







DataPipeline企业级实时数据平台解决方案
 首页
首页 各类数据管理技术差异越来越大,全面、准确的实时数据获取困难
各类数据管理技术差异越来越大,全面、准确的实时数据获取困难 随着数据技术的不断发展,针对某些具体场景的特性在不断被增强,使得各类数据技术的差异性进一步扩大,但被纳入其中的数据本身不应该因技术栈不同而阻碍其价值释放。 交易系统、账务系统、管理系统、分析系统、主数据、数据仓库与大数据平台采用的数据库管理技术都不尽相同,数据交换困难重重 数据价值不断凸显,业务创新需要数据支撑,但大量数据没有纳入主数据管理系统,数据仓库与大数据平台又无法满足时效性要求 数据时效性要求越来越高,批量数据交换无法满足需求,但针对不同数据库的增量数据实时采集需要大量的技术储备与研发成本 增量识别字段等方式无法获取准确完整的增量数据,经常为实时数据应用造成障碍,也提升了实时数据的使用成本 不同数据库管理技术在实例、库、模式、表等数据对象上,字段类型、精度、标度等语义模式上都有区别 对上游的结构变化感知与应对都需要针对不同数据库技术区别对待 传输过程中的一致性、冲突、特定类型的数据处理也需要区别对待。
 如何快速响应实时数据需求,把握机会快速建立竞争优势
如何快速响应实时数据需求,把握机会快速建立竞争优势  应用场景实时数据链路兼具业务运营与管理支撑要求,稳定性与容错性问题重重
