
硬核干货 | 揭秘TDSQL国产数据库新敏态引擎Online DDL技术原理
来源: 云巴巴 2021-12-27 13:54:59近日,TDSQL新敏态引擎重磅发布。该引擎可完美解决对于敏态业务发展过程中业务形态、业务量的不可预知性,实现PB级存储的Online DDL,可以实现大幅提升表结构变更过程中的数据库吞吐量,有效应对业务变化;其独有的数据形态自动感知特性,使数据能根据业务负载情况实现自动迁移,打散热点,降低分布式事务比例,获得极致的扩展性和性能。
与此同时,TDSQL 新敏态引擎还具有对分布式事务完整支持的特性,支撑了上层计算引擎多主读写架构的实现,并与计算引擎结合实现了计算下推、分布式事务一阶段优化等多维度优化,进一步实现分布式数据库系统性能极致提升,有效适配企业新敏态业务需求。在腾讯内部业务实践中,TDSQL新敏态引擎可支撑业务在保持高性能且连续服务的基础上,一个月内完成高达1000次表结构在线变更。
在高频的表结构变更过程中,如何减少对在线业务请求的影响,甚至使得用户能够以原生、不阻塞业务的方式进行,这就成为了TDSQL新敏态引擎面对的技术挑战。本期将由腾讯云数据库高级工程师赵东志,为大家深度解读TDSQL新敏态引擎OnlineDDL的原理与实现。以下是分享实录:
Instant DDL
下图所示为TDSQL新敏态引擎的核心架构。SQLEngine是计算层,主要负责SQL的解析、分发,包括数据查询,将SQL转为KV,再将KV收集的结果转化为SQL能获取到的结果,最后传输到客户端等环节。其中,DDL也是计算层负责的部分之一。
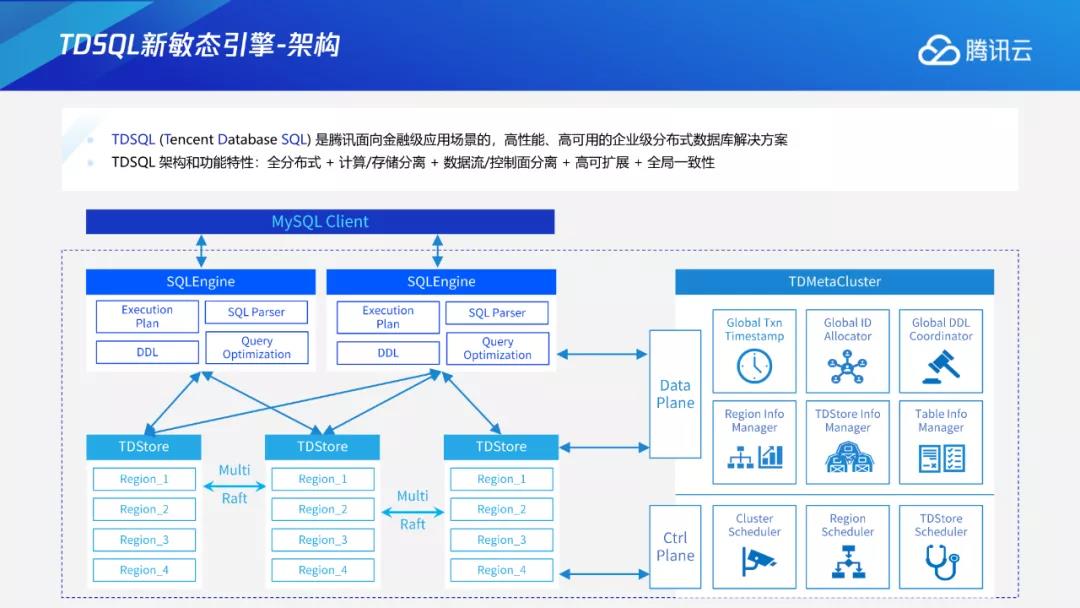
过去在单机系统下DDL的执行方式分为两种:MySQL对支持的部分Online DDL,不支持的部分则通过外部组件pt工具对每个DB节点做DDL。在集群规模比较大时,运维会变得更加复杂,需要用外部工具保证多个节点之间DDL的原子性,每个节点还需要预留两倍存储空间。
基于上述原因,TDSQL新敏态引擎的设计目标定为三个方面:
-
保证Online性质,做到不阻塞业务读写请求。
-
保证多节点缓存一致性,使得Crash-safe等在TDSQL系统中自治。
-
兼容MySQL,方便业务迁移。
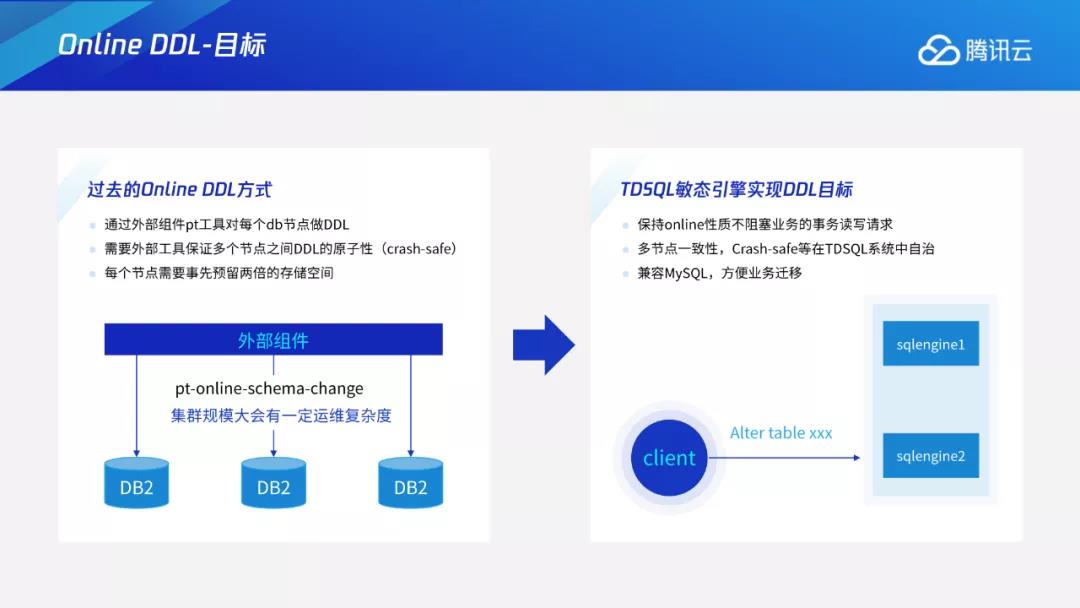
