
智能文档处理技术揭秘:如何低成本实现高准确率的文档信息抽取?
来源: 云巴巴 2021-12-17 11:29:14导读
智能文档处理(Intelligent Document Processing ,简称 IDP )是来也科技智能自动化平台的核心能力之一。IDP 基于光学字符识别(OCR)、计算机视觉(CV)、自然语言处理(NLP)、知识图谱(KG)等前沿技术,对各类文档进行识别、分类、抽取、校验等处理,帮助企业实现文档处理工作的智能化和自动化。
IDP 最常见的应用场景之一是从各种类型的文档中抽取关键信息,本文介绍机器学习在文档信息抽取中的应用。对 IDP 产品及更多应用场景感兴趣的读者,可点击文章开头的话题#智能文档处理#。
背/景
企业中存在大量需要从文档中抽取信息并进行处理的业务场景,例如从发票、报销单、发货单等不同类型的文档中抽取所需字段,进行录入、校验、比对等操作。因此,文档信息抽取是智能文档处理平台的核心能力之一。通常情况下,文档信息抽取需要用到机器学习技术。我们知道,训练一个机器学习模型需要一定规模的标注数据,在文档信息抽取任务下训练机器学习模型面临两个挑战。
第一,文档的类型繁多,即便是同一个类型的文档,其版式也可能存在多种。下面是几个中文完税证明的例子,我们可以发现,它们虽然都是完税证明,但版式差别很大,尤其体现在明细表格部分,表格的字段数量、字段顺序都不太一样。这意味着,如果使用传统的方法,需要训练多个机器学习模型才能满足不同版式信息抽取的需求。

