding window的数据要保留起来,如何保存?如果跨度是1天呢?
有状态的计算流计算处理的数据是无边界的,同时要进行低延时的计算和输出,还要保证计算结果的强一致性。如果一个事件的影响取决于它之前发生的所有事件,那么计算一定是有状态的,会涉及到保存明细数据还有聚合操作产生的中间结果。如何高效并且正确的管理这些状态就变得非常重要。依靠状态管理可以完成很多场景:例如时间窗口、统计分析、欺诈检测

无状态的计算流计算处理的数据是无边界的,如果一个事件不与其他事件有任何关联,那么计算是无状态的

Flink中的状态管理 - Chandy-Lamport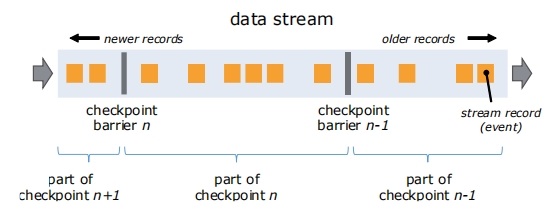 Flink状态管理的注意事项全量计算 与 增量计算
Flink状态管理的注意事项全量计算 与 增量计算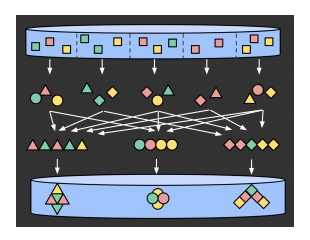
 如何实现全量计算
如何实现全量计算
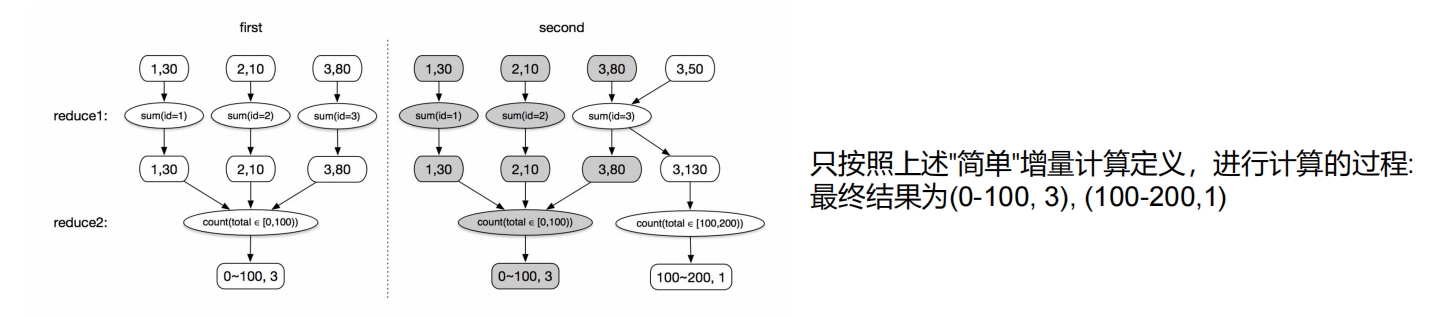
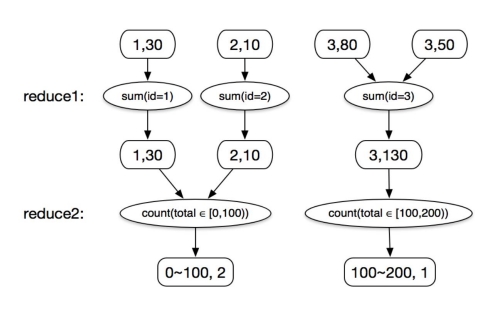 如何实现增量计算
如何实现增量计算1. 增量计算的本质是一个update过程,而不是一个insert过程。在产生计算结果输出的时候,不仅要把新产生的结果输出到下游,还要把之前输出产生的结果,造成的影响撤销掉。类似于将一个update操作转化成一个delete加一个insert操作。2. 对于下游的operater, 不仅要处理insert操作,还要处理delete操作。我们再把这两条应用到上述的增量计算的过程,看看会得到什么样的结果。
回撤 流计算的结果如何进行更新?如上图所示,对wordcount计算后的结果按奇偶进行分桶:当第一个a完成计算,count(a)=1,所以,会把奇数桶的值改成1。当第二个a完成计算,count(a)=2,所以,会把偶数桶的值改成2。那么问题来了,这个a又不是薛定谔的猫,目前只应该存在于偶数桶中,那么奇数桶应该变成0,怎么把奇数桶变成0呢?