我们以加列为例来介绍Instant DDL。下图中的Client,包含一个表结构,是一条映射语句。在F1列的基础上,插入一个pk=10、F1=1的数据行。插入后再进行加列操作,加入F2列,加列后的表如下图TDstore所示。这时如果需要读取前述两行数据,就会遇到问题。在读取pk=11这行时,可以用最新的表结构直接解析数据行,但在读取pk=10这行时,我们需要知道该数据行里是否包含F2列。
为此我们在表结构中引入版本号概念。比如初始列表的版本为1,做加列操作后,schema变为2,插入时再将版本2写入到value字段中。读取数据时需要先判断数据行的版本,如果数据行版本为2,就用当前的表结构解析;如果数据行版本为1,比当前版本小,确定F2列不在该版本的schema中后,可直接填充默认值再返回到客户端。
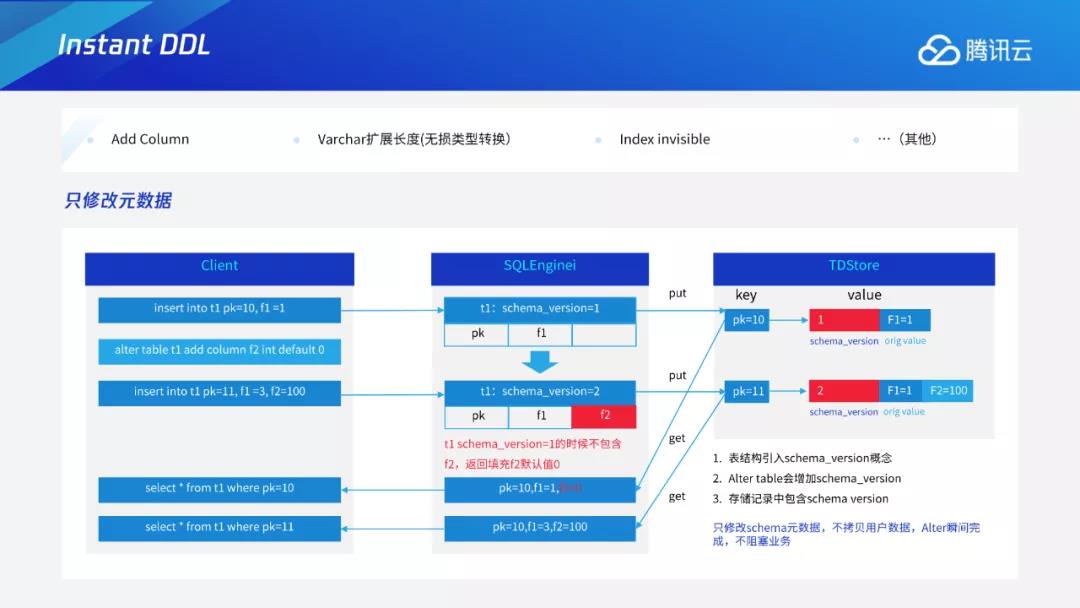
通过版本号概念的引入,在整个加列过程中,只需要更改元数据,即schema的信息并未更改数据行,加列过程变得更加快速高效。同样的方式也可作用于Varchar扩展长度等无损数据类型的转换,Index invisible等其他DDL。但并不是所有的DDL都可以仅修改元数据,部分DDL还需要生成部分数据才能实现,比如加索引操作。因为索引的生成是从无到有的过程,因此必须要生成部分数据,无法通过直接修改表结构来实现。
Add/Drop Index
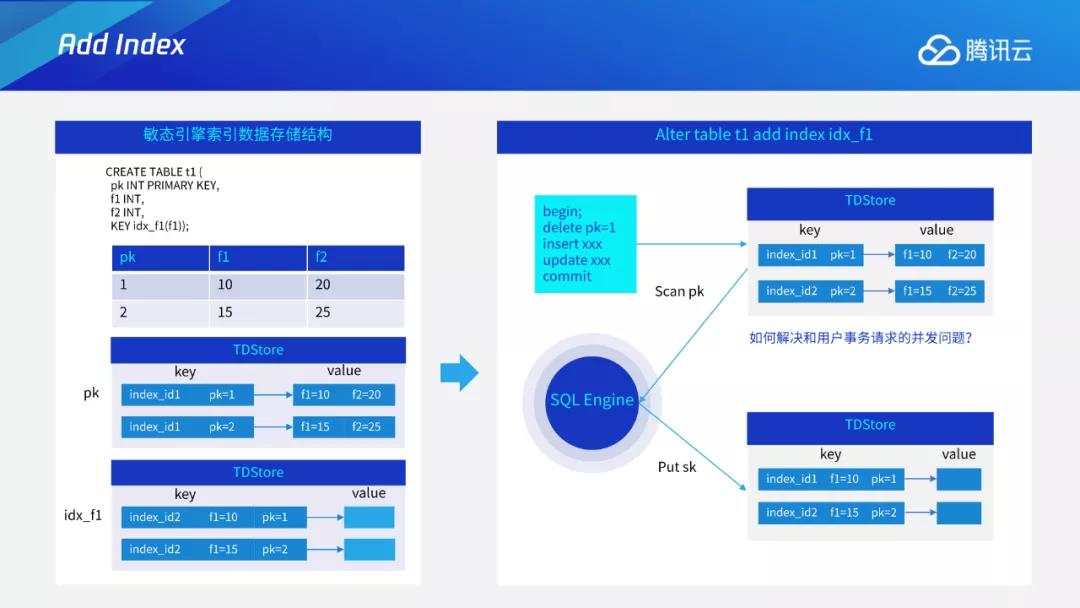
以加索引为例,下图左边所示为TDSQL新敏态引擎索引数据库存储结构。图中有两行数据,有一个主键和一个索引。在TDStore中,每个索引都会有全局唯一的index ID,比如主键为index1,二级索引为index2。主键数据由index ID+pk组成,形成key,value为其他字段。在索引中,它的组成为索引indexID+索引信息+主键信息。
如果要进行alter table、add index操作,从无索引状态变为索引,则需要扫主键数据,组建索引的KV形式,插入index中进行扫描,再修改元数据,以完成索引的添加。如果在扫描主键、修改元数据的同时,存在并发事务如delete或insert等操作,就会产生扫描回填的索引过程与用户事务并发之间的问题。