应用场景实时数据链路兼具业务运营与管理支撑要求,稳定性与容错性问题重重 从客户行为分析到非交易类的触客业务到事件营销再到风控评分,实时数据链路逐渐成为业务运营的重要支撑,但作为打通各业务系统数据通道的中间层,受到的上下游的各类制约,对稳定性的影响尤其严重。 上下游节点的业务连续性和服务级别均高于实时数据链路,实时数据链路需要遵循上下游节点的认证、加密、权限、日志等管理机制; 上游数据对象结构变化与数据对象的处理机制对实时数据链路影响巨大,例如结构变化采用rename方式; 实时数据流量不仅仅需要参考业务交易量,与上游系统的数据处理方式有很大的关系,经常出现一个语句百万行增量的情况; 随着企业多中心及多云战略的执行,部署在不同网域或云环境的系统配置,网络连通性乃至专线供应商与带宽都对稳定性有影响; 对计划、非计划的网络不可用,上下游系统维护,物理删除等非规操作及偶发的错误数据及主键冲突数据没有相应的容错性策略配置; 出现系统故障时,无法保证各个组件的高可用,系统恢复困难,特别是实时数据链路的数据完整性与数据一致性很难恢复。
 典型场景:企业级实时数据管理平台
典型场景:企业级实时数据管理平台 通过多种实时数据技术,支持广泛的数据节点类型,协助客户构建以业务目标为导向的数据链路,按需快速定制、部署、执行数据任务,以支持从传统数据处理到实时数据应用的各类场景。
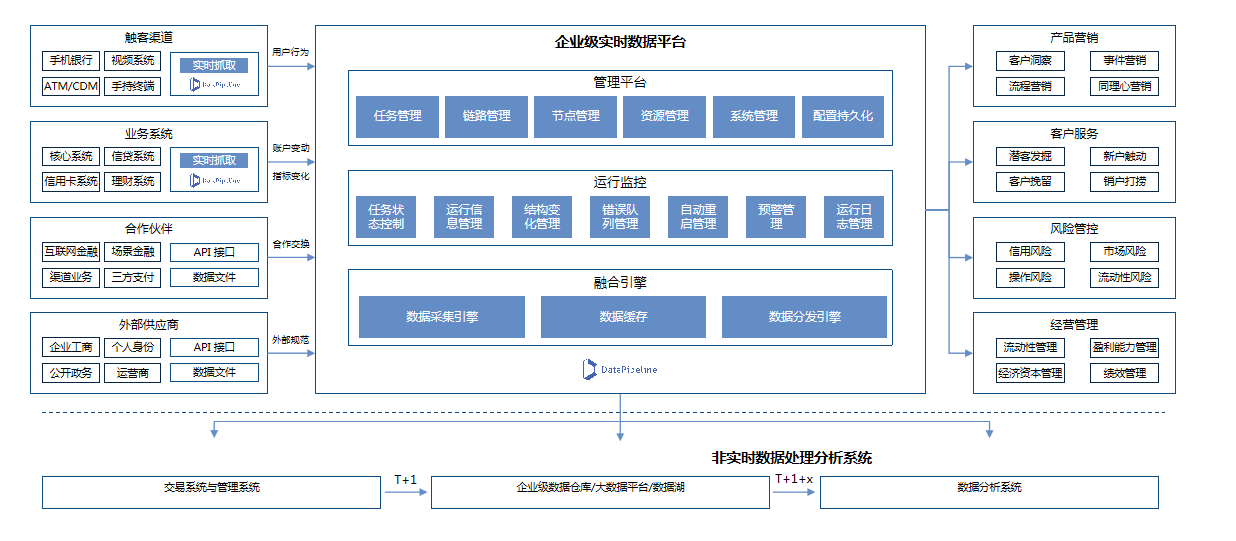 DataPipeline产品整体架构图
DataPipeline产品整体架构图  基于日志的实时增量数据获取技术保证实时数据全面、准确
基于日志的实时增量数据获取技术保证实时数据全面、准确 采用基于日志的增量数据获取技术(Log-based change data capture),为主数据管理、数据仓库、大数据平台提供实时、准确的数据变化,从而使得客户可以根据最新数据进行运营管理与决策制定。 