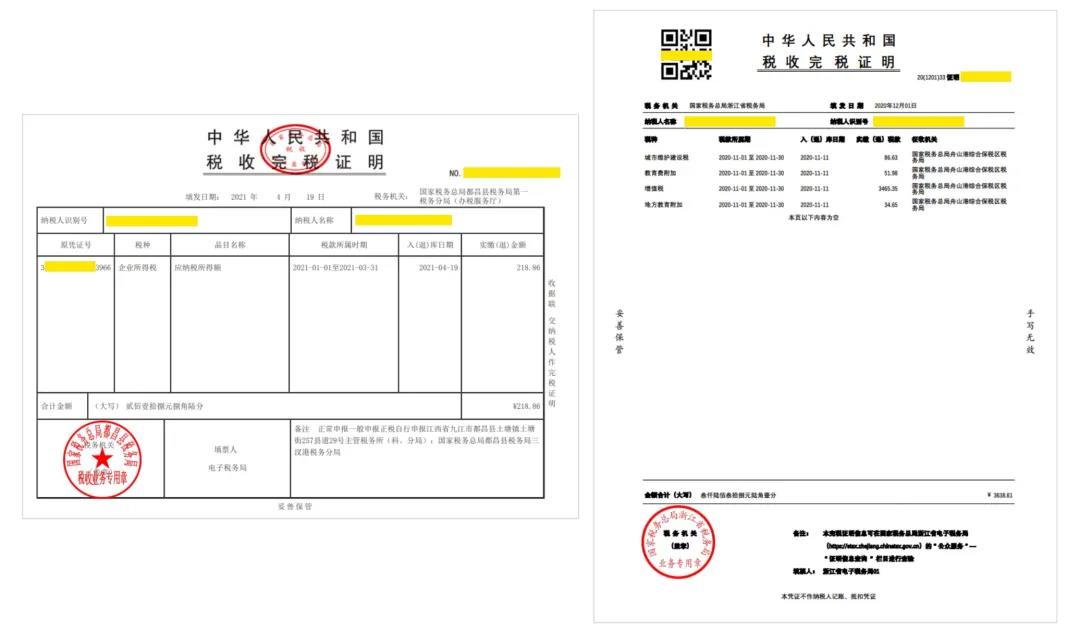
*完税证明示例(图片来源于网络)
第二,很多文档类型是企业特有的,也就是说我们很难提前收集到数据并训练好模型,而是需要基于企业特有的文档数据,在小样本下训练出可用的模型,否则模型的训练成本太高。下面是几个英文发票(Invoice)的例子,我们可以发现它们不仅版式不同,而且每一类的数量都不多。
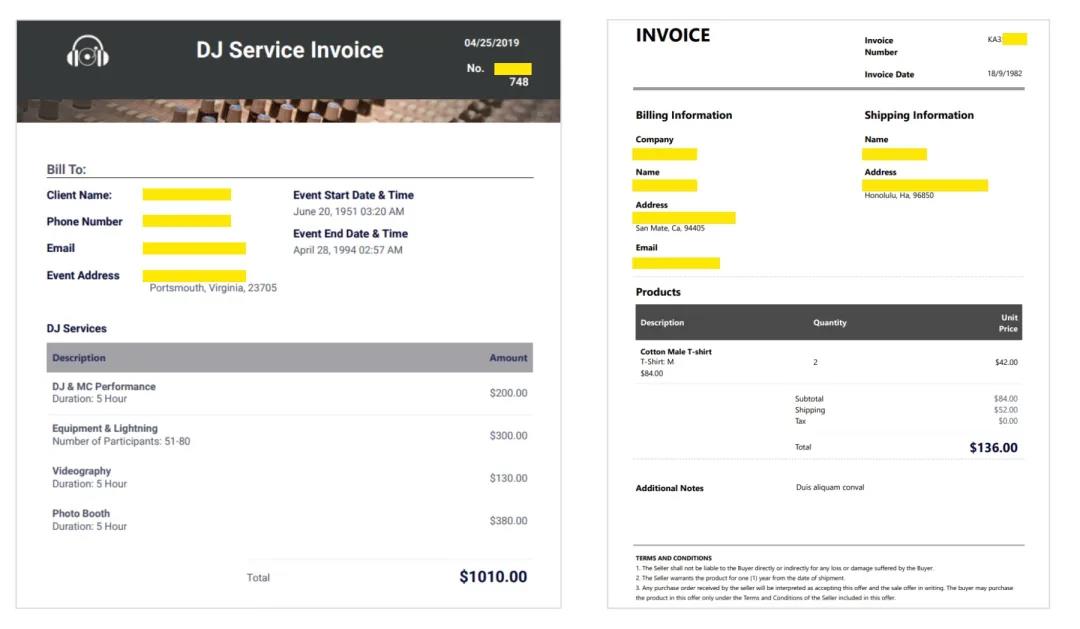
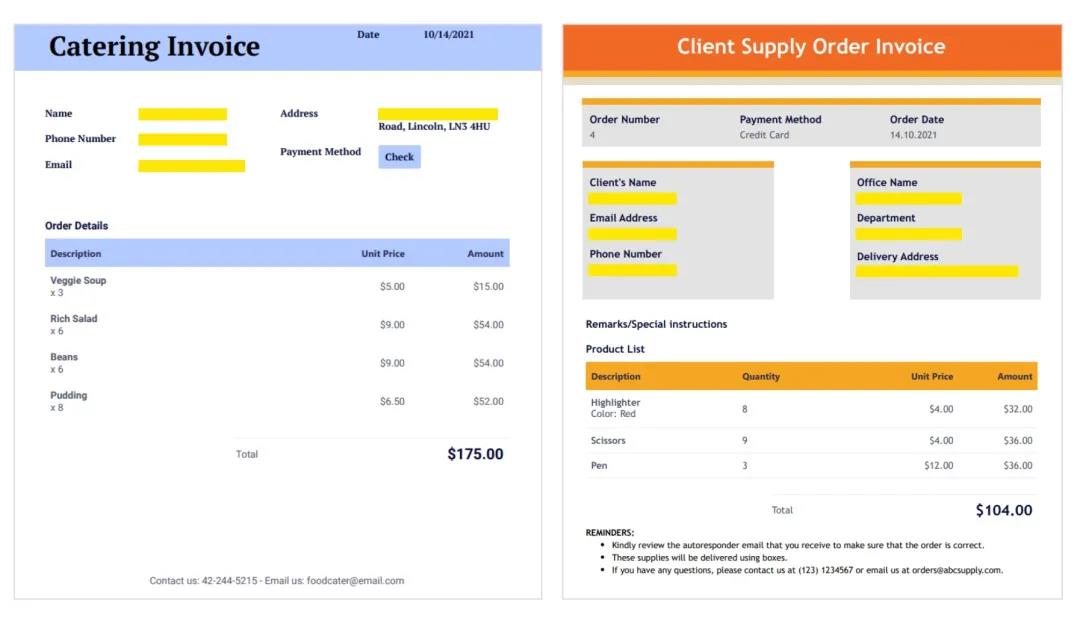
*英文发票示例(图片来源于网络)
本文中,我们介绍来也科技 IDP 平台中用到的文档信息抽取方法,该方法充分利用文档的视觉特征和语义特征,能够在较少样本的情况下训练出效果很好的模型,且具备较强的泛化能力,从而快速满足企业中多种文档信息抽取的需求。
技/术/方/案
我们的技术方案以 OCR 识别的结果作为输入,充分利用视觉和语义信息建模,在低成本(标注数据少、资源占用少)的情况下完成文档信息抽取任务。该方案将 OCR 和信息抽取完全解耦合,这样设计有两个优点:
OCR 和信息抽取相互不受影响,可以分别进行优化。
同一个 OCR 引擎可以对接不同的信息抽取模型;同理,同一个信息抽取模型也可以对接不同的 OCR 引擎,以满足不同场景下的需求。
OCR 引擎完成识别和预处理后,由三个子任务构成完整的 pipeline ,如下图所示。下面我们分别介绍。