针对DDL和用户请求的并发问题我们可以将DML分为delete、insert、update三种来加以讨论。
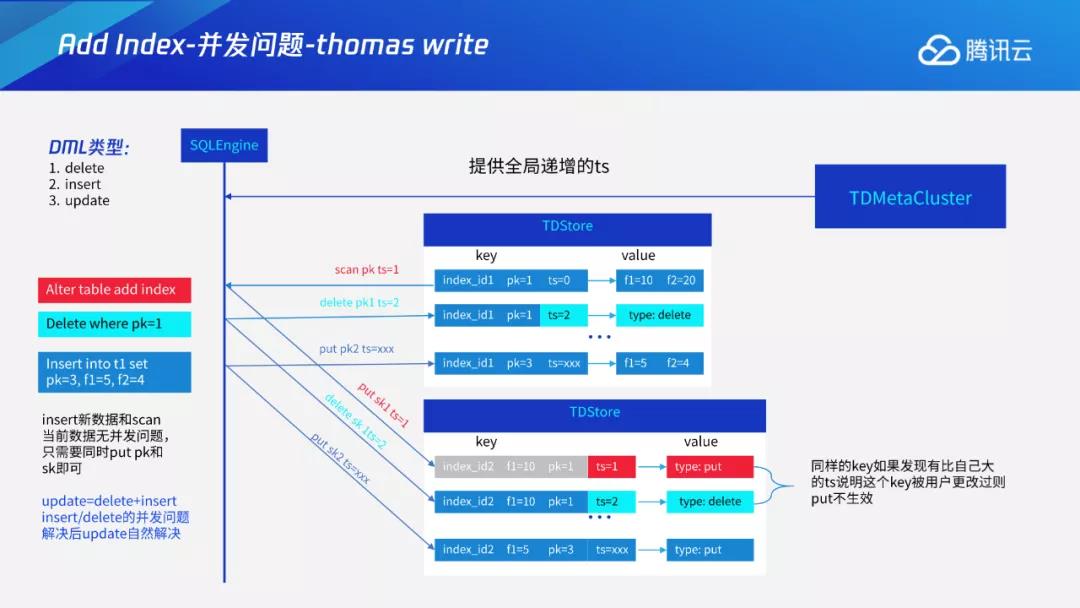
对于delete,我们可以scan任意一行数据,再按索引形式将其插回到TDstore中。假设存在一个并发,两数据行为同一行,删除操作相当于插入一个类型为delete的key。目标是在主键上删除该数据行,在索引上也删除该数据行。如果不计后果直接插入,就会遇到问题。比如删除后,又插入到该数据行后,最终的结果是,key被删除后在索引上再次出现。
为解决上述问题,我们引入了托马斯写机制,在插入时先查看版本,看是否存在更加新的写入,如果有更加新的写入,则该条key就不能再被写入。这里采用时间戳的比较机制。在scan时,基于TDStore提供的全局一致性读,我们在读取时会获取一个时间戳,比如1。在事务中插入时,其时间戳也通过TDStore来获取,读取数据所用时间戳也会带进去,即在该时间戳读,写时也用同一时间戳,TS为1。在同一条key中,如果发现存在比自己更大的ts,说明该key已被用户更改过,则put不生效,以此来解决并发问题。
对于insert,如果插入一条新数据,与当前数据行无冲突,即当前数据行无该条数据,这时只需要在索引上也插入该行数据即可。update相当于delete+insert的组合,在delete和insert问题解决后,update问题也会自然解决。我们通过托马斯写规则机制解决回填索引与用户事务的并发问题。
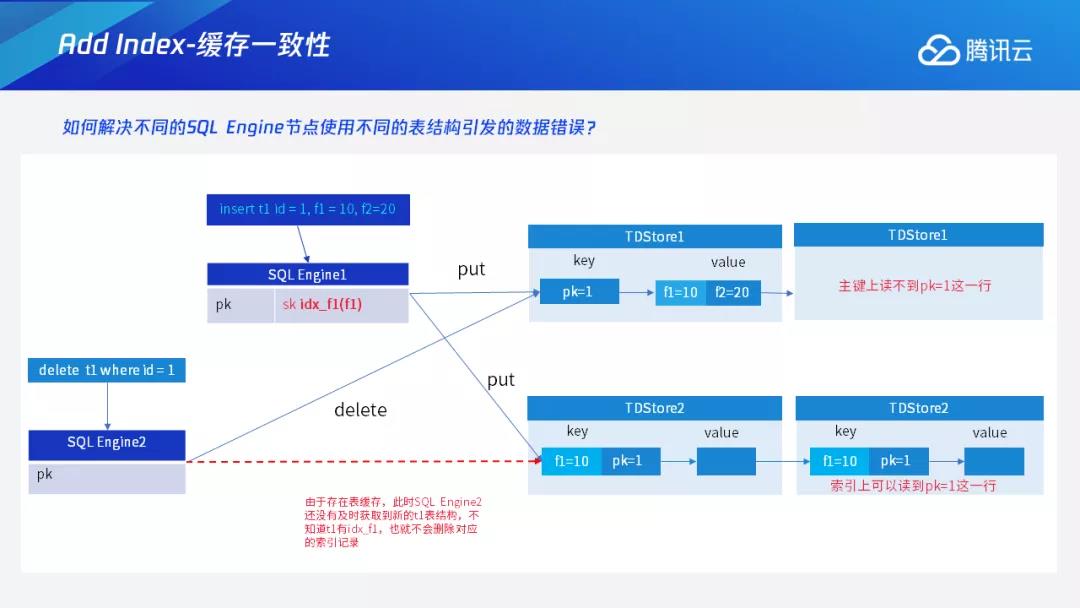
在分布式系统中我们还会面临另一个问题,即多个计算节点之间的缓存一致性问题。因为在TDSQL中,上层计算节点可以有很多个,且每个计算节点还会有自身的缓存。以索引为例,假设某个DDL在SQLEngine1上执行一个add index idx_f1,此时SQLEngine1上并发的执行一个插入操作,则会在主键,索引上分别插入一行kv,如果这时另一个计算节点SQLEngine2由于缓存更新不及时,获取到的表结构没有idx_f1,如果接到删除请求,在解析完该表结构后,该计算节点只会删除主键上的数据,而不会删除该条索引记录,最终导致主键上和索引上的数据不一致。
