
 MaxCompute - 产品介绍
MaxCompute - 产品介绍MaxCompute是一款多功能、低成本、高性能、高可靠、易于使用的数据仓库和支持全部数据湖能力的大数据平台,支持超大规模、serverless和完善的多租户能力,内建企业级安全能力和管理功能,支持数据保护和安全共享,数据/生态开放,可以满足数据仓库/BI、数据湖非结构化数据处理和分析、湖仓一体联邦计算、机器学习等多业务场景需求。
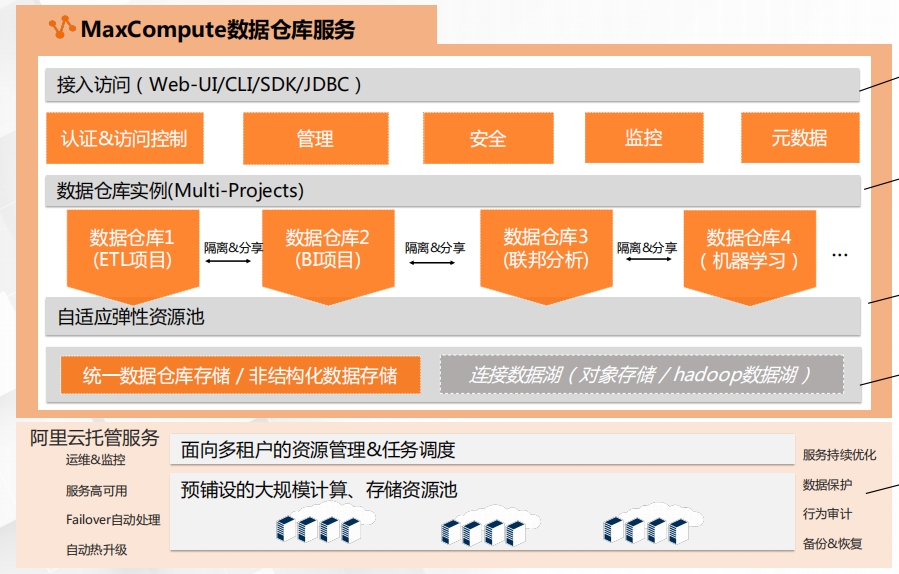 MaxCompute - 产品架构
MaxCompute - 产品架构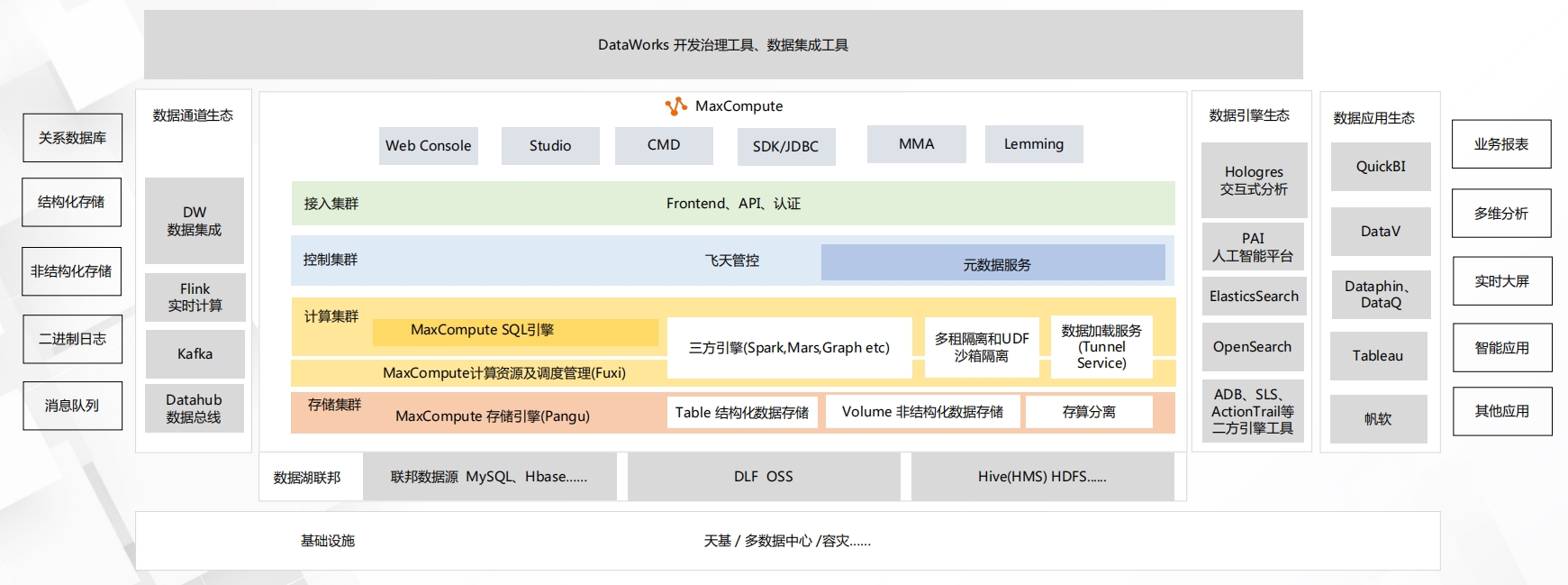 MaxCompute - 应用场景