增量计算+回撤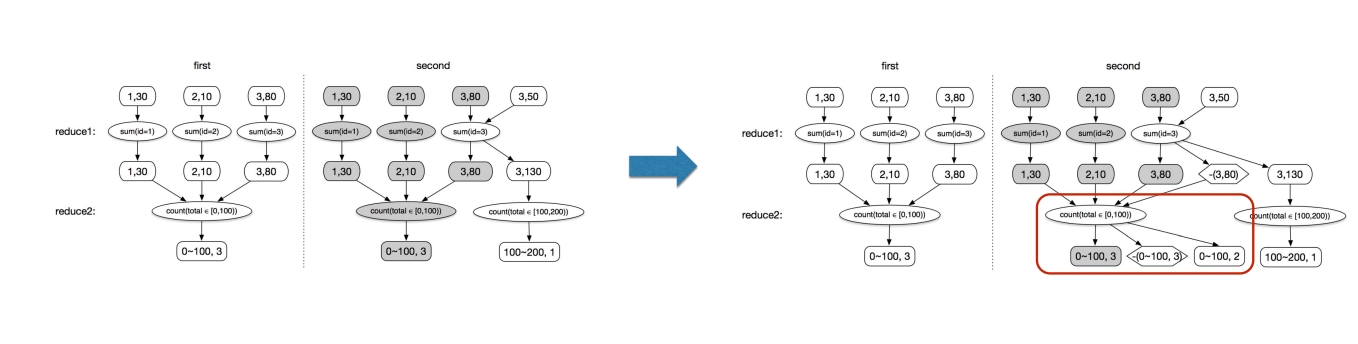 增量计算总结
增量计算总结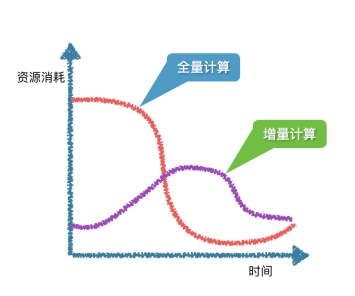 数据流与增量表
数据流与增量表增量计算处理的是数据流Stream,数据库处理的表Table。Stream其实是Table的changeLog, 而Table是stream进行增量计算的结果

时间类型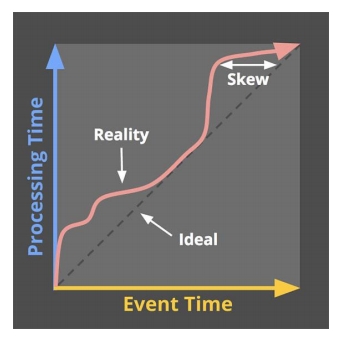 处理时间和事件时间的区别
处理时间和事件时间的区别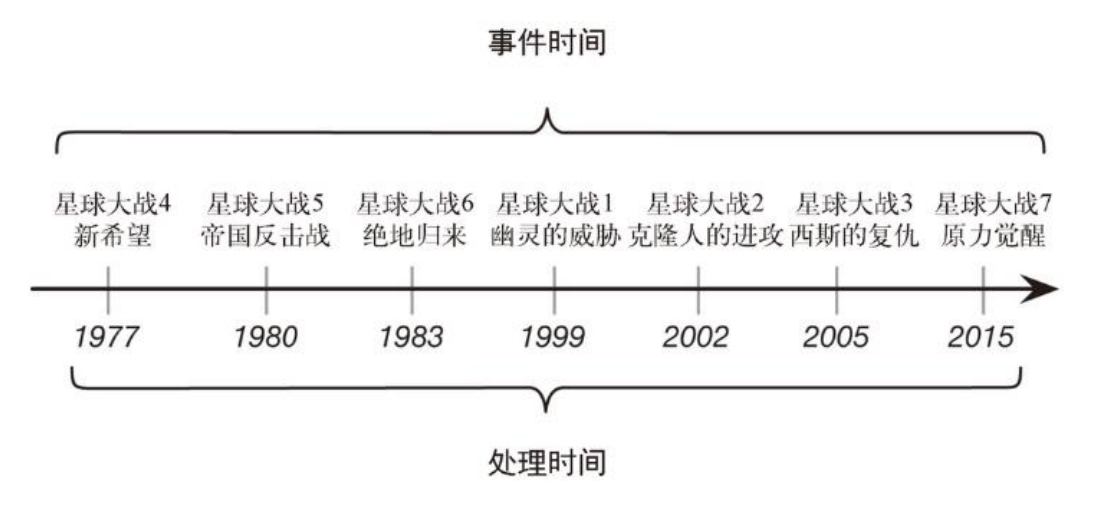 不感知时间计算
不感知时间计算时间无关的处理,即所有相关逻辑都是数据驱动的。只需要关注到达的数据即可,因此除了基本数据传输之外,流引擎实际上没有什么特别需要支持的。