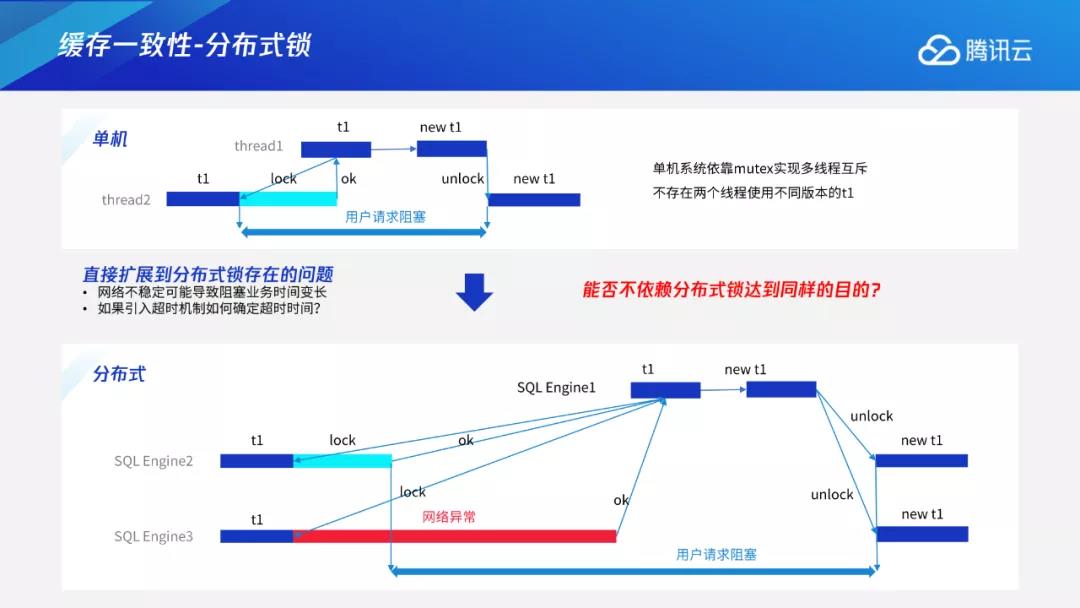
单机系统一般不会出现上述问题。假设将两个节点想象成两个线程,比如thread1、thread2,线程1想要进行表的元数据修改,可以获取一个的元数据锁,将所有的请求先挡住,再到内存中的表结构。可以看出单机系统依靠mutex可以实现多线程互斥,不存在两个线程使用不同版本的t1的情况。
一个简单的想法是将单机系统中的锁扩展成分布式锁。这种做法在原理上可行,但会存在时耗不可控的问题。以下图为例,假设sqlengine1想发起申请锁的请求,它可以在自身节点申请,也可以在其他节点如sqlengine2、sqlengine3上申请。但由于分布式系统中网络不太可控,sqlengine数量非常多,可能会存在网络异常问题,比如sqlengine3存在网络异常,回复时间就会比较慢。网络时间的延迟导致不可控问题。如果等到所有节点都申请成功,再去做更改,用户请求的阻塞时间就会被拉长。
分布式锁的实现还有很多方案,比如引入超时机制,但同样也会存在其他问题,例如超时时间定义为多长?太长对用户业务会有影响,太短则可能存在误判。我们进一步思考,能否不依赖分布式锁达到同样的目的。
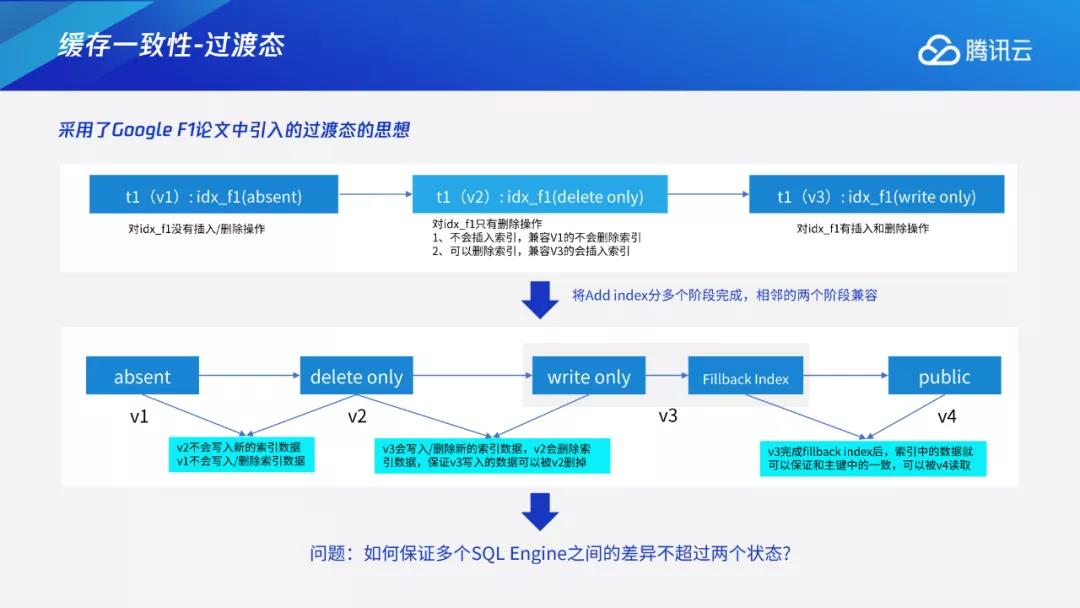
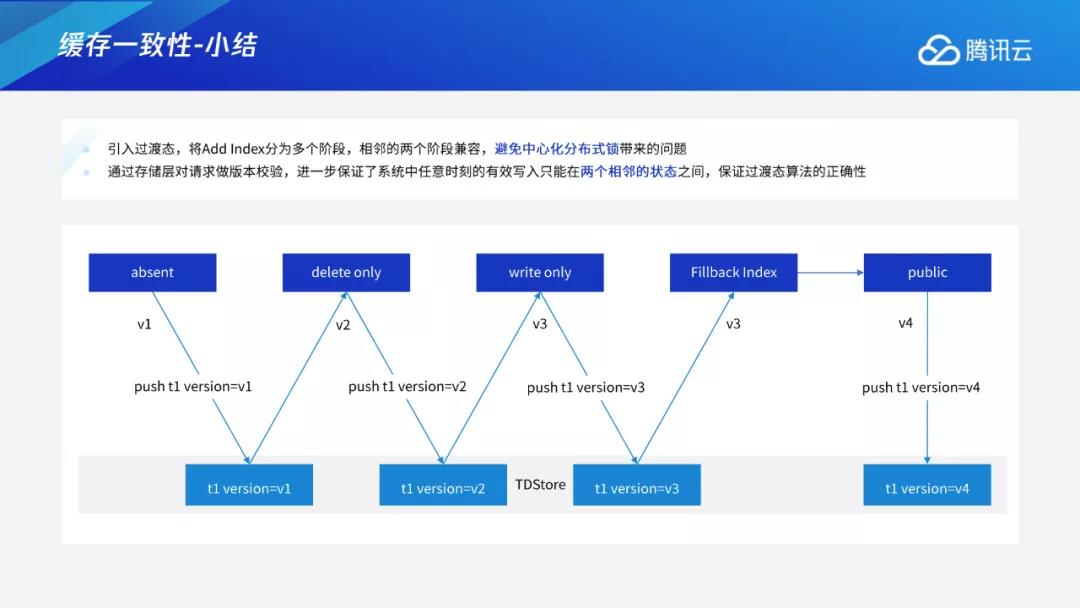
我们采用GoogleF1论文中引入的过渡态的思想。前述问题出现的原因是有的计算节点无法感知到该索引,有的计算节点感知到该索引并去写索引,这就产生了数据不一致问题。F1的基本思想是在分布式系统中,在没有锁的情况下,无法同时从某个状态迁移到下一个状态,这时就可以引入中间状态。比如某个节点可以先进入到下一个状态,但该状态与上一个状态相互兼容。如图所示,假设目前为v1状态,先进入v2,但v2与v1可以兼容,相当于还有部分节点处于v1状态,两者可以并存一段时间,等所有节点都进入v2后,再进入v3,状态两两兼容,最终推进到完整的过程。但如何保证两两之间不超过两个状态也成为了一个新的问题?假设有个节点1先进入到v2,节点2在v1,过段时间后节点1想进入v3,但要如何确定是否所有节点都进入v2呢?
