







阿里云DataWorks大数据开发治理平台
 首页
首页 企业的数据治理工作开展了很多年,依然成效有限DataWorks 产品架构图
企业的数据治理工作开展了很多年,依然成效有限DataWorks 产品架构图 DataWorks 产品核心优势 阿里巴巴大数据建设最佳实践与方法论的10+年结晶DataWorks 认证及荣誉奖项
DataWorks 产品核心优势 阿里巴巴大数据建设最佳实践与方法论的10+年结晶DataWorks 认证及荣誉奖项 数仓建设从“精益生产”到“敏捷制造”
数仓建设从“精益生产”到“敏捷制造”从“小步快跑,快速满足需求为先”到“规范化,可持续发展”的数仓建设理念转变

DataWorks 智能数据建模智能数据建模是DataWorks基于阿里数据中台方法论和Kimball维度建模理论自研的数据建模产品,与DataWorks数据开发体系无缝衔接
 DataWorks 数据集成解决的问题DataWorks 数据集成 - 数据上下云的枢纽
DataWorks 数据集成解决的问题DataWorks 数据集成 - 数据上下云的枢纽支持50+关系型数据库、非结构化存储、大数据存储、消息队列之间的数据同步

DataWorks 数据集成实时同步核心能力 DataWorks 全链路数据开发平台
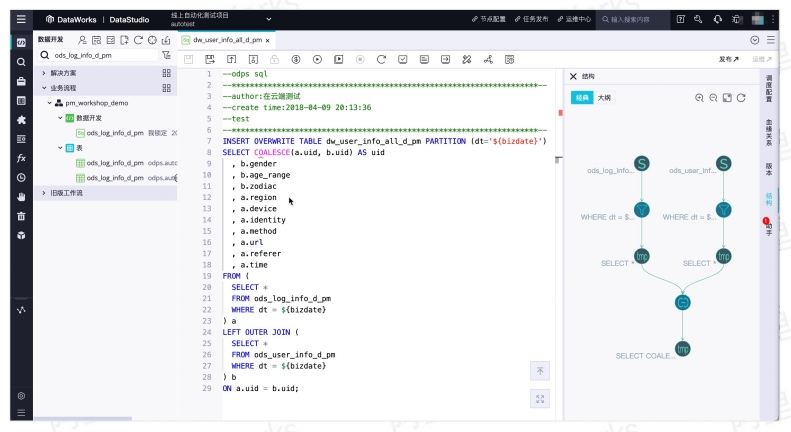
DataWorks 全链路数据开发平台 DataWorks 数据开发(Data Studio)
DataWorks 数据开发(Data Studio)Data Studio支持阿里云MaxCompute、Hologres、E-MapReduce、CDH、AnalyticDB、Clickhouse等多种计算存储引擎的数仓开发,可构建复杂的业务流程和调度依赖,提供开发、生产环境隔离的研发模式
 DataWorks 数据分析
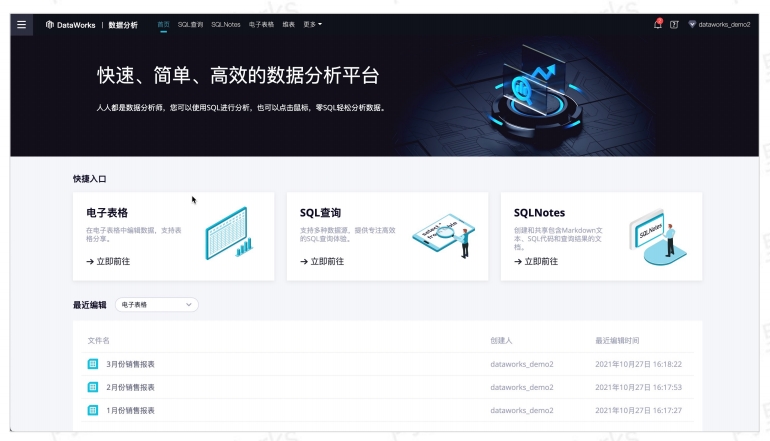
DataWorks 数据分析DataWorks数据分析可以便捷的连接各类数据源,提供电子表格、SQL查询、SQLNotes等多种数据分析能力,适用于数据分析师、业务运营等人员日常工作取数、查数和报表分析等需求场景。
 DataWorks 任务调度系统
DataWorks 任务调度系统日千万级超大规模周期性任务调度系统,久经阿里巴巴“双11”考验,性能与稳定性业界领先
 DataWorks 任务运维中心
DataWorks 任务运维中心提供图形化任务运维管理,支持千万级任务依赖图(DAG)逐级展现,一个人就可以管理和运维成百上千个任务,极大降低了运维成本
 企业数据治理的挑战
企业数据治理的挑战实现数据治理的“问题发现-问题治理-治理评估”,让企业数据治理步入“自动化”阶段

