云掣ACOS统一运维监控平台
立即咨询
 首页
首页 企业新发展带来的挑战云掣服务的优势
企业新发展带来的挑战云掣服务的优势 传统监控与可观测性的关系
传统监控与可观测性的关系监控(Monitoring):是以系统可用性为中心,收集、分析和使用明确的信息来观察一段时间内的运行进度,并且进行相应的决策管理的过程。可观测性(Observability):基于白盒化的思路,通过分析系统生成的数据,构建完整的观测模型,理解推演出系统内部的状态。

统一运维可观测套件ACOS--问题与方向统一运维可观测套件ACOS--功能大图 统一日志
统一日志 ACOS统一运维监控平台,让可观测运维更简单
ACOS统一运维监控平台,让可观测运维更简单





 安全生产可观测解决方案
安全生产可观测解决方案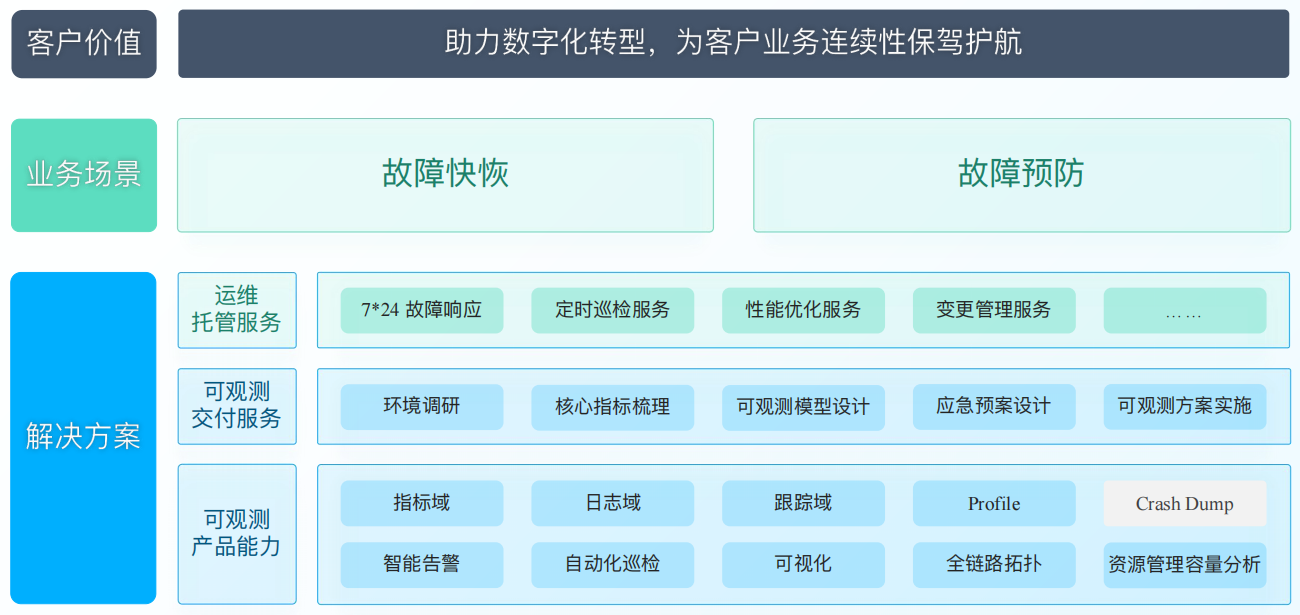 专业的运维托管服务--助力企业快速获取专业的运维能力
专业的运维托管服务--助力企业快速获取专业的运维能力 运维服务整体流程运维服务标准承诺
运维服务整体流程运维服务标准承诺
 解决方案
解决方案 案例一:某市健康码全链路监控
案例一:某市健康码全链路监控背景:XX市新型冠状病毒肺炎疫情防控工作领导小组办公室下发《关于我市持续巩固疫情防控成果有序复工复产的实施方案》,明确XX全面复工复产时间点和任务安排,XX大数据中心要求防疫相关的扫码等服务系统务必保证稳定性,支撑XX人民有序复工复产。痛点:ISV厂商众多,缺乏全局视角,快速定界厂商问题。业务链路复杂,出现故障后定位问题困难,缺乏全链路可观测视角。故障频发,被动响应,缺乏体系化故障梳理。时间紧、客户”因为看见,所以相信”,同时需求变动频繁。

案例二:某券商大数据平台升级扩容
 案例三:某电商迁云
案例三:某电商迁云 公司资质和荣誉
公司资质和荣誉 客户数字化转型的选择
客户数字化转型的选择
产品推荐

企业级Cisco UCSC240 M4服务器扩展了2RU封装的CiscoUCS产品组合的功能。它基于Intel® Xeon® E5- 2600V3处理器系列,可以提供性能、灵活性和效率的优势组合。


硅基数字人通过智能AI技术,结合深度学习算法训练,定制专属虚拟数字人,配备丰富图片、音乐、视频等素材,可高效生成视频,可实现实时虚拟直播,满足用户各类视频或直播场景需要,同时提供数字人克隆包括形象克隆和声音克隆服务。

观远数据新锐消费品数据分析方案,数据驱动决策,新锐品牌潜能资产增长模型,依托AI+BI技术,构建新锐消费品全链路数字化体系。实现数据采集自动化,数据决策全链路闭环。观远自研数据开发平台、BI平台及AI智能应用满足企业不同数字化转型阶段的平台应用需求。