F1中还提到lease机制。假设sqlengine是一个执行DDL的节点,如果想进入下一个状态,就需要等2t的时间。所有sqlengine节点,每隔一个t周期,都会看自己的schema是否过期,如果过期就会重新加载,通过2t和t的交叉,保证推进时其他节点必定将新schema加入进来。如果部分节点加载不上来出现异常,就会主动下线。但如果单纯的lease还是不可靠的。
比如在下图中,节点1间隔2t时间进入v2,再间隔2t进入v3。假设节点2在v1时进行put key操作,但该请求在存储层面执行的时间较久,刚好遇到了io 100%,阻塞时间较长,比如阻塞5T的时间才把请求写下去。这时存在一个节点,在间隔2t后误以为其他节点都已经进入新状态,因此进入到v3。这就违反前述规则,即同一时刻不能有两个相邻版本以外的写入并存。即使v2知道自身超过lease选择主动下线也没有用,因为写入请求已经发到存储层,该写入的生命周期已经由存储层来控制。对于上述问题,F1中也提到可以引入deadline时间来控制,但是目前我们并没有这种机制,而是采用了一种版本判定机制来解决这个问题。
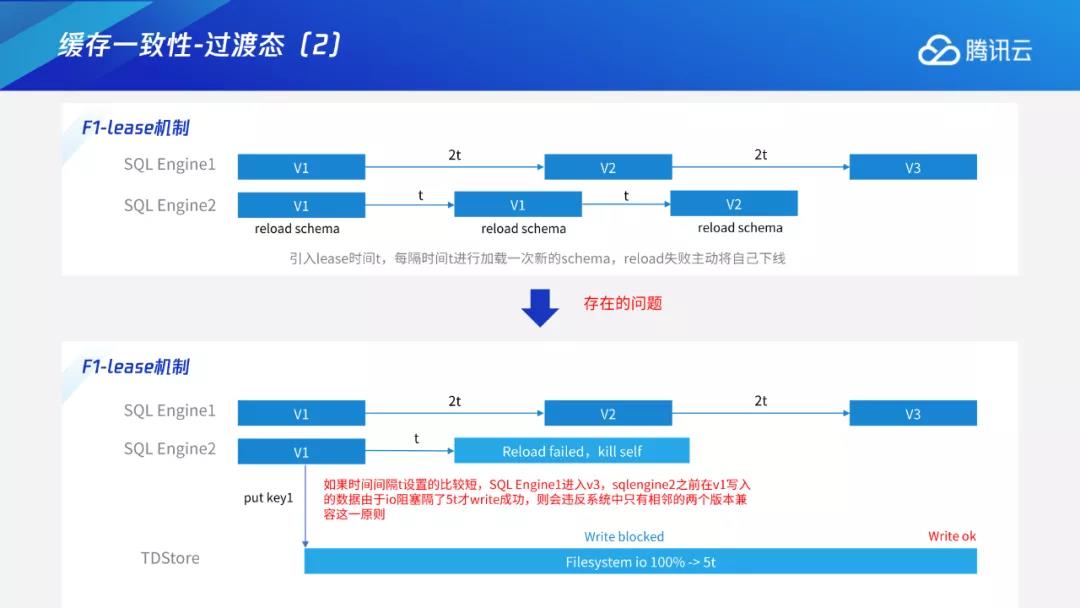
从本质上来看,这个问题属于计算层与存储层联动的问题,因为该请求已经发到TDStore,我们需要在推进版本前让TDStore感知到相关情况,具体流程如下:在进入下一状态前,需要先推一个版本下去。推下去后,存储层会感知到该节点想要进入v2。与此同时,存储层发现v1状态下还有一个请求未完成,等该请求写完后存储层再返回同意。如果存储层中一旦存在旧版本请求没有完成,它会等到完成后再反馈。
在这种约束机制下,只要push版本成功,说明存储层里已经没有比v2更小的写入,即此时任意节点都没有过期版本正在写入,可以进入v3状态。同时在该机制下,存储层不会接受后续请求中比v2小的读写请求。在极端异常的场景中,假设某一节点在push已经成功的情况下,发送仍处于v1状态的请求,这时存储层就会发现该请求比当前版本的v2要小,只能拒绝。通过存储层的版本校验机制,进一步保证了系统中任意时刻的有效写入只能在两个相邻的状态之间。
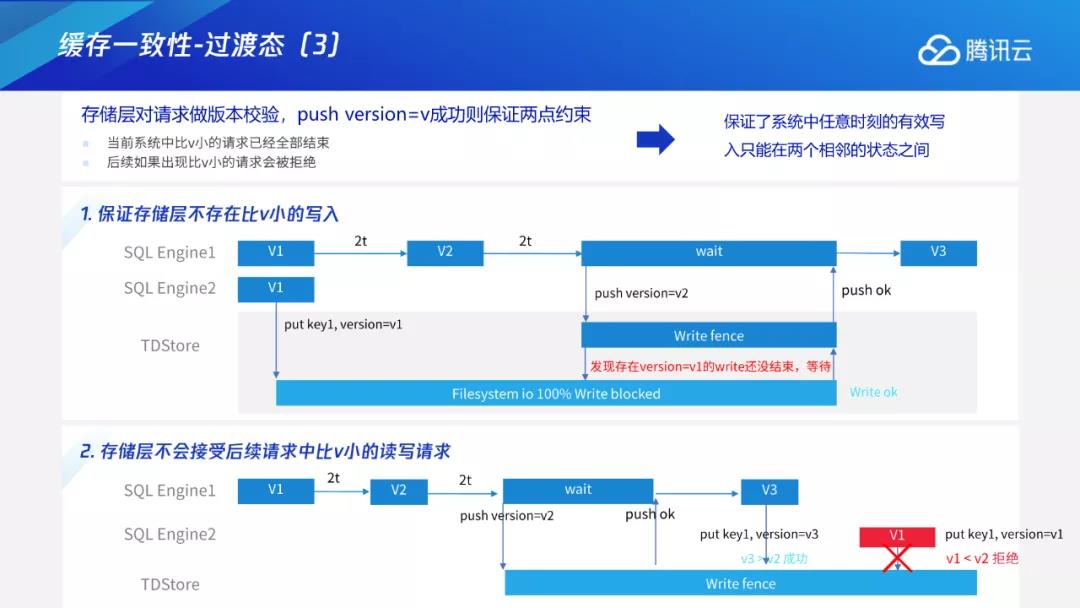