Oracle,通过自有增量数据采集代理读取数据库日志获取准确的增量数据,支持ASM非宿主机部署,同时支持LogMiner; IBM DB2,支持通过集成 IBM InfoSphere Data Replication 解析日志获取准确的增量数据,自动化创建订阅,状态控制协调一致; MySQL,通过Binlog方式获取准确的增量数据,支持5.x,8.x多版本,不支持只读库; Microsoft SQL Server,支持CT模式获取增量数据,CDC模式; PostgreSQL,支持通过wal2json解析日志获取准确的增量数据。
 配置式链路定义,无代码任务构建提升实时数据敏捷性
配置式链路定义,无代码任务构建提升实时数据敏捷性 在数据节点、数据链路、融合任务及系统资源四个基本逻辑概念中,用户只需要通过二至三项简单配置就可以定义出可以执行的融合任务,系统提供基于最佳实践的默认选项,实时数据需求的研发交付时间从2周减少为5分钟。
 配置式链路定义,无代码任务构建提升实时数据敏捷性
配置式链路定义,无代码任务构建提升实时数据敏捷性 为应对复杂的实时数据运行时场景需求,系统提供限制配置与策略配置两大类十余种高级配置。用户可以通过这些配置对下游概念进行限制与管理,亦可以通过这些配置来统一调整下游概念的执行范围与策略应用范围。 基础配置,每个逻辑概念所必须的、最基本的配置项,构成逻辑概念除名称描述以外最基本的属性信息。基础配置在不同逻辑概念中是不同的。 限制配置,数据融合任务在执行过程中,针对不同逻辑对象在不同层次上的限制条件,融合任务执行过程中必须遵循的规则。