







阿里云实时数仓Hologres
 首页
首页 业务在线化、运营精细化依赖数据驱动
业务在线化、运营精细化依赖数据驱动 大数据数仓体系的“纷繁芜杂”
大数据数仓体系的“纷繁芜杂”架构复杂、数据同步难、数据割裂、开发成本高、不敏捷、人才培养难

阿里云云原生一体化数仓云原生一体化数仓是集阿里云大数据产品MaxCompute、Hologres、Flink、DataWorks多种产品能力于一体的一站式大数据处理平台,实现成本更低,速度更快,性能更好,运维更简单。

实时离线一体化数仓:Hologres + MaxComputeHologres一站式实时数仓能力Hologres与Flink深度集成 数据湖加速,支持实时数据湖
数据湖加速,支持实时数据湖 TPCH@30000GB以2789万分勇夺世界第一
TPCH@30000GB以2789万分勇夺世界第一Hologres首次参加TPCH打榜,在30,000GB标准测试结果中,以QphH超2786万分的性能结果斩获全球冠军,领先第二名23%。

Hologres 技术特点计算存储分离架构,资源隔离,高可用,无限弹性资源隔离:支持共享存储多实例(物理级别隔离)高可用模式。多实例同Region部署共享存储,实时高可用,多Region部署数据自动复制,秒级灾备。计算资源物理隔离,实例之间故障隔离,主实例最多4个子实例,支持系统高可用部署。

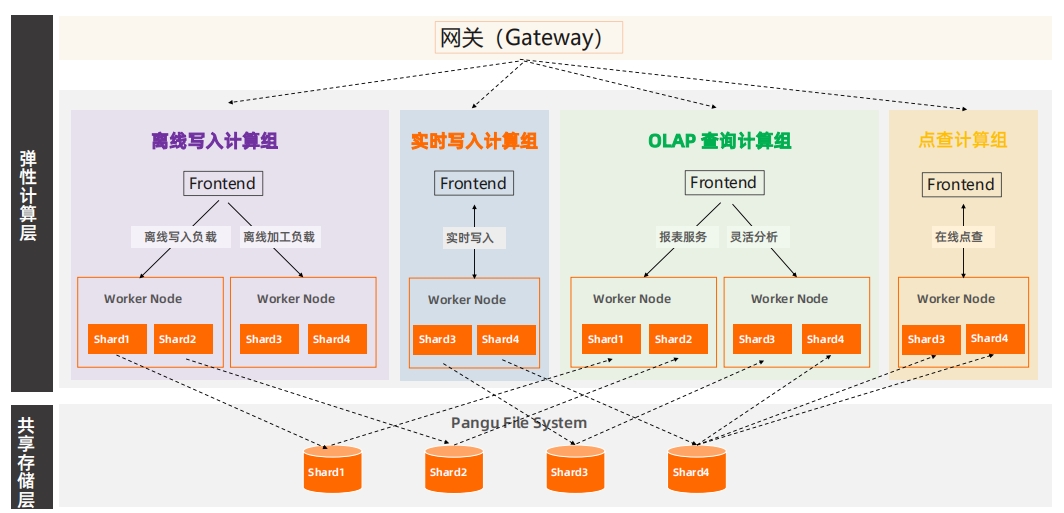
新一代Warehouse,更高的弹性与更极致的隔离在主从实例的基础上,升级为弹性计算实例(Virtual Warehouse,简称Warehouse),实现资源更极致的隔离,包括写写隔离、读写分离等,同时也支持计算组的弹性,满足对资源的高效利用。
 服务(Serving)能力Fixed Plan场景拓展,提升写入性能
服务(Serving)能力Fixed Plan场景拓展,提升写入性能Fixed Plan是Hologres独有的执行引擎优化方式,传统的SQL执行要经过优化器、协调器、查询引擎、存储引擎等多个组件,而Fixed Plan选择了短路径(Short-Cut)优化执行SQL,绕过了优化器、协调器、部分查询引擎的开销。通过Fixed Front End直接对接Fixed Query Engine,实现SQL执行效率的成倍提升,是支持高吞吐实时写入,高并发查询的关键优化方法。 ✓ 单行写入 ✓ 多行写入 ✓ 整行更新 ✓ 局部更新 ✓ 写入支持增加过滤条件 ✓ 写入分区父表