最后对缓存与执行进行总结。我们采用F1的思想引入过渡态,将Add Index分成多个阶段,每相邻的两个阶段两两兼容,这样就无需依赖全局的分布式锁。在存储层进行该版本的有效性检验,进一步保证每时每刻的有效写入只能位于两个相邻状态之间。大多数情况下,我们可以认为该版本检验无效。因为每个节点都能加载新的表结构,且能用新的表结构进行读写,版本检验仅适用于预防阶段场景,为防止此类极端场景对数据造成一致性的破坏,保证整体算法运行的正确性。整体过程为:由计算层直接向下推送版本,演变为先向TDStore push当前版本,再进入下一状态,通过此类方式来完成整体的变更操作
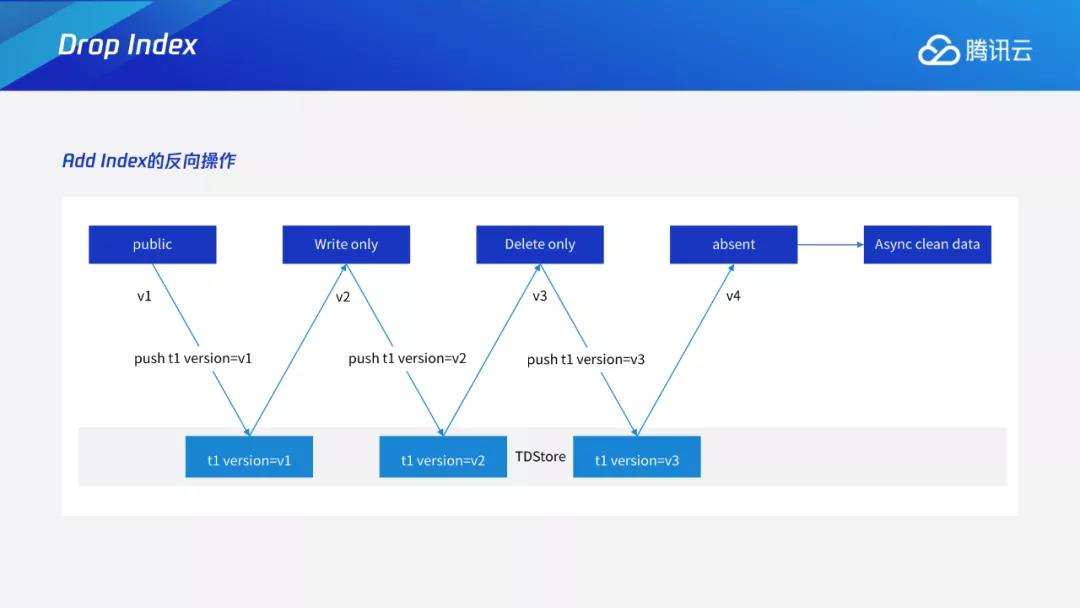
删索引则相对容易,可以看成加索引的反向操作,具体过程如下图。
通用Online DDL
在Instant DDL中,仅需更改表结构、修改元数据即可。在Varchar扩展长度等无损数据类型的转换中,还需要生成部分数据才能实现。要如何使得更广泛的其他DDL通过Online方式执行,这就成了新的挑战。
为此我们结合了pt-online-schema-change的思想。pt的原理为:在执行OnlineDDL时,会生成一个新的表结构即临时表,再将旧表数据拷贝到新表中,过程中还会进行建触发器等操作,保证拷表过程中的增量同步。在TDSQL新敏态引擎的设计中我们借鉴了上述拷表思想。拷表过程中的新表的过程可以想象成在原表上加一个特殊的索引,即回归到托马斯写问题,针对拷表过程中的问题我们也设计了过渡态问题的解决方案。
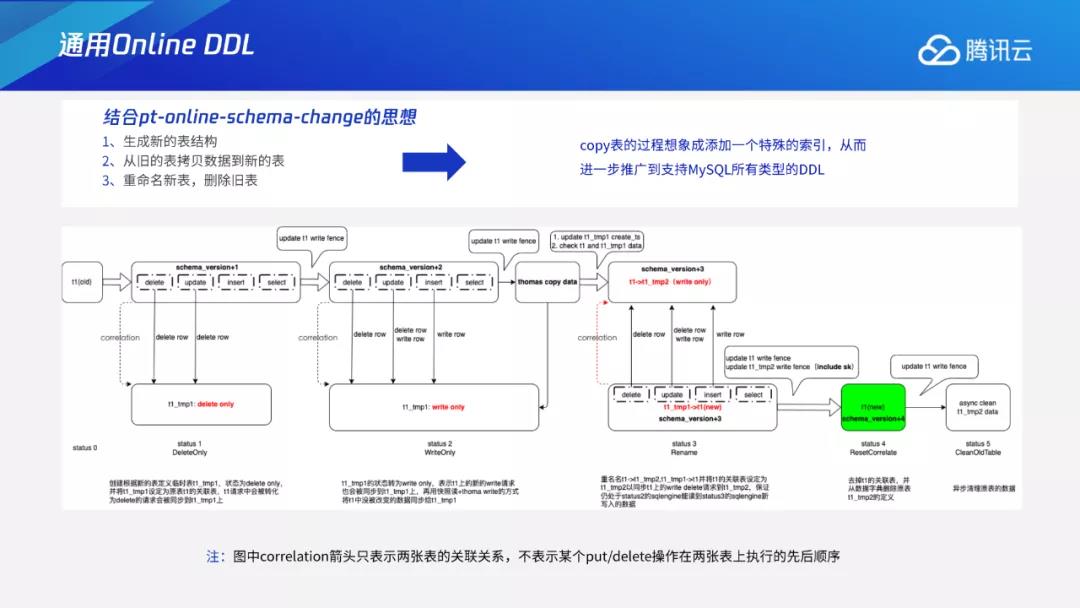
以上图为例,图中的旧表为status0,建立一张临时表为tmp1,状态为delete only。我们会在内部建立一张新表,将旧表与新表进行关联,并且会将表status0上的删除相关的操作同步临时表tmp1,接下来进入write only状态。write only的过程与加索引过程相同,会在执行过程中将delete、update、insert等新的增量同步到tmp1上。
准备开始thoma write回填数据之前,需要在存储层推版本,确保当前没有处于delete only状态的节点,保证任何新的请求都会增量同步到新的临时表中。之后再进行thomas write操作按照加索引的方式,从MC获取时间戳,再用时间戳扫数据,从老表上将旧数据回迁到新表,thomas write机制可以保证整体回迁过程与原表事务并发的正确性,最后再进行临时表命名。