限制配置在相关的逻辑概念中会遵循依赖关系而互相影响。 策略配置,数据融合任务在执行过程中,出现不同的运行事件及状态变化时的应对策略与管理规则。在相关的逻辑概念中需要遵循,也可以在不违反策略的前提下制定自身的个性化策略。
 数据链路--结构变化策略
数据链路--结构变化策略 结构变化策略是当数据源数据结构发生变化时,系统将为您执行的策略,能够有效避免由于数据源结构变化使任务暂停带来的影响。 结构变化策略需要对数据目的地有更改表结构(alter table)、删除表(drop table)权限,如无该类型权限,遇到数据源结构变化的情况, 执行结构变化策略的任务将报错暂停; 现版本支持结构变化策略的数据目的地有:MySQL、MS SQL Sever、Oracle、PostgreSQL。 由于PostgreSQL 数据源 wal2json 读取模式无法感知数据源删除表,因此日志增量读取阶段不支持数据源删除表结构变化策略。其全量或 JDBC 增量支持数据源删除表结构变化策略。
 数据链路--数据加载策略
数据链路--数据加载策略  数据链路--缓存策略
数据链路--缓存策略  任务执行配置
任务执行配置 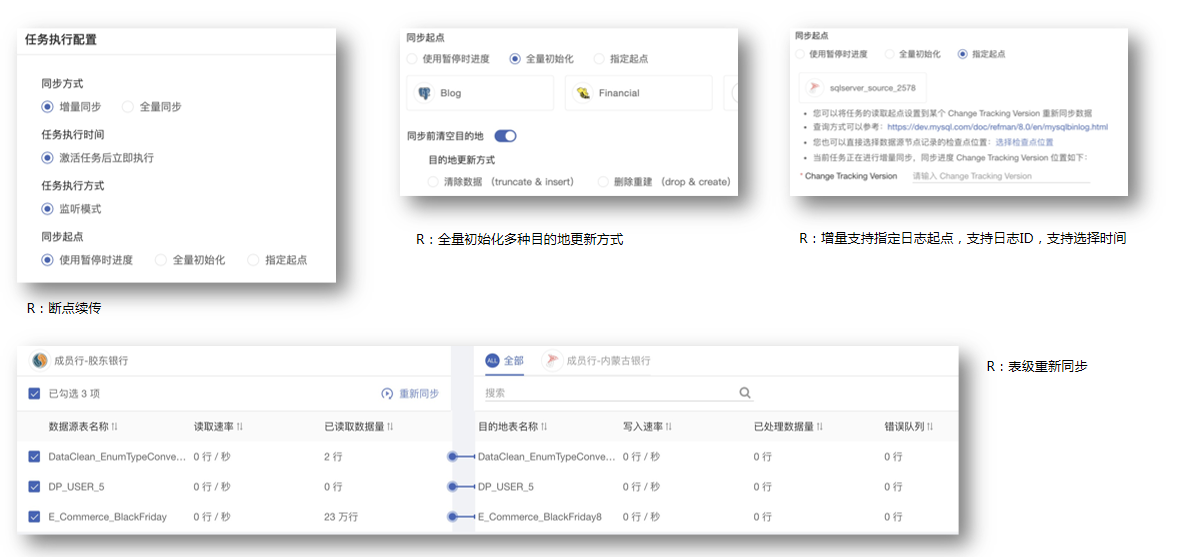 预警策略
预警策略 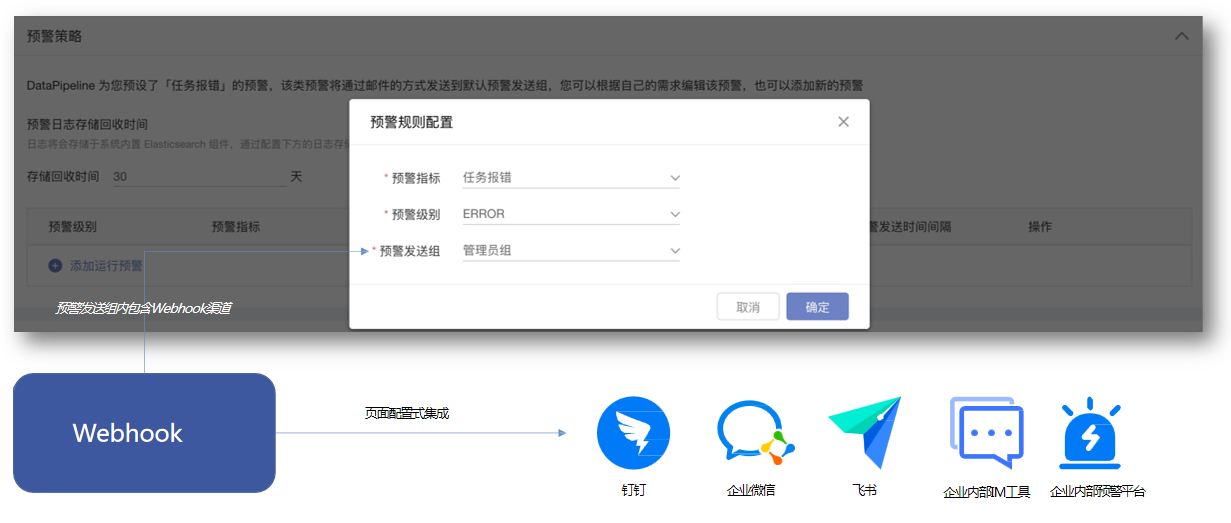 分布式引擎、组件级高可用保障实时链路稳定高容错
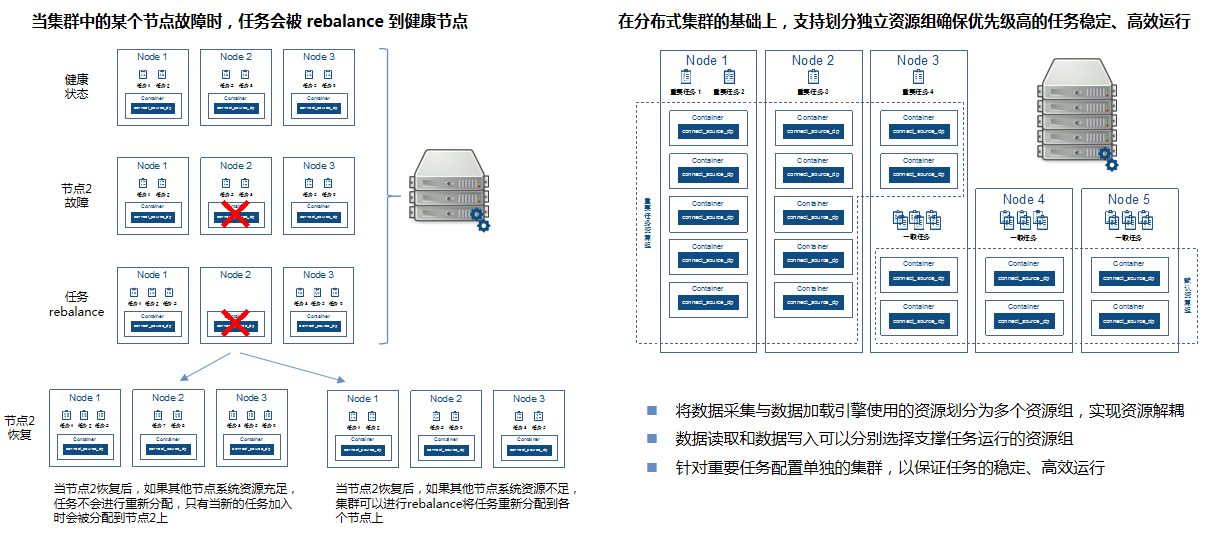