DataWorks 数据治理核心能力:数据治理中心DataWorks数据治理中心针对多个治理领域,围绕数据研发全链路,进行综合治理健康分评估,推动治理工作。系统通过数据领域规则沉淀,自动识别资产待优化问题项,提供覆盖事后及事前的治理优化策略方案,帮助用户主动式、体系化完成数据治理工作。

DataWorks 数据治理核心能力:元数据管理(数据地图)数据资产的有序组织,快速查找数据、理解数据和使用数据,助力数据的便捷消费

DataWorks 数据治理核心能力:智能监控管理一键实现工作流的全链路监控告警配置,解决复杂工作流告警无从配置的难题

DataWorks 数据治理核心能力:数据质量管理DataWorks数据质量(Data Quality Center)针对数据开发全链路,保障数据可用性。通过对数据质量规则的高效执行校验,以及和任务调度流程的紧密结合,能帮助用户第一时间发现质量问题、有效防止数据质量问题扩散。为业务提供高效、可靠、可信赖的数据

DataWorks 数据治理核心能力:数据安全管理提供完善的细粒度数据权限控制,数据分类分级、敏感数据发现与脱敏、风险识别、预警与审计等数据安全能力

DataWorks 数据服务核心能力:低代码构建数据API通过数据服务,用户能够将数据表快速生成数据API,或将已有API快速注册至本平台进行统一管理与发布。数据服务还支持编写函数对API进行加工处理;支持将若干API与函数可视化编排为工作流程,零代码实现API的串、并行调用

DataWorks 数据服务解决从数仓到应用的“最后一公里”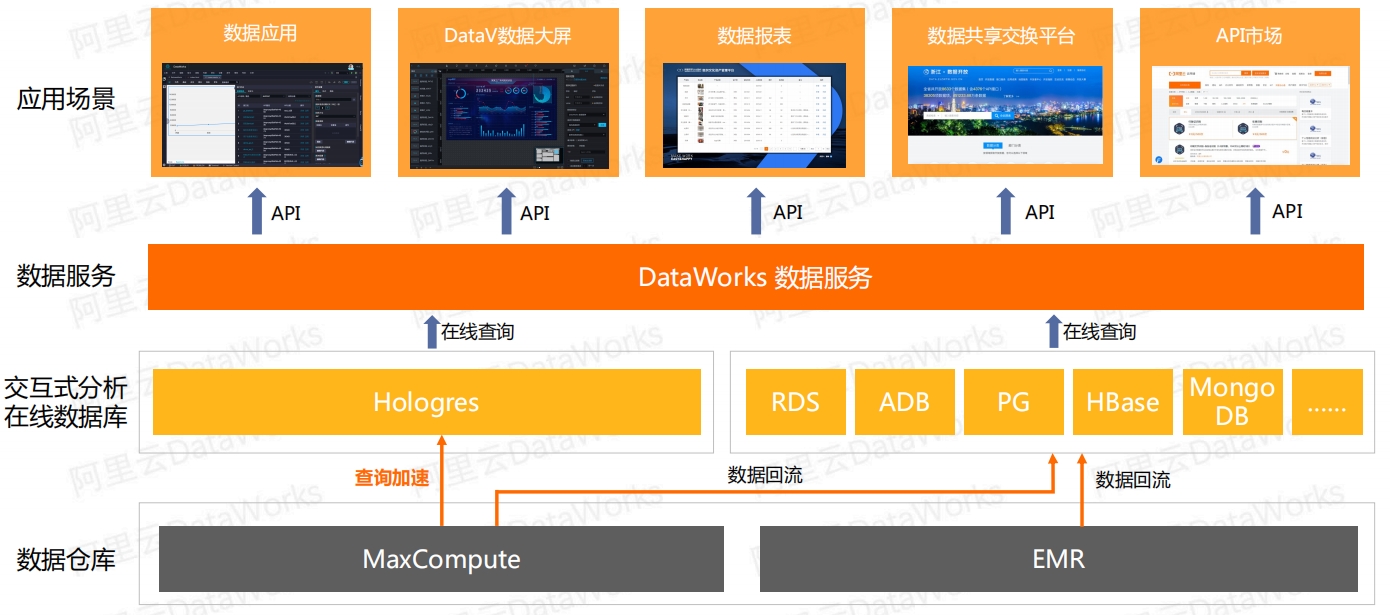 DataWorks迁移助手与迁云专家服务
DataWorks迁移助手与迁云专家服务DataWorks迁移助手支持将开源调度引擎的作业迁移至DataWorks;DataWorks作业跨云、跨Region、跨账号迁移;DataWorks作业快速克隆部署;同时提供迁云专家服务。