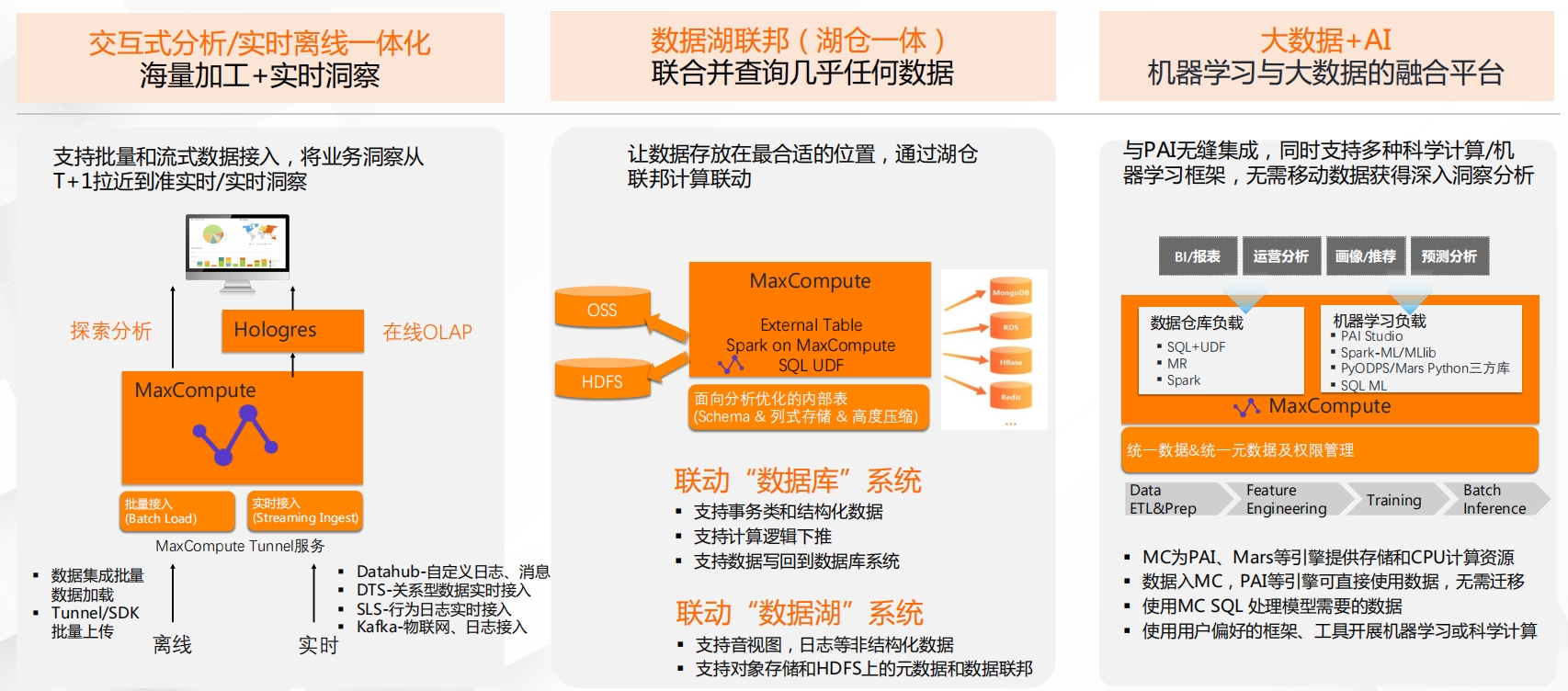
MaxCompute - 应用场景现代化的数据平台(Modern data platform) 要求企业能够对业务做更实时的响应、处理不断增加的不同类型数据、利用新技术挖掘数据更深入的价值。
MaxCompute – 核心能力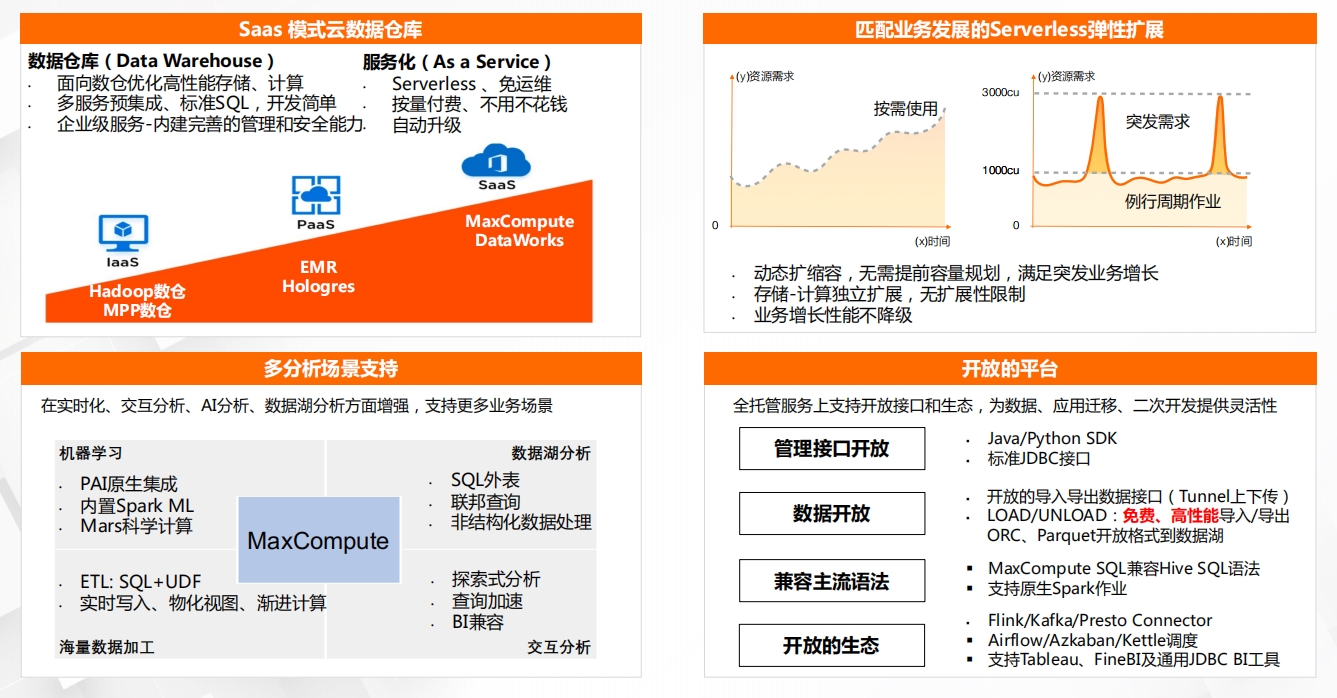 MaxCompute – 高性能、低成本、高稳定性
MaxCompute – 高性能、低成本、高稳定性 MaxCompute – 企业级安全
MaxCompute – 企业级安全多租户体系下企业级可信赖的数据管理平台-MaxCompute拥有全面的安全管理机制,提供业界领先的安全能力