分布式引擎、组件级高可用保障实时链路稳定高容错 企业级实时数据平台所有组件均支持高可用,容器化部署,平滑、灵活的动态扩缩容,允许将不同的计算任务重分布到不同的机器上去,而不妨碍其它部分的运行。
 分布式引擎、组件级高可用保障实时链路稳定高容错
分布式引擎、组件级高可用保障实时链路稳定高容错 融合引擎采用分布式架构,容器化部署。可以保证系统业务连续性要求。在分布式集群的基础上,采用系统资源组的形式隔离不同任务的运行环境,保障重要任务的稳定有序运行。
中国民生银行实时数据管道项目 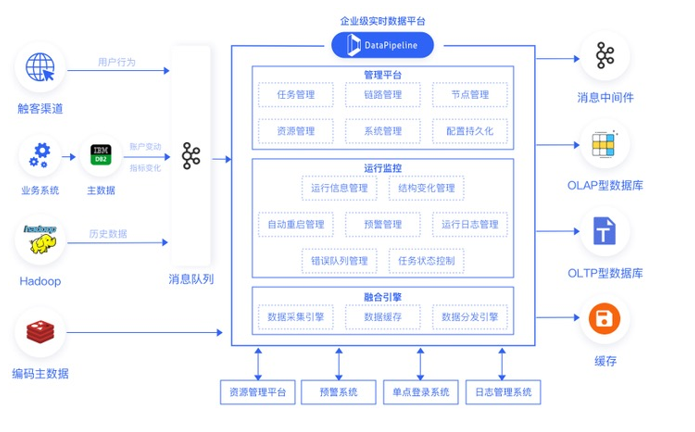 山东城商行联盟数据库准实时数据采集项目
山东城商行联盟数据库准实时数据采集项目 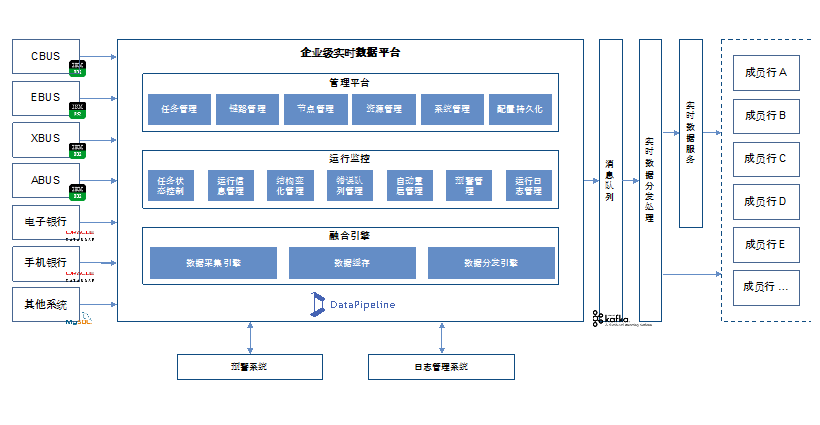 广发证券实时数据融合平台
广发证券实时数据融合平台 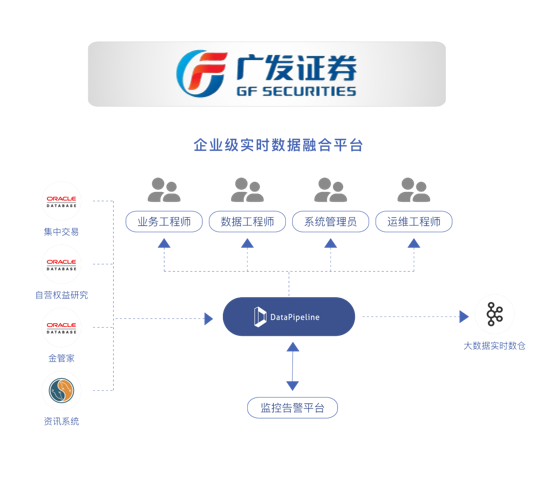 财通证券集团数据交换平台
财通证券集团数据交换平台  招商证券实时数据融合平台
招商证券实时数据融合平台  山西证券数据库实时数据同步平台
山西证券数据库实时数据同步平台 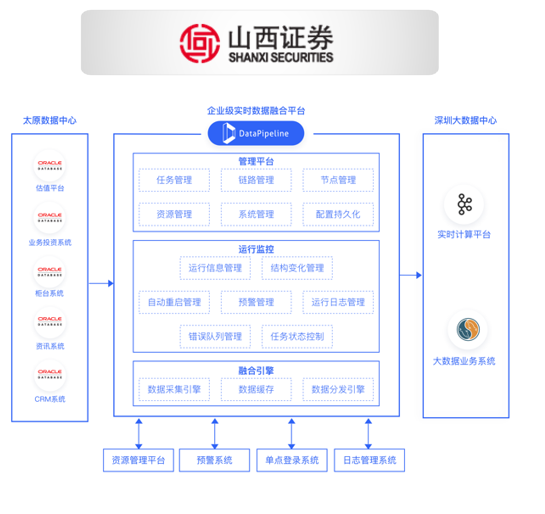 国盛证券实时数据融合平台
国盛证券实时数据融合平台  公司简介
公司简介
 公司资质荣誉
公司资质荣誉 完全自主知识产权产品,深度参与国家标准制定,广泛建立信创生态合作关系。
 重点领域信息化领先客户的广泛应用
重点领域信息化领先客户的广泛应用 深耕企业服务,公司从成立以来把业务重点放在服务业务发展水平高,信息化建设水平高的客户方面。

产品推荐