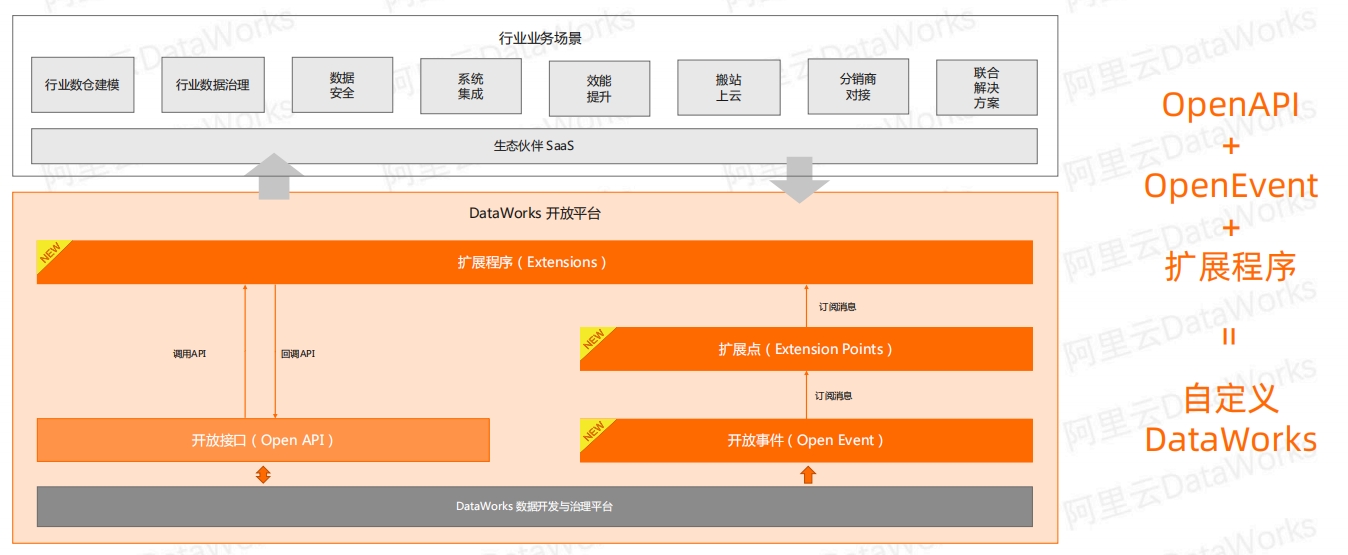
DataWorks 开放平台DataWorks开放平台提供了丰富的OpenAPI、OpenEvent以及插件化能力(扩展点及扩展程序),允许用户自有系统与DataWorks进行深度对接,以及对DataWorks的处理流程进行自定义。
离线实时一体化数据仓库解决方案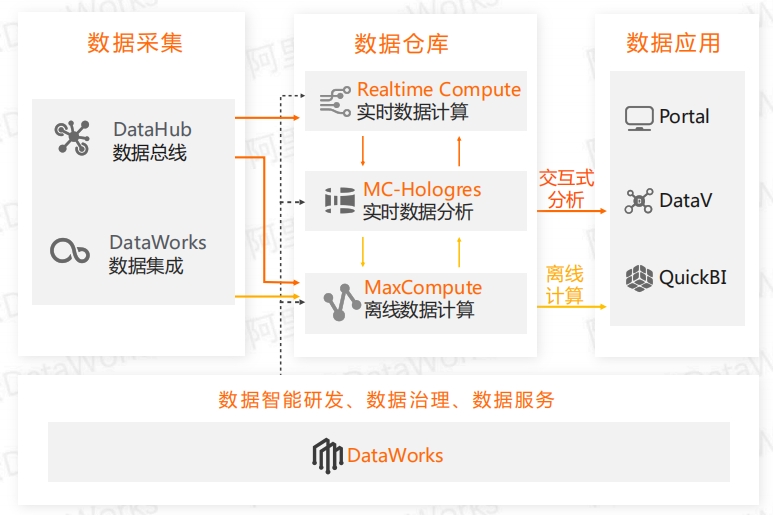 数据湖分析解决方案