MaxCompute 某保险集团基于MaxCompute大数据平台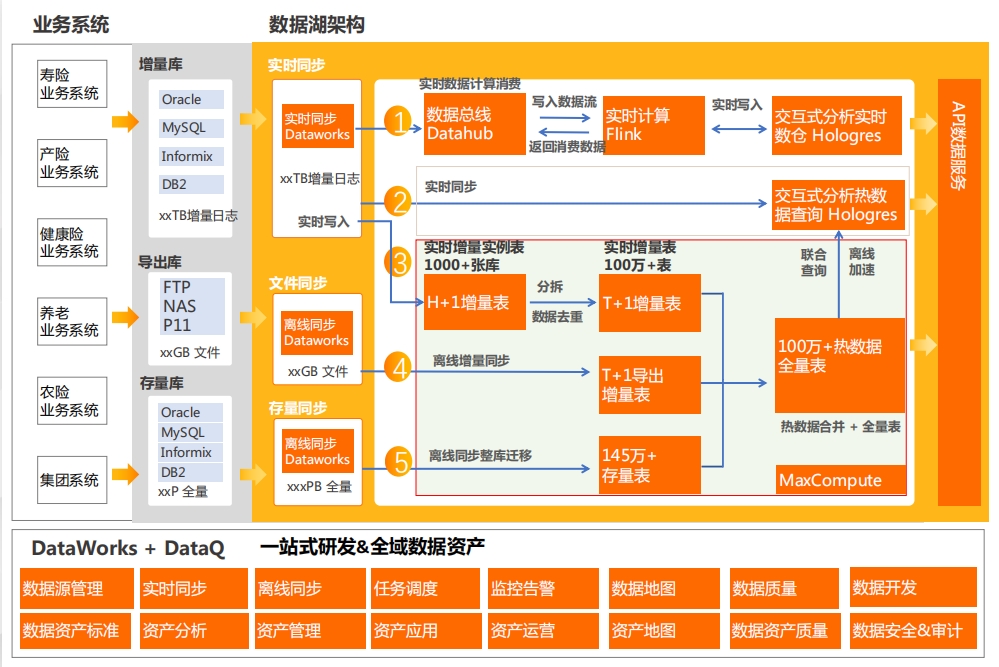 MaxCompute - 产品组合
MaxCompute - 产品组合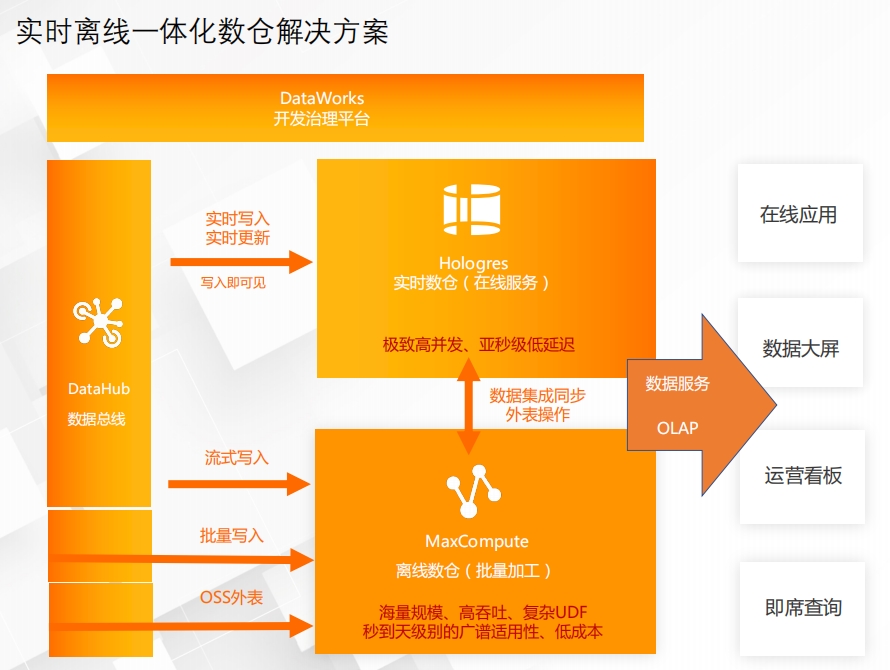 MaxCompute - 产品组合 湖仓一体解决方案
MaxCompute - 产品组合 湖仓一体解决方案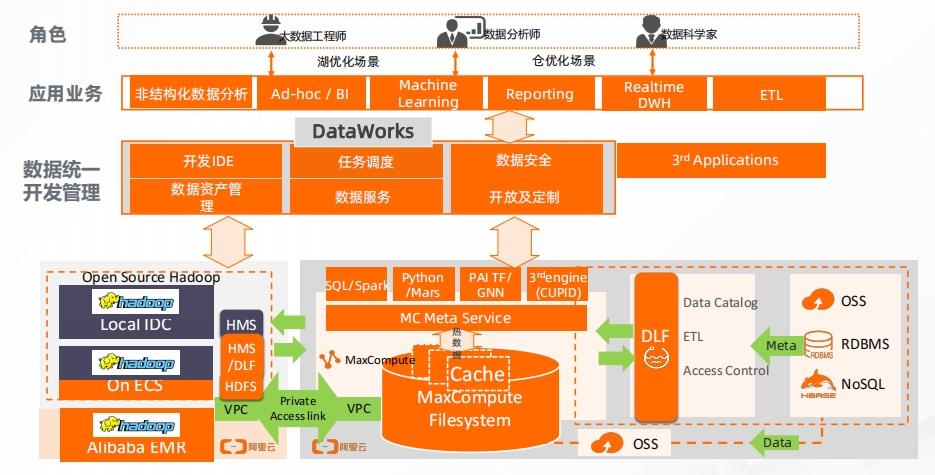 MaxCompute 某知名互联网社媒公司通过湖仓一体实现大数据
MaxCompute 某知名互联网社媒公司通过湖仓一体实现大数据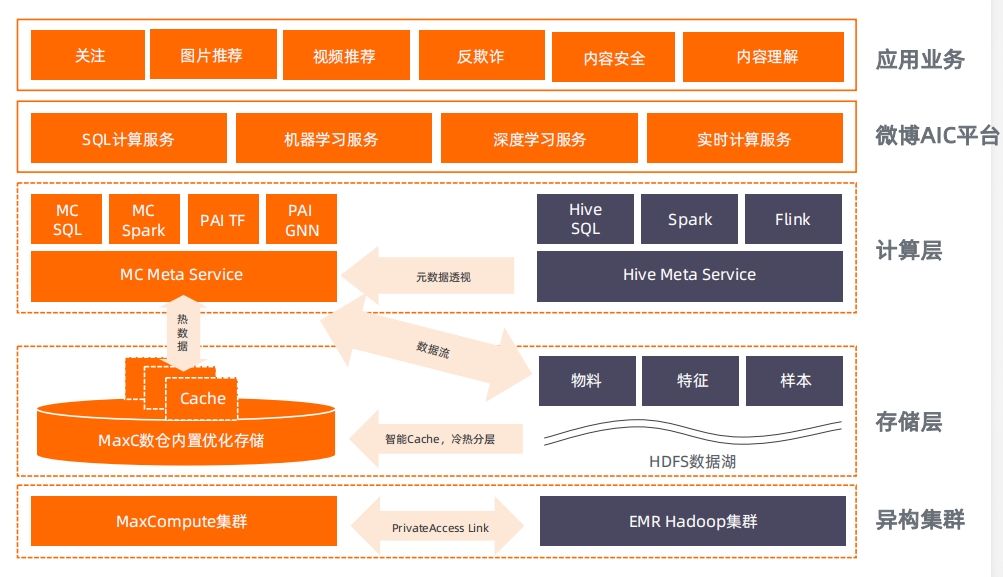 