在此之前,我们还会进行其他的检查操作,比如检查旧表与新表数据的一致性。因为在这种拷表方式中,如果alter影响到主键,就容易引起数据方面的问题。假设原表的主键为一个Varchar,属于大小写敏感类型,上面有A和a两条数据。如果变更字符序,将其变为大小写不敏感,在新表中A和a就会变成一条数据,从而覆盖掉原始数据。我们需要通过类似的二次检查来确定是否存在该种情况,避免拷贝过程中的数据遗失。
检查完成后,我们会进行rename操作,更改旧表表名,再将新表替换成原表表名,相当于将整个原表替换到新表的状态。我们还会进行反向同步操作,因为可能有部分节点仍处于status2,此时原表上还有读请求,我们需要将这些请求转发到这张表上,保证处于该状态的计算节点仍能读到这些新增的数据请求。在这些请求转移完成后,再取消关联,将版本推掉,最终将旧表用异步方式进行清理。
结合pt-online-schema-change的思想,我们将拷表的过程想象成添加一个特殊的索引,从而进一步推广到支持MySQL所有类型的DDL。
Online DDL原子性
在TDSQL新敏态引擎中,所有计算节点为无状态,持久化操作通过存储层来实现,DDL的发起操作则在计算节点中进行。如果某一计算节点在执行DDL过程中挂掉,就会面临中间状态由谁来负责推进的问题。
实际操作中,每个计算节点在执行前,会在存储层持久化一个DDL任务队列。每次开展DDL任务时,就会将该DDL任务插入到DDL任务队列中。如果正常结束,就会将该任务删除。如果非正常结束如异步挂掉,其他的计算节点,会感知到任务队列中有未完成的任务,根据该任务当前执行信息,再去界定该DDL任务的下一步操作,例如继续推进或回滚。
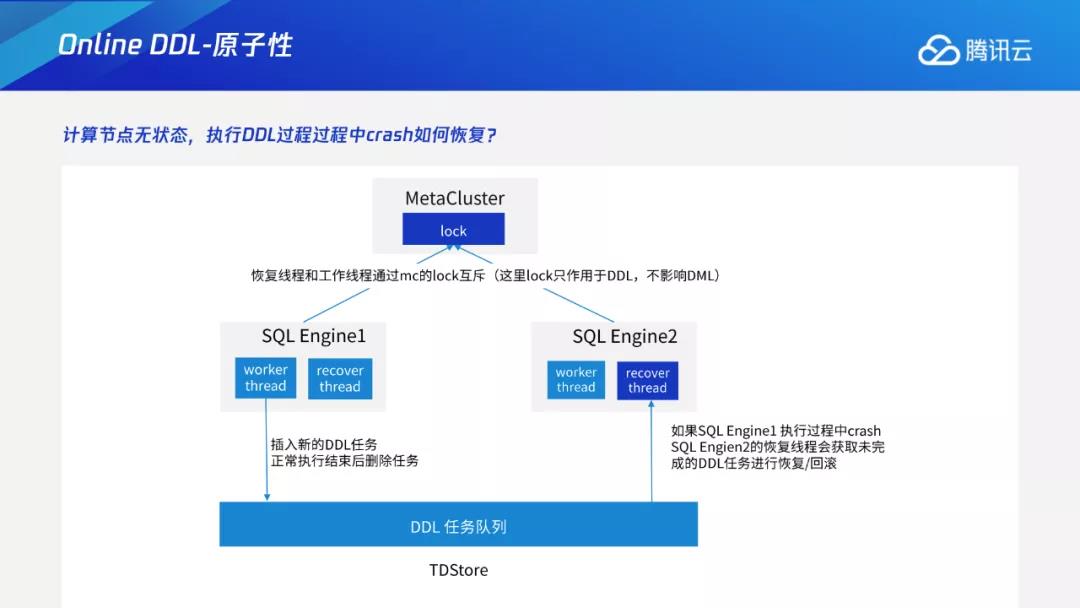
在上述过程中,恢复线程与工作线程之间通过MC的lock来互斥。这看似引入了分布式锁,但实际上该锁只作用于DDL之间。因为TDSQL新敏态引擎的整体设计原则是DML优先,在DDL过程中尽量避免影响DML。
总结
综上所述,TDSQL新敏态引擎Online DDL核心技术可以总结为四个方面:
-
Instant DDL:通过多版本的解析规则,使得加列或varchar扩展长度等无损类型变更这些只需修改元数据的DDL瞬间完成。
-