冷热分层,成本优化热数据:访问频次较高的数据,存储在SSD存储介质中,满足高性能访问的需求。1元/GiB。冷数据:访问频次较低的数据,存储在HDD存储介质中,满足高性价比的存储需求。0.144/GiB。冷热数据分层存储提供了支持按照时间将历史分区子表数据归档到HDD存储介质中,满足高性价比的存储需求。
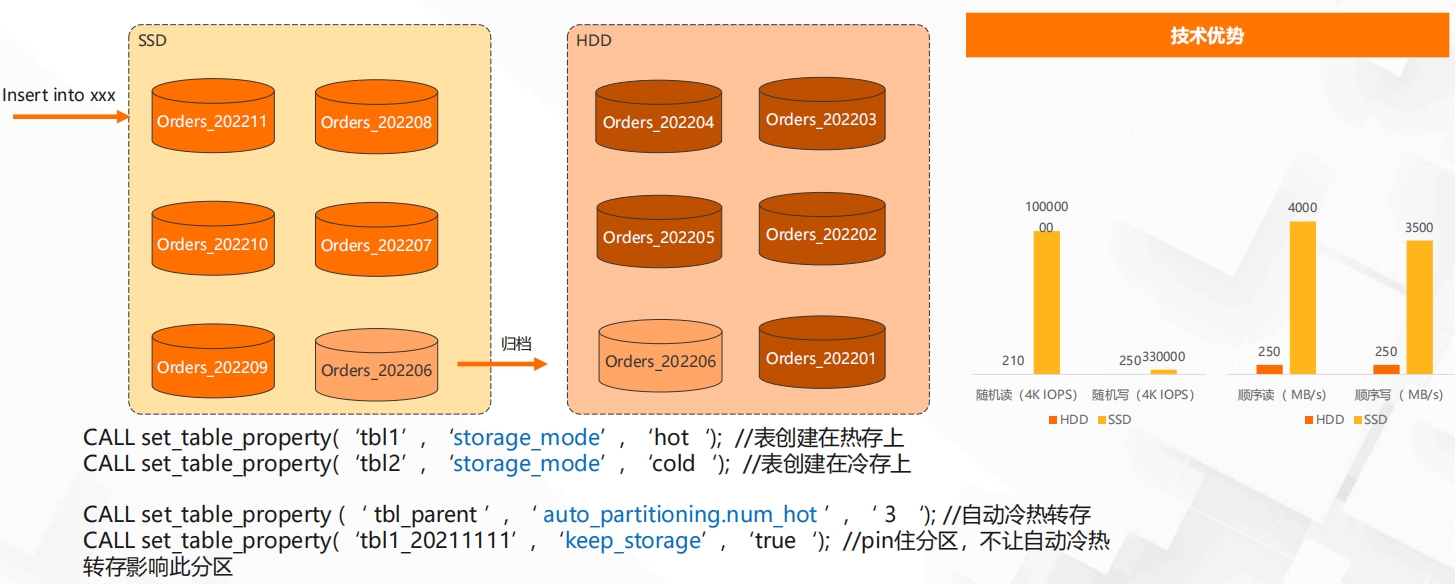
动态分区管理,支持自动删除、创建分区、自动冷热转存Hologres 从1.3版本开始支持动态分区管理,通过建表时设置指定的规则,提前创建分区子表/删除过期分区子表,减少用户管理分区生命周期的负担。

Shard级Replica,提升OLAP吞吐和点查高可用支持单实例上的shard级replica,通过shard副本的机制,提升OLAP查询的吞吐以及点查的吞吐。Shard之间正交,每个Worker Node分配部分Shard的所有权,每个Shard独立负责部分数据的读写操作。请求有可能出现热点,集中部分Worker Node和Shard。支持Shard级多副本,Leader负责读写,Replica只读。读请求均衡由多个Worker Node(Shard)响应,更高并发。建议增加Replica时,同时减少Shard,保持Shard*Replica均衡,最有效利用Worker Node资源。

备份与恢复设置备份周期,自动备份。实例级别全量数据备份,公测中暂不收取备份费用。有一定的资源使用,建议低峰期备份。如果数据被误删除或更新,根据备份快照恢复出一个全新的实例。

查看表日志信息,精细化管理表从1.3版本开始提供表日志信息hologres.hg_table_info,查看表的占用存储变化趋势、表访问趋势、文件大小等,提升对表的进一步精细化管理。最佳实践:查看占用存储较大的表近一个月的访问趋势—治理大表,降存储空间。查看近一周存储较少的表的访问趋势—治理小表,减少内存占用。查看存储较大且查询时间较长的query—治理大表的bad query。

支持实时物化视图,优化聚合查询场景物化视图:是包括一个查询结果的数据库对象,它是远程数据的的本地副本,或者用来生成基于数据表求和的汇总表。用途与优势:数据在写入时即预计算,以空间换时间,提高查询效率。举例:某客户有100多家门店,他想实时查看各个门店营业收入情况,以便实时调整经营策略。

JSON列式存储,提升半结构化数据查询和存储效率JSON列式存储:JSON数据列式存储优化,存储压缩效率接近原生列存,提升查询效率。用途与优势:将JSON类型的数据按照列式存储,提升数据存储压缩效率,减少数据转换等操作,提升查询效率。举例:某视频网站厂商,希望查询男性用户的用户数量和平均年龄。

企业级安全能力
产品推荐







