







达观数据OCR智能文字识别系统
 首页
首页 文字识别遍布在身边的各个角落
文字识别遍布在身边的各个角落在我们在学习工作和生活中,肯定多多少少遇到过这样的场景。在某本书或者某张报纸上看到一大段有用的文字,想要快速摘录出来。查找到的重要信息存储格式为图像或者文字不可复制的PDF,需要手动输入成文本格式。经常需要输入身份证号码或者银行卡号码之类的长串数字,需要仔细录入反复核对。有大批量的表格、单据、合同等纸质材料需要转化为电子文档保存。报销发票时候需要一张张录入票据手动计算金额......

文字使用的场景和方式复杂多变OCR是实现文字识别的最佳实现方式光学字符识别,即Optical Character Recognition,简称 OCR,是专门解决文字识别问题的人工智能技术;采用光学的方式将纸质文档中的文字转换成为黑白点阵的图像文件,并通过识别软件将图像中的文字转换成文本格式,它让计算机像人一样看图识字,不管是扫面件、图片还是纸质文件都可以轻松搞定。

OCR识别面临着各种挑战达观渊识OCR功能概览 功能1:文档结构化智能抽取
功能1:文档结构化智能抽取任何你能想到的形式都可以轻松识别,目前已支持242种类型的证件、表单、文件的识别和结构化抽取。

功能2:文档分类和归档能力 功能3:文件类型拓展能力
功能3:文件类型拓展能力 功能4:健全的模型训练能力
功能4:健全的模型训练能力只需一份标注文件,标注完成后系统自动训练模型,简单快捷

功能5:机器预标注能力基于已经标注类似模板,渊识OCR具有强大的自标注能力,在人工未标注之前完成机器标注,人工只需复核即可。

达观渊识OCR技术框架接入层:包括协议转换、参数输配和结果适配等。框架层:图像识别服务运行的系统框架,加载运行算法,提供稳定的识别服务,包括:Master:接收接入层的请求,进行请求拆分、请求调度、结果合并等。Worker:实际执行算法的进程载体,主要包含算法SO/模型的加载、更新,进行算法的执行。Zookeeper:存储worker心跳信息、算法映射关系、算法执行计划、算法静态/动态快照信息等。ConfigServer:监听worker心跳并实时更新动态动态路由表,触发master更新路由规则及连接池。算法层:算法人员提供各种算法模型及算法so。周边系统:评测系统:提供版本评测功能,存储系统:非敏感图片及badcase存储。监控告警:监控服务的运行状态,在异常时进行告警。日志系统:请求日志的存储,为问题的跟踪排查提供依据框架运行时。

OCR行业应用场景图谱OCR为AI添上一双“慧眼”,已经在各行各业中得到广泛的应用。

场景1 企业财务报销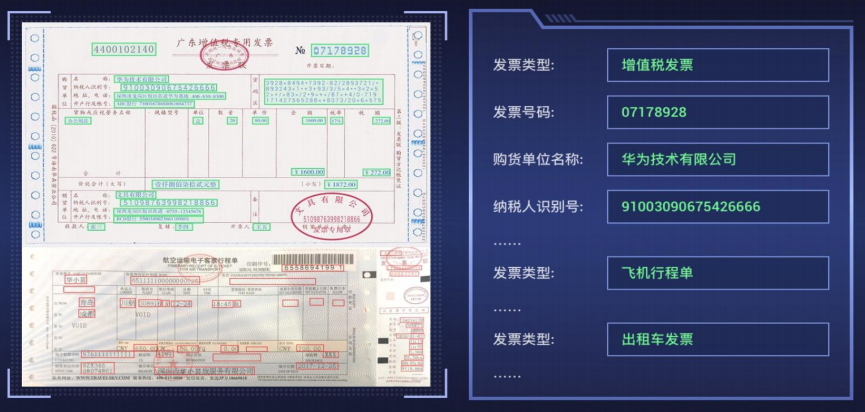 场景2 保险-智能理赔
场景2 保险-智能理赔谋国内知名保险公司在使用达观渊识平台后,工作效率提升了60%~80%

场景3 银行信贷业务-财报识别 场景4 政府行政审批
场景4 政府行政审批 达观达观源识OCR平台打造独树一帜的AI慧眼
达观达观源识OCR平台打造独树一帜的AI慧眼跟进计算机视觉、图像处理、自然语言处理、深度学习、迁移学习、强化学习等领域最前沿的算法,并致力于将其工程化应用到OCR系统上。独有的计算机视觉和自然语言处理深度融合技术,独有的多算法融合技术。

技术优势1:独有的计算机视觉和自然语言处理深度融合技术 技术优势2:基于视觉注意力的深度学习文字识别技术
技术优势2:基于视觉注意力的深度学习文字识别技术采用视觉注意力模型技术对图像进行特征提取,然后进行序列特征提取,最后使用注意力模型作为解码器输出最终的文字序列

技术优势3:先进的文字定位技术基于深度学习和全卷积网络的关键点定位技术,采用倾斜矫正算法、最大轮廓提取算法、表格线去干扰算法和文字框定位算法等多种技术手段相互融台,进一步提高文字识别的精度。
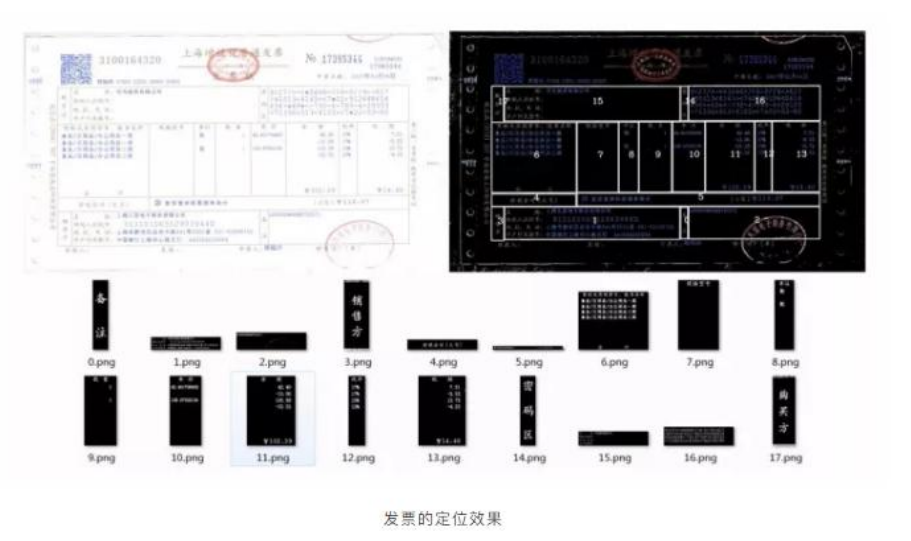
技术优势4:独有的机器学习模型融合算法 技术优势5:快速集成部署 高速稳定运行
技术优势5:快速集成部署 高速稳定运行
产品推荐