Add/Drop Index:通过托马斯写机制,解决生成索引数据和用户事务的并发问题;采用F1过渡态+存储层版本交验机制,解决多个节点间缓存一致性问题。
-
通用Online DDL:抽象出适用于所有DDL的copy table流程,进一步将Online DDL推广到可支持绝大多数MySQL的DDL。
-
DDL原子性:通过任务队列+恢复线程的工作机制,保证DDL整体的原子性。
 更多产品了解
更多产品了解
欢迎扫码加入云巴巴企业数字化交流服务群
产品交流、问题咨询、专业测评
都在这里!

为你推荐
分布式数据库区别于其他数据库的整体架构
随着全球市场经济下行压力不断增大,中美服务贸易摩擦愈演愈烈,美国通过一系列的经济制裁和技术封锁使得我们有种被扼住咽喉的感觉。数据库管理作为一个基础软件中的重要一环有着很深的技术含量,在这样的大背景下国产数据库厂商开始发力。2020-04-16 17:47:56

面对大时代机遇,国产新型数据库应该怎么做
过去30年,数据库方面Oracle、IBM、Microsoft三足鼎立。面对三家垄断的局面,传统国产数据库可谓生不逢时。虽然产品不时进步,但是由于技术方面仅仅是跟在别人后面学习,因此大多产品处于非中心应用的尴尬地位。虽然政府也给予了支持,2020-04-20 17:31:41

【科技早知道】腾讯云市场份额第二;华为IdeaHub集结云会议伙伴;达观数据建实验室
每周科技早知道。腾讯云市场份额第二;华为IdeaHub集结云会议伙伴;达观数据建实验室。2022-03-31 19:37:00
分布式数据库数据分片、分配、体系、系统问题
我们来聊聊分布式数据库数据分片、分配、体系、系统问题: 数据分片 类型: 第一、横向分割:根据特定的条件中的多个元组成不相交的子集之间的关系的全球发展,其中,每个子集是显著段关系的所有数据。2020-04-17 19:41:30

深入解读腾讯云数据库自研内核
TXSQL 是腾讯云数据库团队自研 MySQL 内核分支,100%兼容原生 MySQL 版本,针对企业级的重要场景自研众多核心特性,如企业级透明数据加密、审计、线程池、热点更新保护、SQL 限流、快速加列等功能2022-02-24 10:24:34

严选云产品









领先的企业数字化服务平台
客服电话:400-0972-788


评论列表