







阿里云数据总线DataHub
立即咨询
 首页
首页 数据总线DataHub-阿里云自研数据总线
数据总线DataHub-阿里云自研数据总线提供对流式数据的采集、存储、分发功能。用户可以基于DataHub轻松构建基于流式数据的分析和应用。【数据采集】:提供SDK、插件、兼容Kafka Producer协议,帮助您采集各类业务数据。【数据存储】:采用存储计算分离架构,计算避免数据热点,存储使用自研盘古系统,具备高安全、多副。本、强稳定的特点,SLA达99.99%【数据投递】:支持涵盖几乎所有阿里云计算引擎,系统无缝对接,连接性好。

产品技术架构负责用户的接入,同时会对Data进行格式化,然后传给Xstream。与pangu的存储集群交互,读写数据, 同时有Metric采集,资源回收等模块。负责将DataHub中的数据同步到其他产品,处理订阅的创建删除,协同消费以及订阅点位的保存和获取。所有模块均运行在Fuxi集群中,以Fuxi Service形式进行管理。系统采用存储计算分离架构,数据均存储与Pangu集群中,不依赖本地磁盘。

产品优势数据总线DataHub—数据采集数据采集:提供多种SDK、API和第三方插件以及Kafka协议,您可以实时接入APP、WEB、IoT和数据库等产生的异构数据,进行统一管理,消除数据孤岛。
数据总线DataHub-数据存储数据存储:灵活设置存储时间,保证下游系统可重新消费数据,自身自动提供数据多备份和存储加密,具备跨机房容灾功能,安全可靠。
数据总线DataHub-数据投递数据投递:提供DataConnector模块,简单配置即可把接入的数据实时同步到下游系统(如MaxCompute、OSS、TableStore等主流系统)极大减轻了数据链路的工作量,实现一投多消。
最新特性阿里云DataHub典型场景-金融行业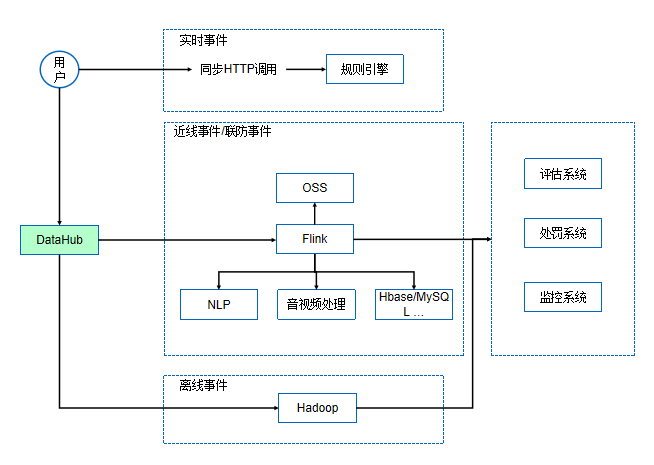 阿里云DataHub典型场景-电商/物流行业
阿里云DataHub典型场景-电商/物流行业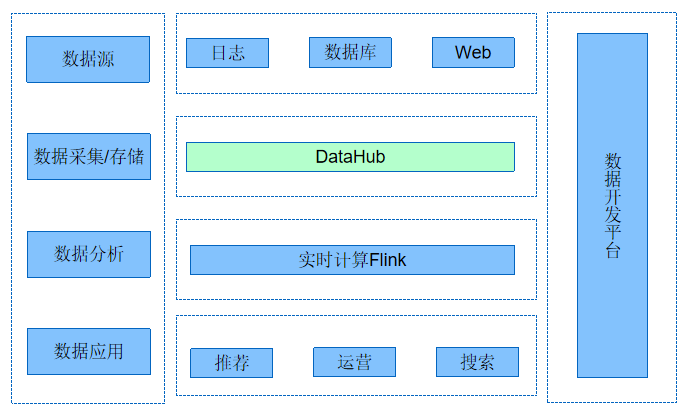 阿里云DataHub典型场景-在线教育/公共安全行业
阿里云DataHub典型场景-在线教育/公共安全行业 阿里云DataHub典型场景-IOT行业
阿里云DataHub典型场景-IOT行业 阿里云DataHub典型场景-互联网
阿里云DataHub典型场景-互联网
产品推荐

深拓智能 scientop 智能装箱码垛系统,革新物流仓储作业。搭载智能码垛机器人,以精准算法实现高效码垛,适应多样货物规格。优化仓储布局,提升空间利用率。且提供透明化仓储码垛机器人价格,为企业降本增效,开启智能仓储新篇。

洲明科技USF户内户外系列,采用底壳+后盖的设计,外观更美观,防护性更强,双模式电源供电,使用更可靠。相对于传统模组节能25-35%,低发热,低屏温,高稳定性,大大提升了产品寿命。


McAfee完整端点保护-企业版中包含适用于大型企业的最高级别终端安全保护功能:除了适用于桌面机和笔记本电脑,还具备协作式高级威胁防御、零影响用户扫描和动态白名单功能。