文本块序列化
这个任务的目的是将 OCR 识别到的文本块,按正常的阅读顺序重新进行排列,解决内容折行、数据分组的问题。
如在下面的完税证明示例中,税收详情中存在较多的内容折行, OCR 识别引擎通常会按从左到右、从上到下的顺序返回。如图中所示,OCR输出的文本块的顺序为图上标识的数字(1、2、3……11),显然这个顺序既不符合阅读顺序,也会打乱语义和排版信息。如果不进行调整,会导致模型无法准确的得到正确的语义信息和结构信息。

通过上述的例子可以发现,文本序列化任务和具体文档类型基本无关,因此我们可以通过大量标注数据训练一个通用的文本块序列化模型,在其他项目中直接使用,降低项目启动的代价。以下是经过文本块序列化模型重排序后的顺序,在这个排序基础上进行一定的后处理,我们就可以还原出文档中的字段。

文本块分类
对文本块进行序列化之后,我们的下一个任务是利用文本分类的方法获得每个文本块对应的标签,即每个文本块属于哪个待抽取的字段。在这个任务中,我们将每个 OCR 输出的文本块作为独立的分类目标,利用多分类的方法获得每个文本块对应的信息标签。通过文本块的文本语义、空间位置、上下文关系、排版格式等视觉特征,使用统计模型进行建模并训练文本块分类模型。以下是文本块分类模型用到的主要特征:
语义特征:利用文本块包含的文本信息生成的特征;
空间位置:利用文本块在文档上的位置,以及和其他文本块的相对位置关系;
排版格式:利用文档的各种排版信息,如表格、列表等。
抽取结果组装
通过使用以上两个子任务的输出结果,我们就可以进行最终的抽取结果组装。以下面这个数据为例,抽取结果组装主要解决两类问题:

文本换行
如在上述完税证明示例中,税款所属税务机构这列内容中“国家税务总局”和“xx市税务局”因为换行的原因被切分为了两个文本块,我们可以依据他们有相同的分类标签(文本块分类结果)、紧邻的顺序(文本块序列化结果)、上下的位置关系,将其判定为同一个字段进行合并,得到最终的信息抽取结果:
field:税款所属税务机构;
value:国家税务总局xx市税务局。
数据关联
在完税证明的示例中,税务具体信息的多个字段是存在关联关系的,如果直接将这些字段的识别结果进行输出,会丢失其中的关系,难以在下游任务中使用。通过文本块序列化的输出结合位置信息,自动将有关联关系的字段进行组装,为下游任务提供字段之间的关系信息。上述例子经过数据关联后的最终输出为(JSON格式):