数据湖分析解决方案 智能推荐解决方案
智能推荐解决方案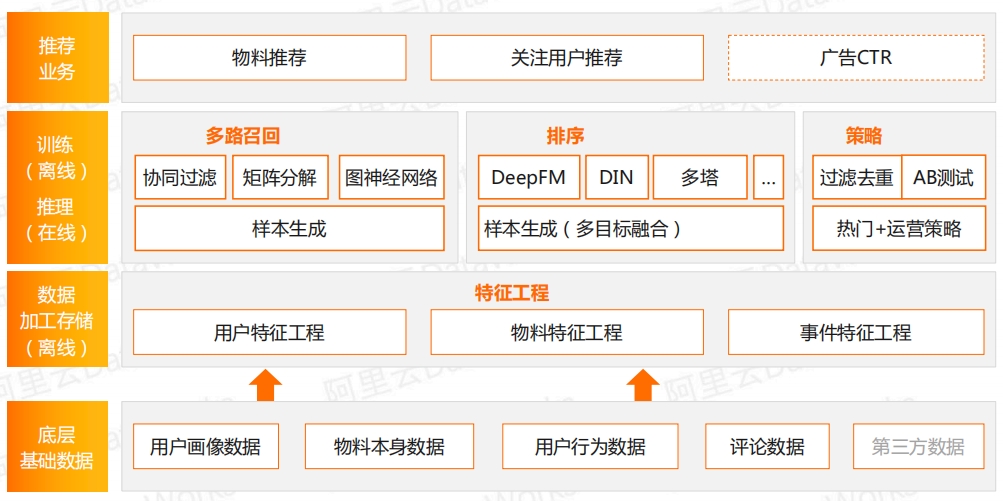 DataWorks 产品在线体验
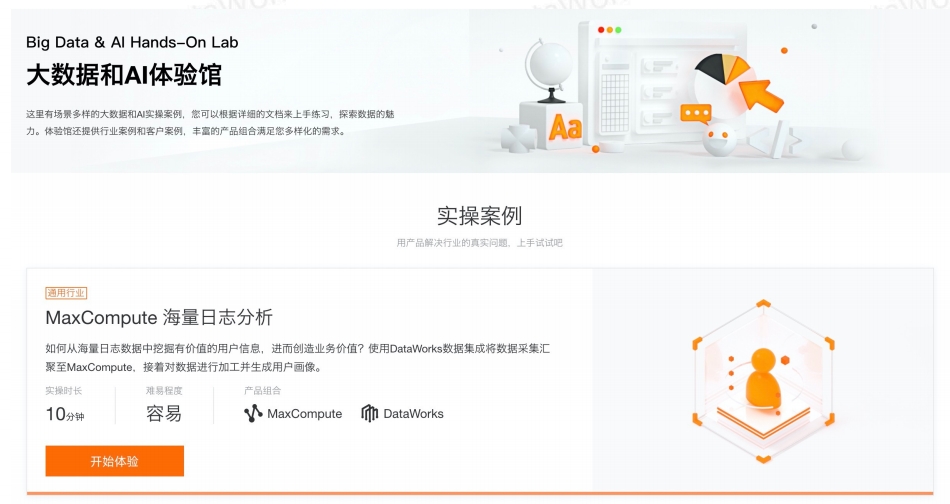
DataWorks 产品在线体验阿里云大数据和AI体验馆提供了沉浸式大数据及AI案例体验,通过Step-by-Step的实操引导,带您快速体验DataWorks产品及飞天大数据平台中的其他产品
产品推荐