MaxCompute 某互联网金融客户基于MaxCompute实现用户
MaxCompute 某互联网金融客户基于MaxCompute实现用户
阿里云AIoT智慧门禁,云端能力硬件化,提供集成安全管理、健康码等能力的智慧门禁产品,端到端服务客户。通过集成门禁服务SDK,植入阿里云IoT的云端能力,硬件形态落地高性能服务。阿里云通行SaaS提供管理端、用户端标准的管理台与APP端,满足通用需求的场景。
云&端一体
口罩识别
灵活布控
“证码脸”三合一
RocketMQ诞生于阿里内部核心电商系统,主要为业务系统提供异步化、低延迟、业务解耦、削峰填谷、异构数据复制的能力。功能多样,高性能,高可靠容灾,可观测运维,帮助业务系统完成高价值数据传输和驱动。解决CDC增量同步、顺序交易撮合难题,解决分布式定时调度难题。
异步化
业务解耦
可观测运维
削峰填谷
阿里云数据库Redis/Tair,通过对硬件信息,带外信息和信号综合探测,准确快速识别真正的异常状态。避免慢查询对心跳ping的干扰,触发误切换动作。 可配置开启多db的支持,更好的兼容集群架构升级。Slot迁移解决相同slot多key命令迁移期间失败问题。
精准探活
Slot迁移
兼容性
多db支持






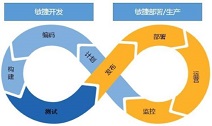



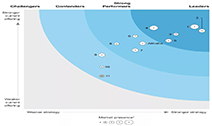




领先的企业数字化服务平台
客服电话:400-0972-788