效/果/评/估
为了验证上述文档信息抽取方案的效果,我们选择了“中文完税证明”和“英文发票”两个数据集进行测试。
数据集介绍
中文完税证明
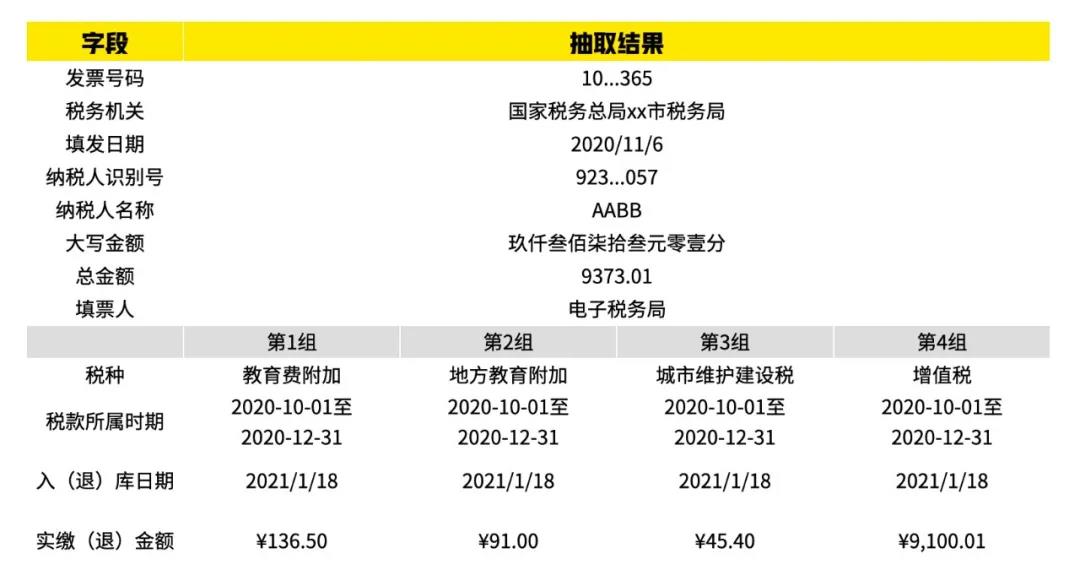
如第一节中样本所示,全国各个省市的完税证明版式存在较大差异,但待抽取的字段基本相同。我们从中文完税证明中抽取 15 个字段:发票号码、填发日期、税务机关、纳税人识别号、纳税人名称、税款所属时期、原凭证号、税种、品目名称、实缴(退)金额、大写金额、总金额、填票人、备注信息、入(退)库日期。我们共使用 12 个版式共 98 张完税证明进行模型训练,在 33 张样本上进行评测。
*以下为完税证明信息抽取输出的示例:
英文发票
如第一节中样本所示,我们从英文发票中抽取 15 个字段:发票号码、发行日期、买家姓名、买家地址、产品项目No.、产品明细、数量明细、产品单价、总额明细、税额合计、含税总额、付款方式、采购订单号、到期日、折扣合计。共使用 34 个版式共 294 张进行模型训练,在 90 张样本上进行评测。
*以下为英文发票信息抽取输出的示例:

模型整体效果
首先,我们针对上述两个数据集,分别测试模型的整体效果,即模型抽取的准确率、召回率和 F1 值。可以看到我们的方法在两个数据集上都能取得约 0.95 的 F1 值。
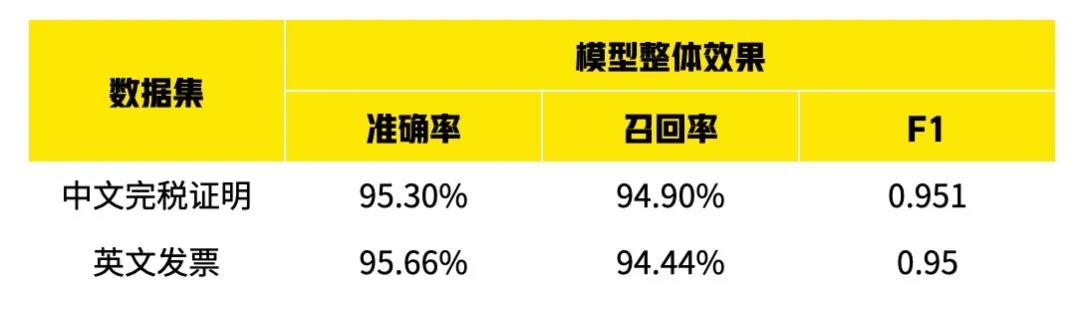
*F1 值:准确率及召回率的综合评价指标,越趋近于 1 则表明算法或模型越佳
模型在小样本下的效果
最后,我们用模型从未见过的文档来测试模型的泛化能力,并用极少量的该类文档重新训练模型,对比原模型和新模型的效果。我们在中文完税证明模型上进行上述实验,结果如下:

可以发现,在遇到全新版式的数据时,原模型的效果并不理想, F1 值在 0.5 以下。此时,我们只需要补充 5 张数据重新训练模型,就可以迅速改善模型在新版式上的效果,将 F1 值提升到 0.93 以上。这充分说明,模型有一定的泛化能力,只需原模型的基础上用极少量样本即可适应新的版式。
来也科技 IDP 平台提供强大的文档信息抽取能力,它通过使用视觉和语义信息进行建模,在处理类似发票、证件、发货单、完税证明等文档信息抽取任务时,只需极低的标注成本,就能达到非常好的效果。在遇到新数据格式带来的 badcase 时,通过少量的标注干预,即可有效的提升效果,让文档处理的自动化变得更加容易。对来也科技 IDP 平台以及文档信息抽取能力感兴趣的朋友,可点击“阅读原文”申请试用。
 更多产品了解
更多产品了解
欢迎扫码加入云巴巴企业数字化交流服务群
产品交流、问题咨询、专业测评
都在这里!

为你推荐

RPA带领企业进去自动化时代
RPA(机器人流自动化流程)既定流程自主执行任务的软件产品在AI中是我们常说机器人,重复性工作且繁杂无为的工作就是机器人诞生的原因,简称“虚拟机器人”。2020-03-18 17:19:23

干货分享,有关RPA的从加速器到加数器
在全球流行的深度打击实体经济,现在,再次给企业的数字化改造敲响了警钟,兼并和加快跨部门跨组织及数字化协同的业务流程,正在成为管理者办公桌的日常选择。 另一方面,深度植根于FSSC与CoE团队,随着应用深度与广度的不断扩展,开启了对企业数字,2020-04-29 13:27:14

Ocr识别产品都能够识别出哪些信息
不同的ocr识别产品的具体功能设置是不同的,我们需要先明确自己的需求,然后看产品能否满足您的需求才是重中之重的事情。以腾讯云的Ocr识别产品为例,来给朋友们几个ocr识别产品的功能。2022-11-24 10:13:10

关于RPA常见的误区,你知道吗?
随着RPA(机器人流自动化)的发展,RPA技术给企业带来了诸多好处。然而,围绕RPA的概念与原理,企业如何运营我们还存在着一些误会,这些误解的存在,可能会给那些寄希望于RPA技术来改变其流程管理的企业或组织带来不确定性乃至误导。2020-03-18 15:18:55

什么ocr识别产品支持各类发票识别
许多企业会因为各种开支,产生大量的发票。当我们在整理这些发票信息的时候,市教委繁琐和复杂的。但其实,现在ocr识别产品也能够支持各类发票的识别。其实不同的发票识别出的内容也不尽相同,下面就给朋友们介绍一下腾讯云的ocr识别产品都具有识别出那些发票信息的功能2022-11-24 10:01:13

AI解救“工具人”:RPA+AI,让万物皆可自动化
作为一个典型基层HR,他每天很大一部分工作,是在处理文档手续: 办入职、离职、休假申请、五险一金,扫描各类文件,在系统里录入员工信息,发邮件给各个部门…… 忙碌且枯燥的工作,日复一日过去了。看着其他部门的同事在做新产品、大项目,一本毕业的小A觉得自2022-11-21 11:03:09
严选云产品









领先的企业数字化服务平台
客服电话:400-0972-788


评论列表