窗口 感知时间的计算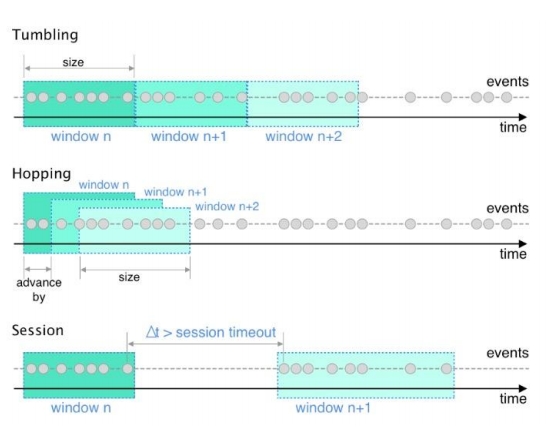 窗口类型
窗口类型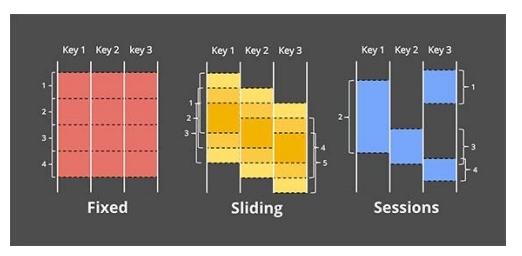 ProcessTime开窗
ProcessTime开窗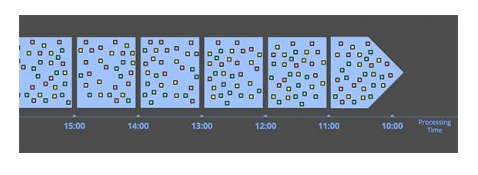 EventTime开窗
EventTime开窗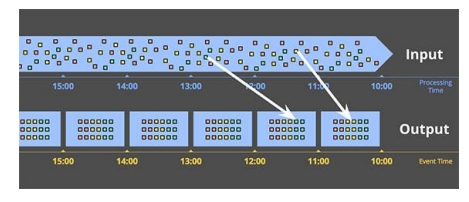
物联网应用开发 (IoT Studio),是阿里云针对物联网场景提供的生产力工具,可覆盖各个物联网行业核心应用场景,帮助您高效经济地完成设备、服务及应用开发。物联网开发服务提供了移动可视化开发、Web 可视化开发、服务开发
可视化搭建
与设备管理无缝集成
丰富的开发资源
阿里云双碳能耗云-工业园区双碳解决方案,充分利用物联网和大数据技术,看到园区碳排情况,增加“双碳”管理功能, “一图掌 控”绿色低碳发展。以低碳发展为准绳,探索园区减污降碳协同治理,分类精准进行产业调整,促进园区高质量发展。实现园区能源供给低碳、生产节能降碳、绿色建筑脱碳、办公生活低碳化。
增加“双碳”管理功能
绿色低碳发展
促进园区高质量发展
办公生活低碳化















领先的企业数字化服务平台
客服电话:400-0972-788

